Le aziende dipendono dai dati per prosperare in questo mondo digitale in rapida evoluzione. Le aziende raccolgono regolarmente diversi tipi di dati, tra cui interazioni con i clienti, vendite, entrate, dati sulla concorrenza, dati sui siti Web, ecc.
La gestione di questi dati può essere un compito arduo. E se non fatto bene, potrebbe causare un enorme errore.
È qui che entra in gioco l’orchestrazione dei dati.
L’orchestrazione dei dati ti aiuta a gestire e organizzare in modo efficace tutti i tuoi dati cruciali.
Aiuta le aziende a sfruttare la potenza dei dati e ottenere un vantaggio competitivo sul mercato.
In questo articolo parlerò dell’orchestrazione dei dati e di come può aiutare la tua organizzazione.
Iniziamo!
Sommario:
Cos’è l’orchestrazione dei dati?
Il processo di raccolta, trasformazione, integrazione e gestione efficiente dei dati da più origini è noto come orchestrazione dei dati.
L’obiettivo principale dell’orchestrazione dei dati è semplificare i dati provenienti da fonti diverse in modo efficace ed efficiente in modo che le aziende possano ottenere il massimo da questi dati. È un processo cruciale che è fondamentale nel moderno mondo basato sui dati.
L’orchestrazione dei dati ti aiuta a ottenere informazioni chiare sulla tua attività, sui clienti, sul mercato e sui concorrenti, il che ti aiuta a prendere decisioni informate e ottenere i risultati desiderati.
In termini più semplici, l’orchestrazione dei dati funge da conduttore che legge e raccoglie i dati da varie fonti di dati. Ciò garantisce che tutti i dati rappresentino la panoramica delle prestazioni della tua azienda.
Vantaggi dell’orchestrazione dei dati

L’orchestrazione dei dati offre diversi vantaggi alle organizzazioni, come elencato di seguito.
Aumenta il processo decisionale
È possibile disporre di un set di dati unificato e ben presentato tramite l’orchestrazione dei dati. Questo ti aiuta a fare scelte migliori, poiché puoi interpretare facilmente anche i dati più casuali e indecifrati con questa tecnica.
Migliore esperienza del cliente
Con una migliore comprensione del comportamento, delle preferenze e del feedback dei tuoi clienti, puoi servirli in un modo migliore. L’orchestrazione dei dati ti consentirà di impegnarti in modo mirato, portando a una migliore esperienza del cliente.
Maggiore efficienza operativa
L’orchestrazione dei dati aiuta a ridurre le ore di manodopera, che in precedenza dedicavi alla raccolta e all’unificazione dei dati manualmente. Ciò riduce gli sforzi manuali, riduce al minimo i silos di dati e ottimizza i dati automaticamente e senza sforzo.
Economico
L’orchestrazione dei dati basata su cloud offre opzioni di archiviazione ed elaborazione flessibili. Pertanto, puoi evitare costi aggiuntivi e pagare solo ciò di cui hai bisogno e utilizzare.
Vantaggio competitivo
Sfruttando le informazioni ottenute con l’orchestrazione dei dati, diventa più facile per te prendere decisioni migliori e più rapide rispetto ai tuoi concorrenti. Puoi stare al passo con i tuoi concorrenti liberando opportunità nascoste e rispondendo in modo proattivo alle tendenze del mercato.
Scalabilità
L’orchestrazione dei dati è in grado di gestire i carichi crescenti con l’aumentare del volume dei dati. Pertanto, quando la tua attività si espande, l’orchestrazione dei dati si adatterà ai cambiamenti abituali.
Come funziona l’orchestrazione dei dati?

Il processo di orchestrazione dei dati implica la gestione e il coordinamento dei dati all’interno dell’organizzazione. Pertanto, include la raccolta di dati da diverse fonti, la loro trasformazione in un unico dato semplificato e l’automazione del flusso di lavoro.
L’orchestrazione dei dati ti consente di prendere decisioni aziendali informate utilizzando i dati come guida. Quindi, migliorando l’efficienza operativa e facilitando la collaborazione tra diversi team e dipartimenti della tua organizzazione.
Ciò consente lo spostamento, l’analisi e la consegna dei dati senza soluzione di continuità e ti aiuta a prendere decisioni informate.
Fasi dell’orchestrazione dei dati
L’orchestrazione dei dati è un processo complesso che prevede una serie di fasi interconnesse. Ogni fase è fondamentale per raccogliere, elaborare e analizzare i dati in modo efficace.
Approfondiamo ciascuna di queste fasi:
#1. Raccolta dati
Il viaggio di orchestrazione dei dati inizia con la fase di raccolta dei dati. Questa è la base dell’intero processo, in cui i dati vengono raccolti da molte fonti. Queste fonti potrebbero essere diverse come database, API, applicazioni e file esterni.

I dati raccolti possono comprendere dati strutturati, che seguono un formato specifico, e dati non strutturati, privi di un modello o di una forma predefiniti. La qualità, l’accuratezza e la pertinenza dei dati raccolti in questa fase influenzano in modo significativo le fasi successive dell’orchestrazione dei dati.
Pertanto, è fondamentale disporre di solide strategie e strumenti di raccolta dei dati per garantire la raccolta di dati pertinenti e di alta qualità.
#2. Ingestione di dati
La fase di acquisizione dei dati comporta l’importazione e il caricamento dei dati raccolti in una posizione di archiviazione centralizzata, in genere un data warehouse.
Questa posizione centrale funge da punto focale in cui i dati provenienti da fonti diverse si uniscono. Questo consolidamento semplifica la gestione e l’elaborazione dei dati, consentendo di gestirli e utilizzarli in modo efficace.
Per garantire il trasferimento accurato di tutti i dati rilevanti alla posizione di archiviazione centrale, è imperativo che il processo di acquisizione dei dati avvenga senza interruzioni e senza errori.
#3. Integrazione e trasformazione dei dati
La terza fase dell’orchestrazione dei dati comporta l’integrazione e la trasformazione dei dati raccolti per renderli utilizzabili per l’analisi. L’integrazione dei dati prende i dati da varie fonti e li unisce per presentare un’informazione coerente e significativa.

Questo processo è fondamentale per eliminare i silos di dati e garantire che tutti i dati siano accessibili e utilizzabili.
Quando si tratta di trasformazione dei dati, è necessario gestire i valori mancanti, risolvere le incoerenze dei dati e convertire i dati in un formato standardizzato per un’analisi più semplice. Questo processo cruciale facilita una migliore qualità dei dati e migliora la sua idoneità per l’analisi.
#4. Archiviazione e gestione dei dati
Dopo che i dati sono stati integrati e trasformati, la fase successiva prevede la memorizzazione di questi dati in un sistema di archiviazione appropriato.
Grandi volumi di dati potrebbero richiedere sistemi di archiviazione distribuiti, mentre i dati ad alta velocità potrebbero richiedere capacità di elaborazione in tempo reale. Il processo di gestione dei dati include l’impostazione dei controlli per l’accesso ai dati, la definizione dei criteri di governance dei dati e l’organizzazione dei dati per consentire un’analisi efficiente.
Garantire che i dati siano archiviati in modo sicuro, adeguatamente organizzati e facilmente accessibili per l’analisi è fondamentale durante questa fase.
#5. Elaborazione e analisi dei dati
L’elaborazione e l’analisi dei dati implicano l’esecuzione di flussi di lavoro di dati per svolgere varie attività di elaborazione dei dati. Queste attività potrebbero includere il filtraggio, l’ordinamento, l’aggregazione e l’unione di set di dati.

In base ai tuoi requisiti aziendali, hai due opzioni per l’elaborazione: flussi in tempo reale o metodi di elaborazione batch. Dopo che i dati sono stati elaborati, diventano pronti per l’analisi utilizzando varie piattaforme come business intelligence, strumenti di visualizzazione dei dati o apprendimento automatico.
Questo passaggio ha un significato immenso nell’estrazione di preziose informazioni dai dati e nel potenziamento del processo decisionale basato sui dati.
#6. Movimento e distribuzione dei dati
A seconda delle esigenze aziendali, potrebbe essere necessario spostare i dati su sistemi diversi per scopi specifici.
Lo spostamento dei dati implica la trasmissione o la replica sicura dei dati a partner esterni o altri sistemi all’interno dell’organizzazione. Questa fase assicura che i dati siano disponibili dove servono, sia che si tratti di ulteriori elaborazioni, analisi o report.
#7. Gestione del flusso di lavoro
L’automazione dei flussi di lavoro riduce gli interventi manuali e gli errori, migliorando così l’efficienza dei dati.
La maggior parte degli strumenti di orchestrazione dei dati offre funzionalità per monitorare i flussi di lavoro dei dati e facilitare operazioni fluide ed efficienti. Questa fase gioca un ruolo cruciale nel garantire che l’intero processo di orchestrazione dei dati funzioni senza intoppi.
#8. La sicurezza dei dati

Per abilitare la sicurezza dei dati, è necessario stabilire controlli di accesso e meccanismi di autenticazione. Queste misure proteggono le informazioni preziose dall’accesso non autorizzato e aiutano a mantenere la conformità alle normative sui dati e alle politiche interne.
Salvaguardando l’integrità e la privacy dei dati durante tutto il loro ciclo di vita, puoi mantenere un ambiente sicuro per le informazioni sensibili. Questa fase è fondamentale per mantenere la fiducia dei clienti e prevenire intenti dannosi.
#9. Monitoraggio e ottimizzazione delle prestazioni
Una volta avviato il processo di orchestrazione dei dati, è essenziale monitorare i flussi di lavoro dei dati e le prestazioni di elaborazione. Aiuta a identificare colli di bottiglia, problemi di utilizzo delle risorse e potenziali guasti.
Questa fase prevede l’analisi delle metriche delle prestazioni e l’ottimizzazione dei processi per migliorare l’efficienza. Questo monitoraggio e ottimizzazione continui aiutano a rendere efficiente ed efficace il processo di orchestrazione dei dati.
#10. Feedback e miglioramento continuo
L’orchestrazione dei dati è un processo ripetitivo. Implica l’acquisizione di feedback continui da analisti di dati, parti interessate e utenti aziendali per identificare aree di miglioramento e nuovi requisiti e perfezionare i flussi di lavoro dei dati esistenti.
Questo ciclo di feedback garantisce che il processo di orchestrazione dei dati sia in continua evoluzione e miglioramento, soddisfacendo così le mutevoli esigenze della tua azienda.
Casi d’uso dell’orchestrazione dei dati
L’orchestrazione dei dati trova applicazione in vari settori per una varietà di casi d’uso.
E-commerce e vendita al dettaglio

L’orchestrazione dei dati aiuta il settore dell’e-commerce e della vendita al dettaglio a gestire grandi volumi di dati sui prodotti, informazioni sull’inventario e interazione con i clienti. Li aiuta anche a integrare i dati di negozi online, sistemi di punti vendita e piattaforme di gestione della supply chain.
Sanità e scienze della vita
L’orchestrazione dei dati svolge un ruolo fondamentale nel settore sanitario e delle scienze della vita. Li aiuta a gestire, integrare e analizzare in modo sicuro le cartelle cliniche elettroniche, i dati sui dispositivi medici e gli studi sulle risorse. Aiuta anche nell’interoperabilità dei dati, nella condivisione dei dati dei pazienti e nei progressi della ricerca medica.
Settore finanziario
I servizi finanziari includono diversi dati finanziari come registri delle transazioni, dati di mercato, informazioni sui clienti, ecc. Pertanto, utilizzando l’orchestrazione dei dati, le organizzazioni del settore finanziario possono migliorare la gestione del rischio, il rilevamento delle frodi e la conformità alle normative.
Risorse umane
I dipartimenti delle risorse umane possono utilizzare l’orchestrazione dei dati per consolidare e analizzare i dati dei dipendenti, le metriche delle prestazioni e le informazioni sulle assunzioni. Aiuta anche nella gestione dei talenti, nel coinvolgimento dei dipendenti e nella pianificazione della forza lavoro.
Media e intrattenimento

Il settore dei media e dell’intrattenimento comprende la distribuzione di contenuti su varie piattaforme. L’industria dei media può realizzare facilmente pubblicità mirate, motori di raccomandazione dei contenuti e analisi del pubblico attraverso l’orchestrazione dei dati.
Gestione della catena di approvvigionamento
La gestione della catena di approvvigionamento comprende i dati di fornitori, fornitori di servizi logistici e sistemi di inventario. Qui, l’orchestrazione dei dati aiuta a integrare tutti questi dati e consente il monitoraggio in tempo reale dei prodotti.
Le migliori piattaforme di orchestrazione dei dati
Ora che hai un’idea dell’orchestrazione dei dati, parliamo delle migliori piattaforme di orchestrazione dei dati.
#1. Flyte

Flyte è una piattaforma completa di orchestrazione del flusso di lavoro progettata per unificare senza problemi dati, machine learning (ML) e dati analitici. Questo sistema basato su cloud per l’apprendimento automatico e l’elaborazione dei dati può aiutarti a gestire i dati con affidabilità ed efficacia.
Flyte incorpora una programmazione strutturata open source e una soluzione distribuita. Consente di utilizzare flussi di lavoro simultanei, scalabili e di facile manutenzione per attività di machine learning ed elaborazione dati.
Uno degli aspetti unici di Flyte è l’uso dei buffer di protocollo come linguaggio di specifica per definire questi flussi di lavoro e attività, rendendolo una soluzione flessibile e adattabile per varie esigenze di dati.
Caratteristiche principali
- Facilita la rapida sperimentazione utilizzando software di livello di produzione
- Progettato pensando alla scalabilità per gestire i carichi di lavoro in evoluzione e le esigenze di risorse
- Consente ai professionisti dei dati e agli scienziati di creare flussi di lavoro in modo indipendente utilizzando Python SDK
- Fornisce dati estremamente flessibili e flussi di lavoro ML con lineage dei dati end-to-end e componenti riutilizzabili
- Offre una piattaforma centralizzata per la gestione del ciclo di vita dei flussi di lavoro
- Richiede un sovraccarico di manutenzione minimo
- Supportato da una vivace comunità per il supporto
- Offre una gamma di integrazioni per un processo di sviluppo del flusso di lavoro semplificato
#2. Prefetto
Incontrare Prefetto, la soluzione all’avanguardia per la gestione del flusso di lavoro guidata dal motore di flusso di lavoro open source Prefect Core. Rappresenta l’avanguardia nella gestione dei flussi di lavoro con le sue funzionalità avanzate.

Prefect è progettato specificamente per assisterti nella gestione senza problemi di attività complesse che coinvolgono i dati, con semplicità ed efficienza come principi fondamentali. Con Prefect a tua disposizione, organizza facilmente le tue funzioni Python in unità di lavoro gestibili, godendo al tempo stesso di funzionalità complete di monitoraggio e coordinamento.
Una delle straordinarie caratteristiche di Prefect è la sua capacità di creare flussi di lavoro robusti e dinamici, consentendoti di adattarti senza problemi ai cambiamenti nel loro ambiente. Nel caso in cui si verifichino eventi imprevisti, Prefect recupera con garbo, garantendo una gestione dei dati senza soluzione di continuità.
Questa adattabilità rende Prefect una scelta ideale per le situazioni in cui la flessibilità è fondamentale. Con tentativi automatici, esecuzione distribuita, pianificazione, memorizzazione nella cache e altro ancora, Prefect diventa uno strumento prezioso in grado di affrontare qualsiasi sfida relativa ai dati che potresti incontrare.
Caratteristiche principali
- Automazione per osservabilità e controllo in tempo reale
- Una vivace comunità per il supporto e la condivisione delle conoscenze
- Documentazione completa per la creazione di potenti applicazioni dati
- Forum di discussione per le risposte alle domande relative al prefetto
#3. Controllo-M
Controllo-M è una soluzione affidabile che connette, automatizza e orchestra i flussi di lavoro di applicazioni e dati in ambienti cloud on-premise, privati e pubblici.
Questo strumento garantisce ogni volta il completamento del lavoro puntuale e coerente, rendendolo una soluzione affidabile se è necessaria una gestione dei dati coerente ed efficiente. Con un’interfaccia coerente e un’ampia gamma di plug-in, gli utenti possono gestire facilmente tutte le loro operazioni, inclusi trasferimenti di file, app, origini dati e infrastruttura.

Puoi eseguire rapidamente il provisioning di Control-M sul cloud, utilizzando le funzionalità transitorie dei servizi basati su cloud. Questo lo rende una soluzione versatile e adattabile per varie esigenze di dati.
Caratteristiche principali
- Capacità operative avanzate per lo sviluppo e le operazioni
- Gestione proattiva degli SLA con analisi predittive intelligenti
- Solido supporto per audit, conformità e governance
- Stabilità comprovata per il ridimensionamento da decine a milioni di lavori senza tempi di inattività
- Approccio Jobs-as-Code per scalare la collaborazione Dev e Ops
- Flussi di lavoro semplificati in ambienti ibridi e multi-cloud
- Movimento e visibilità dei file sicuri, integrati e intelligenti
#4. Datacoral
Datacoral è un fornitore leader di uno stack di infrastruttura dati completo per i big data. Può raccogliere dati da varie fonti in tempo reale senza sforzo manuale. Una volta raccolti i dati, organizza automaticamente questi dati in un motore di query di tua scelta.
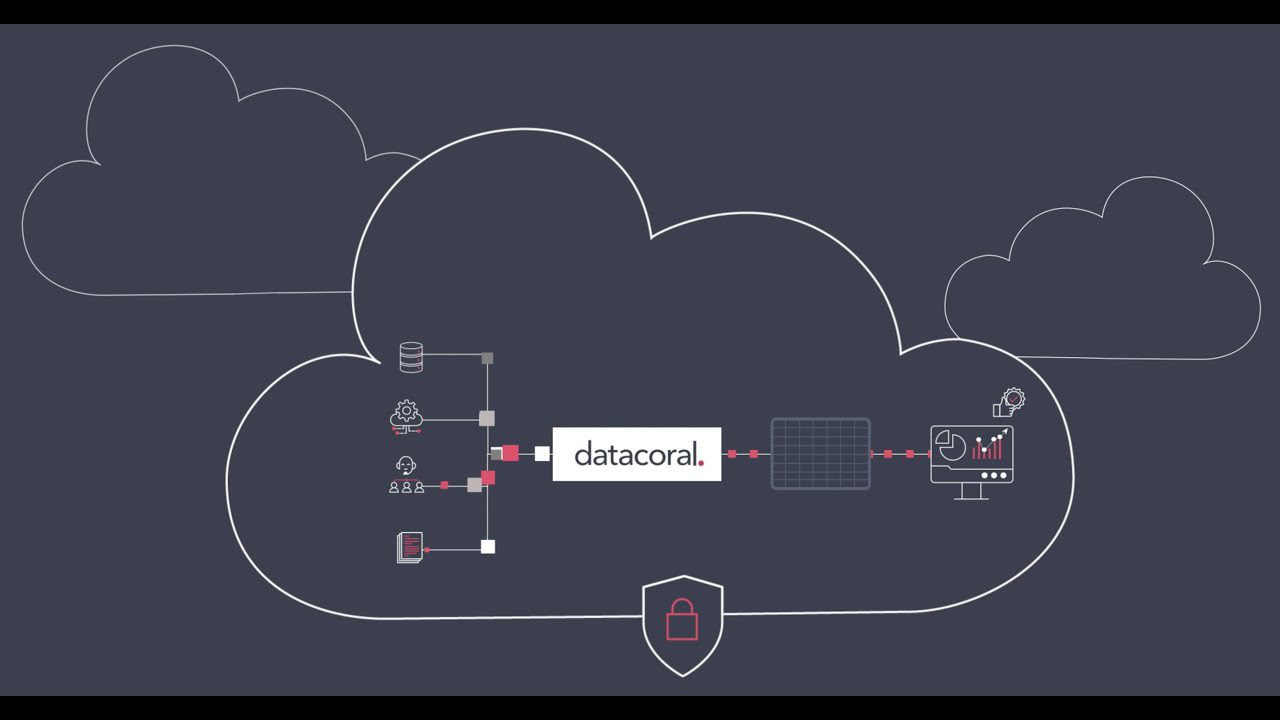
Dopo aver ottenuto preziose informazioni, puoi utilizzare i dati per vari scopi e pubblicarli. Il linguaggio è incentrato sui dati, consentendo l’accesso in tempo reale alle origini dati per qualsiasi motore di query. Serve anche come strumento per monitorare l’aggiornamento dei dati e garantire l’integrità dei dati, rendendolo una soluzione ideale se si richiede una gestione dei dati affidabile ed efficiente.
Caratteristiche principali
- Connettori dati senza codice per un accesso sicuro e affidabile ai dati
- Architettura basata sui metadati per un’immagine completa dei dati
- Estrazione dei dati personalizzabile con visibilità completa sull’aggiornamento e sulla qualità dei dati
- Installazione sicura nel tuo VPC
- Controlli di qualità dei dati pronti all’uso
- Connettori CDC per database come PostgreSQL e MySQL
- Costruito per scalare con un framework semplificato per integrazioni di dati e pipeline basate su cloud
#5. Dagster
Dagster è una piattaforma di orchestrazione open source di nuova generazione per lo sviluppo, la produzione e il monitoraggio di asset di dati.

Lo strumento affronta l’ingegneria dei dati da zero, coprendo l’intero ciclo di vita dello sviluppo, dallo sviluppo iniziale e l’implementazione al monitoraggio continuo e all’osservabilità. Dagster è una soluzione completa e onnicomprensiva se hai bisogno di una gestione dei dati efficace e affidabile.
Caratteristiche principali
- Fornisce discendenza e osservabilità integrate
- Utilizza un modello di programmazione dichiarativo per una gestione più semplice del flusso di lavoro
- Offre la migliore testabilità della categoria per flussi di lavoro affidabili e accurati
- Dagster Cloud per distribuzioni serverless o ibride, ramificazione nativa e CI/CD pronti all’uso
- Si integra con gli strumenti che già utilizzi ed è distribuibile nella tua infrastruttura
Conclusione
L’orchestrazione dei dati è un ottimo modo per semplificare e ottimizzare l’intero processo di gestione dei dati. Semplifica il modo in cui le aziende gestiscono i propri dati, dalla raccolta e preparazione all’analisi e all’utilizzo efficace.
L’orchestrazione dei dati consente alle aziende di collaborare agevolmente con diverse origini dati, applicazioni e team. Di conseguenza, sperimenterai un processo decisionale più rapido e preciso, una maggiore produttività e prestazioni complessive migliorate.
Quindi, scegli uno degli strumenti di orchestrazione dei dati di cui sopra in base alle tue preferenze e requisiti e cogli i loro vantaggi.
Puoi anche esplorare alcuni strumenti di orchestrazione dei container per DevOps