Prometheus si presenta come una soluzione open source per il monitoraggio, imperniata sull’analisi di metriche. Il suo funzionamento si basa sulla raccolta di dati provenienti da diversi servizi e host, attraverso l’invio di richieste HTTP a specifici endpoint. Successivamente, i dati acquisiti vengono archiviati in un database di serie temporali, rendendoli disponibili per analisi dettagliate e per la configurazione di allarmi.
L’Importanza del Monitoraggio
- Il monitoraggio permette di attivare avvisi in caso di anomalie, idealmente prima che queste si trasformino in problemi concreti. Questo consente un intervento tempestivo da parte degli addetti.
- Fornisce informazioni cruciali per l’analisi, il debug e la risoluzione di eventuali problematiche, agevolando il processo di identificazione e correzione degli errori.
- Consente di monitorare l’andamento e le modifiche nel tempo, come ad esempio il numero di sessioni attive in un determinato momento. Ciò è fondamentale per prendere decisioni progettuali e per pianificare adeguatamente la capacità del sistema.
Il concetto di monitoraggio è spesso associato a eventi specifici, quali la ricezione di richieste HTTP, l’invio di risposte, la lettura dal disco o l’accesso di un utente. Il monitoraggio di un sistema può abbracciare diverse attività, tra cui profilazione, registrazione, tracciamento, analisi delle metriche, gestione degli avvisi e visualizzazione dei dati.
Monitoraggio Blackbox vs. Whitebox: Due Approcci a Confronto
Il monitoraggio può essere categorizzato in due tipologie principali:
Monitoraggio Blackbox (Scatola Nera)
In questo approccio, il monitoraggio si concentra sul livello applicativo o dell’host, osservando il sistema dall’esterno. Questo metodo può presentare delle limitazioni a causa della sua visione esterna e superficiale.
Monitoraggio Whitebox (Scatola Bianca)
Il monitoraggio Whitebox, invece, analizza il servizio dall’interno, esponendo dati dettagliati sullo stato e sulle performance dei suoi componenti interni. Questa prospettiva offre una comprensione più profonda del funzionamento del sistema.
I Quattro Segnali d’Oro
Secondo Google, se dovessimo concentrarci su pochi parametri di un sistema rivolto all’utente, dovremmo privilegiare i seguenti quattro, definiti “i quattro segnali d’oro”:
#1. Latenza
Rappresenta il tempo necessario per elaborare una richiesta, sia essa andata a buon fine o fallita. È fondamentale monitorare sia le richieste completate con successo, sia quelle che hanno generato un errore.
#2. Traffico
Misura il volume di richieste che vengono inviate al sistema. Nel caso di un servizio web, questo parametro corrisponde tipicamente al numero di richieste HTTP al secondo.
#3. Errori
Indica la percentuale di richieste che non sono state completate con successo.
#4. Saturazione
Riflette il grado di utilizzo delle risorse del sistema. Un aumento della latenza è spesso un segnale di saturazione. Molti sistemi tendono a degradare le prestazioni ben prima di raggiungere il 100% di utilizzo.
Tipologie di Metriche in Prometheus
Le metriche in Prometheus si suddividono in quattro categorie principali:
#1. Contatore
Il valore di un contatore è sempre crescente e non può diminuire, sebbene possa essere azzerato. In caso di fallimento di uno scrape, si registra semplicemente la mancanza di un punto dati. L’incremento cumulativo sarà comunque disponibile al prossimo rilevamento. Esempi tipici includono il numero totale di richieste HTTP ricevute o il numero di eccezioni.
#2. Misura
Una misura rappresenta un’istantanea in un determinato momento. Il suo valore può sia aumentare che diminuire. In caso di fallimento del recupero dei dati, si perde un singolo campione, mentre il recupero successivo potrebbe mostrare un valore diverso. Esempi comuni sono lo spazio su disco o l’utilizzo della memoria.
#3. Istogramma
Un istogramma campiona le osservazioni e le conteggia all’interno di intervalli configurabili. Viene utilizzato per misurare parametri come la durata di una richiesta o le dimensioni di una risposta. Ad esempio, è possibile misurare la durata di una specifica richiesta HTTP. L’istogramma suddivide le durate in intervalli, come 1 ms, 10 ms e 25 ms. Anziché memorizzare la durata esatta di ogni richiesta, Prometheus archivia la frequenza delle richieste che rientrano in un determinato intervallo.
#4. Riepilogo
Simile agli istogrammi, il riepilogo campiona le osservazioni, generalmente durate o dimensioni di risposta. Fornisce un conteggio totale delle osservazioni e la somma di tutti i valori osservati, consentendo di calcolare la media dei valori. Ad esempio, se in un minuto si sono verificate tre richieste che hanno impiegato rispettivamente 2, 3 e 4 secondi, la somma sarà 9, il conteggio 3 e la latenza media sarà di 3 secondi.
Componenti Chiave dell’Ecosistema Prometheus
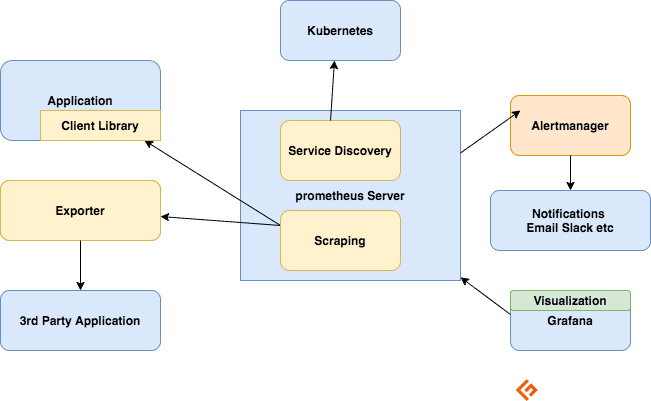
Il Server Prometheus
Il server Prometheus svolge il compito di acquisire le metriche, archiviarle e renderle disponibili per l’interrogazione, oltre a inviare avvisi in base ai dati raccolti.
Lo Scraping
Prometheus utilizza un sistema “pull-based”. Per acquisire le metriche, invia richieste HTTP, denominate “scrape”, alle destinazioni configurate. Questi “scrape” vengono inviati a intervalli regolari, definiti “intervallo di scrape”. Ogni “scrape” legge l’endpoint HTTP “/metrics” per ottenere lo stato corrente delle metriche del client e ne archivia i valori nel database delle serie temporali di Prometheus.
Esistono diversi database di serie temporali che possono essere impiegati per il monitoraggio.
Librerie Client
Per monitorare un servizio, è necessario integrare degli strumenti all’interno del codice. Sono disponibili librerie client per i linguaggi e runtime più utilizzati. Queste librerie consentono di definire metriche interne e di esporle tramite un endpoint HTTP. Quando Prometheus effettua lo scrape dell’endpoint HTTP delle metriche, la libreria client invia le metriche al server. Questa modalità di integrazione è nota come “strumentazione diretta”.
Prometheus offre librerie client ufficiali per Go, Java, Python e Ruby. Inoltre, grazie all’ecosistema aperto di Prometheus, sono disponibili librerie client create dalla comunità per C, PHP, Node.js, C#/.NET e molte altre piattaforme.
Esportatori
Molte applicazioni espongono le metriche in un formato non compatibile con Prometheus. In questi casi, e per le applicazioni di cui non si possiede il codice o per le quali non si ha accesso, non è possibile aggiungere la strumentazione diretta. Si pensi ad esempio a server MySQL, Kafka, JMX, HAProxy e NGINX. In queste situazioni, si utilizzano gli esportatori.
Un esportatore è uno strumento che viene installato insieme all’applicazione di cui si vogliono ottenere le metriche. L’esportatore funge da intermediario tra l’applicazione e Prometheus. Riceve le richieste dal server Prometheus, raccoglie i dati dai log di accesso e dagli errori dell’applicazione, li trasforma nel formato corretto e li restituisce al server Prometheus.
Ecco alcuni degli esportatori più popolari:
- Windows – per le metriche dei server Windows
- Node – per le metriche dei server Linux
- Blackbox – per le metriche delle prestazioni DNS e dei siti web
- JMX – per le metriche delle applicazioni basate su Java
Una volta che le applicazioni sono state strumentate o gli esportatori sono stati installati, è necessario comunicare a Prometheus dove si trovano. Questo può essere fatto attraverso la configurazione statica. In ambienti dinamici, dove questa soluzione non è praticabile, si ricorre al rilevamento dei servizi.
Alerting
Il sistema di alerting di Prometheus si articola in due componenti:
Le regole di allarme (alerting rules) inviano avvisi all’Alertmanager.
L’Alertmanager si occupa di gestire questi avvisi, inoltrando notifiche tramite diverse integrazioni predefinite, come e-mail, Slack, Hipchat e PagerDuty. L’Alertmanager può anche silenziar o aggregare gli avvisi per ridurre il numero di notifiche.
Ecco una guida per monitorare un server Linux tramite Prometheus e dashboard.
Visualizzazione tramite Dashboard
Prometheus mette a disposizione una serie di API che, attraverso le query PromQL, permettono di estrarre dati grezzi da utilizzare per la visualizzazione.
Sebbene Prometheus includa un’interfaccia per l’esecuzione di query ad hoc, lo strumento più efficace per la visualizzazione è Grafana. Grafana si integra perfettamente con Prometheus e consente la creazione di un’ampia varietà di dashboard.
È necessario configurare Prometheus come fonte dati per Grafana.
Le dashboard possono essere aggiunte tramite:
- Importazione di dashboard create dalla community
- Creazione di dashboard personalizzate
- Utilizzo di dashboard predefinite
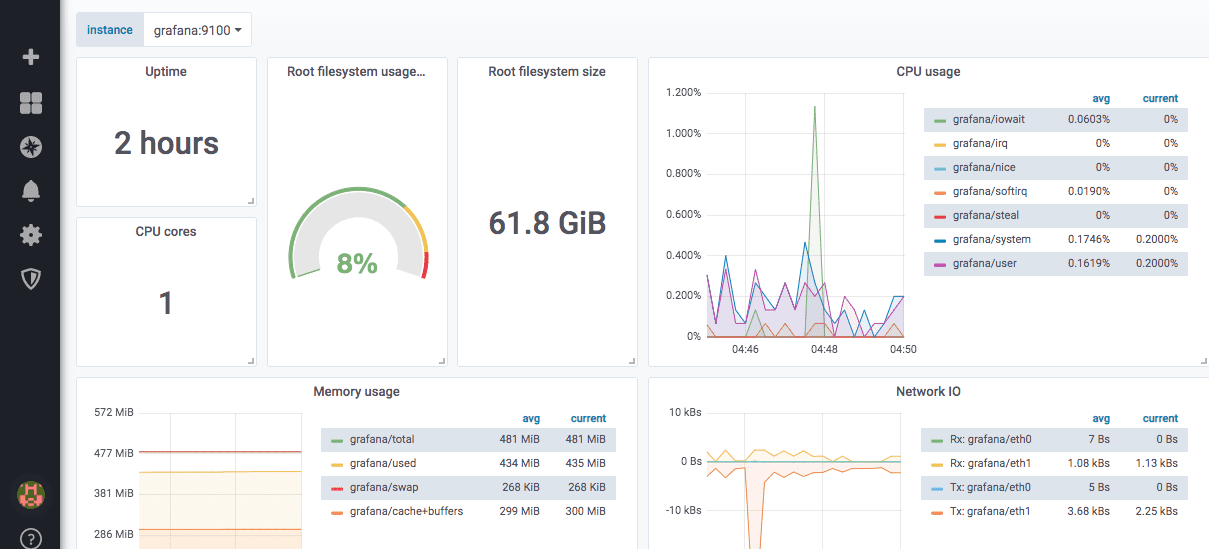
Ecco un esempio di una dashboard predefinita dell’esportatore di nodi:
Grafana include un modulo worldPing che consente di monitorare le metriche delle prestazioni di siti web e DNS in tutto il mondo.
In Sintesi
Prometheus ha requisiti minimi e può essere facilmente eseguito come un singolo binario con un file di configurazione. È in grado di gestire migliaia di obiettivi e acquisire milioni di campioni al secondo. Prometheus è progettato per monitorare lo stato generale, la salute e il comportamento del sistema.
Grafana è lo strumento di visualizzazione più efficace e si integra perfettamente con Prometheus.