Immagina di dover gestire una vasta infrastruttura composta da svariati tipi di dispositivi, con la necessità di effettuare controlli periodici per garantire il loro corretto funzionamento e la sicurezza ambientale.
Un approccio consiste nell’inviare regolarmente personale qualificato a ispezionare ogni singolo punto. Sebbene fattibile, questa soluzione risulta piuttosto dispendiosa in termini di tempo e risorse. In presenza di un’infrastruttura di notevoli dimensioni, potrebbe essere impossibile coprirla interamente nell’arco di un anno.
Un’alternativa è automatizzare tale processo, affidando la verifica a sistemi cloud. Per realizzare ciò, è necessario:
👉 Implementare una procedura rapida per l’acquisizione di immagini dei dispositivi. Questo compito può essere svolto da operatori, in quanto più veloce rispetto alla verifica completa di ogni dispositivo. In alternativa, è possibile utilizzare fotografie scattate da veicoli o droni, velocizzando e automatizzando la raccolta delle immagini.
👉 Trasferire tutte le immagini acquisite in uno spazio dedicato nel cloud.
👉 Nel cloud, attivare un processo automatico per raccogliere le immagini e analizzarle tramite modelli di machine learning addestrati a individuare danni o anomalie nei dispositivi.
👉 Infine, rendere i risultati accessibili agli utenti autorizzati, in modo da pianificare interventi di riparazione per i dispositivi problematici.
Analizziamo ora come ottenere il rilevamento delle anomalie tramite immagini nel cloud AWS, sfruttando i modelli di machine learning predefiniti forniti da Amazon.
Creazione di un modello per il rilevamento di anomalie visive
La creazione di un modello per il rilevamento di anomalie visive richiede una serie di passaggi:
Passo 1: Definire chiaramente il problema che si intende risolvere e le tipologie di anomalie da individuare. Ciò consentirà di determinare il set di dati di test appropriato necessario per addestrare il modello.
Passo 2: Raccogliere un ampio set di immagini rappresentative di condizioni sia normali che anomale. Tali immagini dovranno essere etichettate per distinguerle.
Passo 3: Selezionare l’architettura del modello più idonea all’attività. Questa fase può prevedere la scelta di un modello pre-addestrato e la sua ottimizzazione per il caso d’uso specifico, o la creazione di un modello personalizzato da zero.
Passo 4: Addestrare il modello usando il set di dati preparato e l’algoritmo selezionato. A tale scopo, si può utilizzare il transfer learning, sfruttando modelli pre-addestrati, o addestrare il modello partendo da zero, ricorrendo a tecniche come le reti neurali convoluzionali (CNN).
Addestramento di un modello di Machine Learning
Fonte: aws.amazon.com
Il processo di addestramento dei modelli di machine learning AWS per il rilevamento di anomalie visive comprende in genere diverse fasi fondamentali.
#1. Raccolta dei dati
Inizialmente, è necessario raccogliere e classificare un ampio set di immagini che rappresentano condizioni sia normali che anomale. Maggiore è la quantità di dati, migliore sarà la precisione del modello. Tuttavia, ciò richiede più tempo dedicato all’addestramento.
Di solito, per iniziare in modo efficace, è consigliabile avere almeno 1000 immagini in un set di test.
#2. Preparazione dei dati
I dati delle immagini devono essere pre-elaborati per essere utilizzabili dai modelli di apprendimento automatico. La pre-elaborazione può comprendere diverse azioni, come:
- Organizzare le immagini di input in sottocartelle separate, correggendo i metadati, ecc.
- Ridimensionare le immagini per soddisfare i requisiti di risoluzione del modello.
- Distribuirle in blocchi più piccoli per un’elaborazione più efficace e parallela.
#3. Scelta del Modello
Selezionare il modello più appropriato. È possibile optare per un modello pre-addestrato o crearne uno personalizzato adatto al rilevamento visivo di anomalie.
#4. Valutazione dei risultati
Dopo che il modello ha elaborato il set di dati, è necessario convalidare le sue prestazioni, verificando se i risultati soddisfano i requisiti. Ad esempio, è possibile stabilire che i risultati siano corretti in oltre il 99% dei casi.
#5. Distribuzione del modello
Se i risultati e le prestazioni sono soddisfacenti, il modello può essere distribuito nell’ambiente dell’account AWS, in modo che possa essere utilizzato da processi e servizi.
#6. Monitoraggio e miglioramento
È necessario eseguire periodicamente test su vari set di dati e valutare se i parametri di correttezza del rilevamento rimangono validi.
In caso contrario, occorre ripetere l’addestramento del modello includendo i nuovi set di dati che hanno portato a risultati errati.
Modelli di machine learning AWS
Ora, esaminiamo alcuni modelli concreti che è possibile utilizzare nel cloud di Amazon.
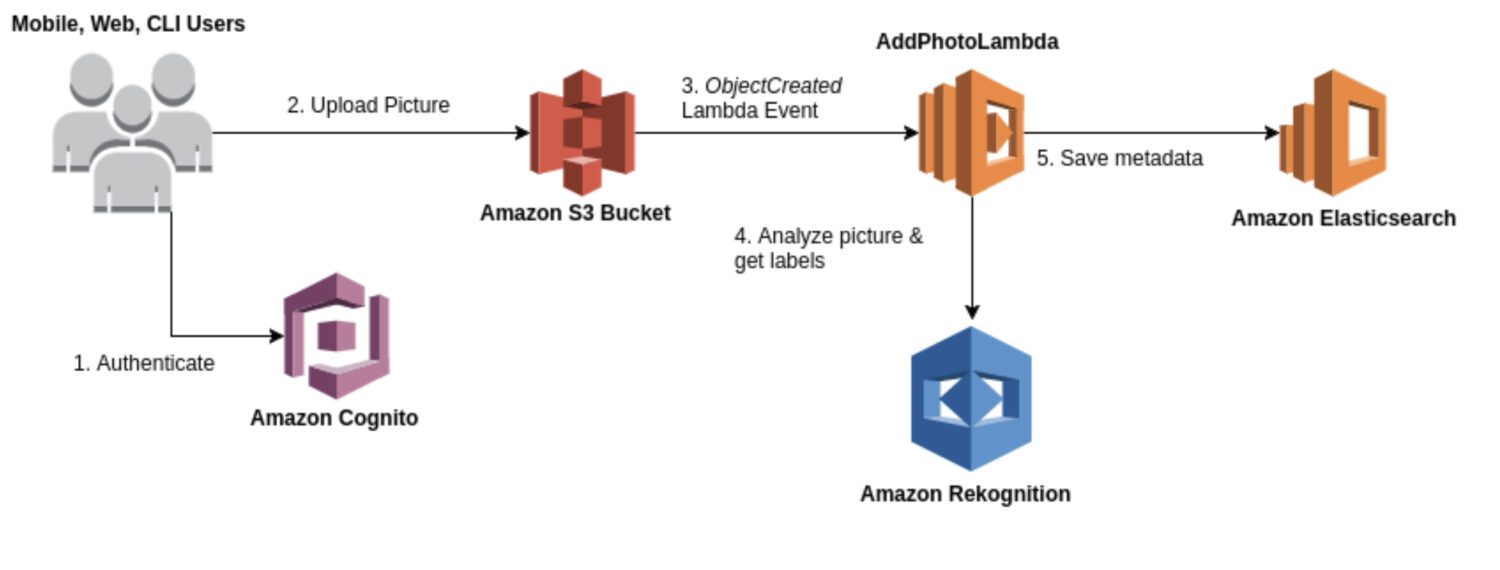
AWS Rekognition
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Rekognition è un servizio generico per l’analisi di immagini e video utilizzabile in vari contesti, come il riconoscimento facciale, il rilevamento di oggetti e il riconoscimento del testo. Nella maggior parte dei casi, il modello Rekognition viene impiegato per generare una prima serie di risultati di rilevamento e costituire un data lake di anomalie identificate.
Offre una gamma di modelli predefiniti, utilizzabili senza necessità di addestramento. Rekognition fornisce inoltre analisi in tempo reale di immagini e video, con elevata accuratezza e bassa latenza.
Ecco alcuni casi d’uso tipici in cui Rekognition è una buona scelta per il rilevamento di anomalie:
- Utilizzo di un approccio generico per il rilevamento di anomalie in immagini o video.
- Esecuzione del rilevamento di anomalie in tempo reale.
- Integrazione del modello di rilevamento di anomalie con i servizi AWS, come Amazon S3, Amazon Kinesis o AWS Lambda.
Ed ecco alcuni esempi concreti di anomalie che è possibile rilevare utilizzando Rekognition:
- Anomalie nei volti, come il rilevamento di espressioni facciali o emozioni al di fuori dei parametri normali.
- Oggetti mancanti o fuori posto in una scena.
- Parole con errori di ortografia o schemi di testo insoliti.
- Condizioni di illuminazione insolite o oggetti inaspettati in una scena.
- Contenuti inappropriati o offensivi in immagini o video.
- Cambiamenti improvvisi nel movimento o schemi di movimento imprevisti.
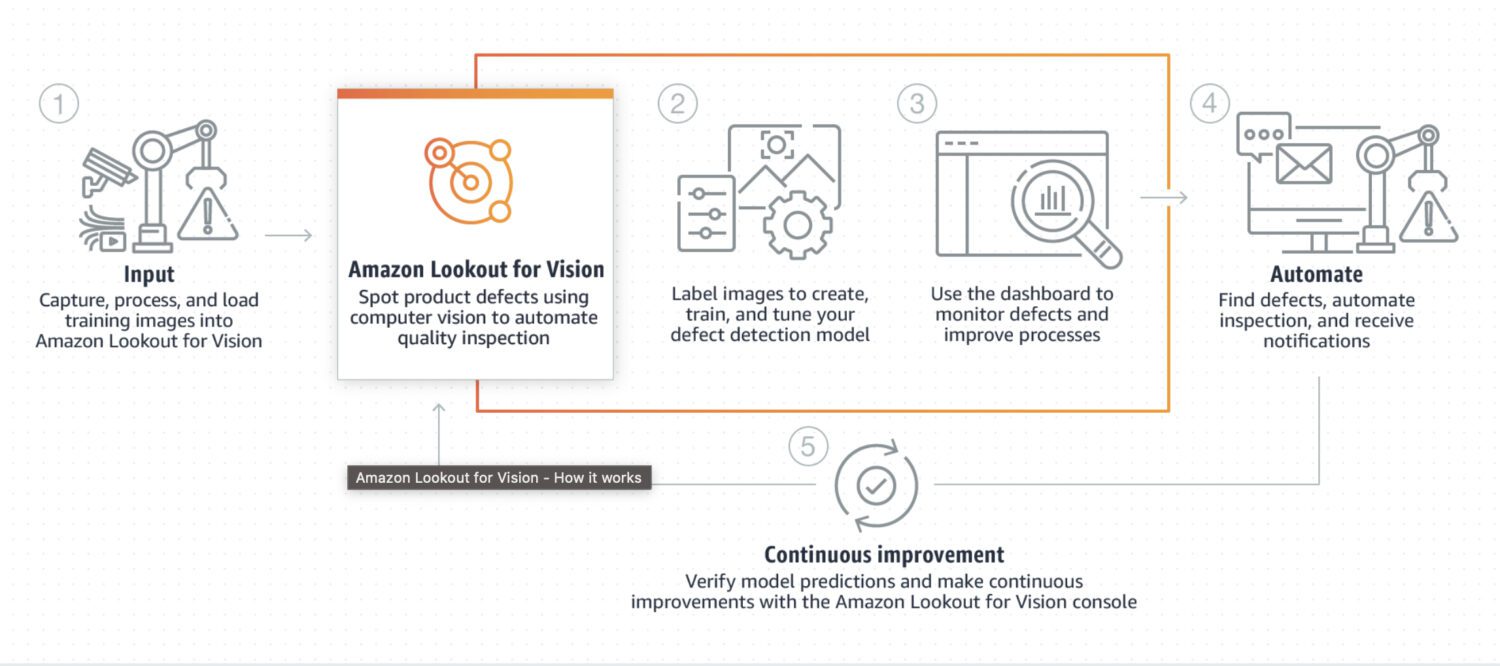
AWS Lookout for Vision
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Lookout for Vision è un modello progettato specificamente per il rilevamento di anomalie in processi industriali, come la produzione e le linee di assemblaggio. Richiede una pre-elaborazione e post-elaborazione di codice personalizzato per un’immagine o un ritaglio specifico, solitamente eseguita in linguaggio Python. Nella maggior parte dei casi, è specializzato in problemi molto particolari relativi alle immagini.
Richiede un addestramento personalizzato su un set di immagini normali e anomale per creare un modello specifico per il rilevamento delle anomalie. Non è particolarmente adatto all’elaborazione in tempo reale, ma è progettato per l’elaborazione in batch di immagini, con particolare attenzione ad accuratezza e precisione.
Ecco alcuni casi d’uso tipici in cui Lookout for Vision è una buona scelta, ad esempio quando è necessario rilevare:
- Difetti in prodotti fabbricati o guasti alle apparecchiature in una linea di produzione.
- Un grande set di immagini o altri dati.
- Anomalie in tempo reale in un processo industriale.
- Integrazione con altri servizi AWS, come Amazon S3 o AWS IoT.
Ed ecco alcuni esempi concreti di anomalie che è possibile rilevare utilizzando Lookout for Vision:
- Difetti nei prodotti fabbricati, come graffi, ammaccature o altre imperfezioni che possono influire sulla qualità del prodotto.
- Guasti alle apparecchiature in una linea di produzione, come il rilevamento di macchinari rotti o malfunzionanti che possono causare ritardi o rischi per la sicurezza.
- Problemi di controllo qualità in una linea di produzione, come il rilevamento di prodotti che non soddisfano le specifiche o le tolleranze richieste.
- Rischi per la sicurezza in una linea di produzione, come il rilevamento di oggetti o materiali che possono rappresentare un pericolo per i lavoratori o le attrezzature.
- Anomalie in un processo di produzione, come il rilevamento di cambiamenti imprevisti nel flusso di materiali o prodotti attraverso la linea di produzione.
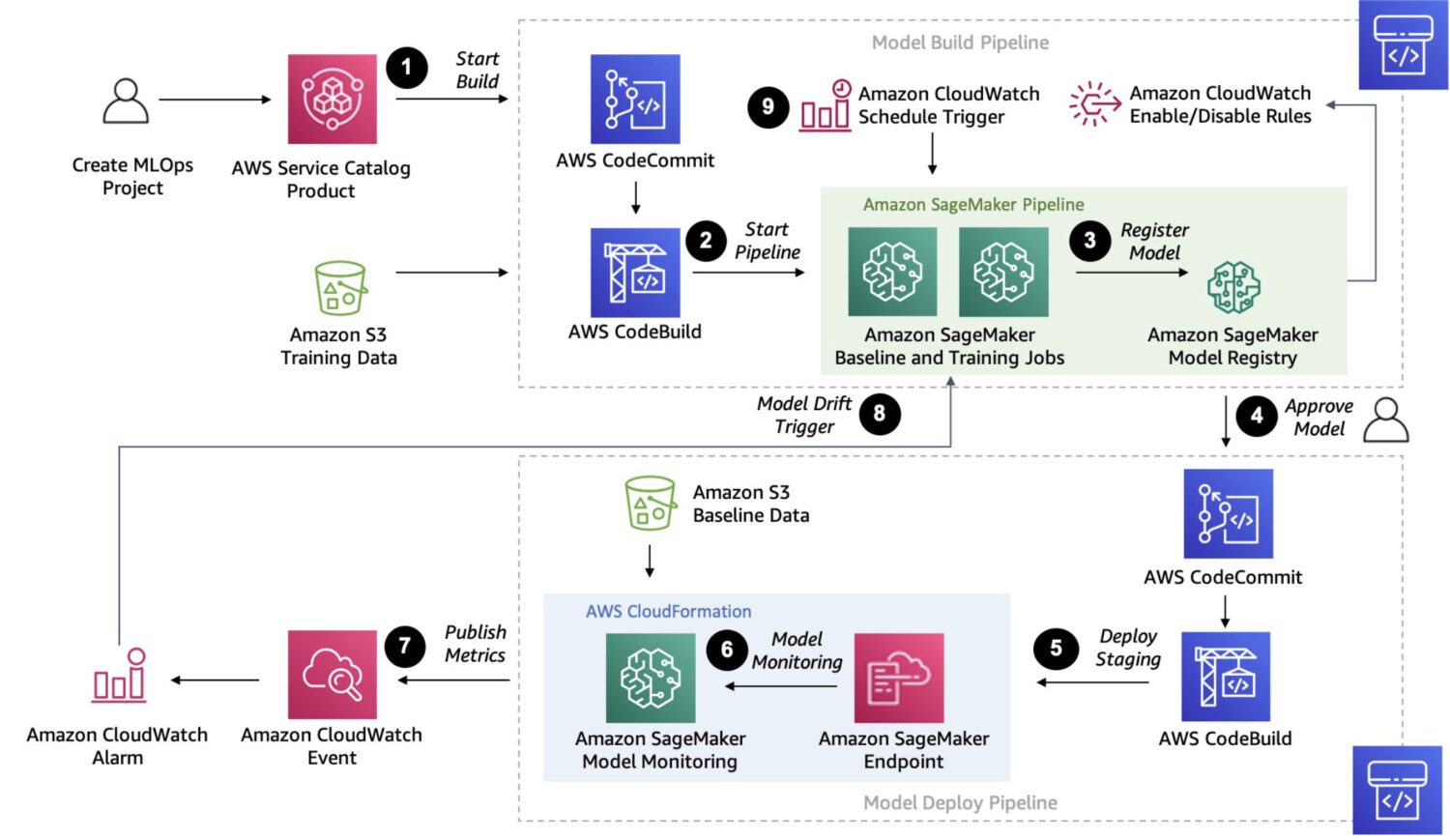
AWS Sagemaker
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Sagemaker è una piattaforma completamente gestita per la creazione, l’addestramento e l’implementazione di modelli di machine learning personalizzati.
È una soluzione molto più robusta, che permette di connettere ed eseguire diversi processi in una catena di lavori sequenziali, analogamente a quanto consentito da AWS Step Functions.
Tuttavia, poiché Sagemaker utilizza istanze EC2 ad hoc per l’elaborazione, non esiste il limite di 15 minuti per l’esecuzione di un singolo lavoro, come nel caso delle funzioni AWS Lambda in AWS Step Functions.
Sagemaker consente anche l’ottimizzazione automatica del modello, una caratteristica che lo rende un’opzione di spicco. Infine, facilita l’implementazione del modello in un ambiente di produzione.
Ecco alcuni casi d’uso tipici in cui SageMaker è una buona scelta per il rilevamento di anomalie:
- Presenza di un caso d’uso specifico non coperto da modelli o API predefiniti e necessità di creare un modello personalizzato su misura per esigenze specifiche.
- Disponibilità di un ampio set di immagini o altri dati. I modelli predefiniti richiedono una pre-elaborazione in questi casi, mentre Sagemaker è in grado di farne a meno.
- Necessità di eseguire il rilevamento delle anomalie in tempo reale.
- Necessità di integrare il modello con altri servizi AWS, come Amazon S3, Amazon Kinesis o AWS Lambda.
Ed ecco alcuni tipici rilevamenti di anomalie che Sagemaker è in grado di eseguire:
- Rilevamento di frodi in transazioni finanziarie, ad esempio, schemi di spesa insoliti o transazioni al di fuori dei parametri normali.
- Sicurezza informatica nel traffico di rete, ad esempio, schemi insoliti di trasferimento dati o connessioni impreviste a server esterni.
- Diagnosi medica in immagini mediche, come il rilevamento di tumori.
- Anomalie nelle prestazioni delle apparecchiature, come il rilevamento di variazioni nelle vibrazioni o nella temperatura.
- Controllo qualità nei processi di produzione, come il rilevamento di difetti nei prodotti o l’identificazione di scostamenti dagli standard di qualità previsti.
- Schemi insoliti di consumo di energia.
Come integrare i modelli in un’architettura serverless
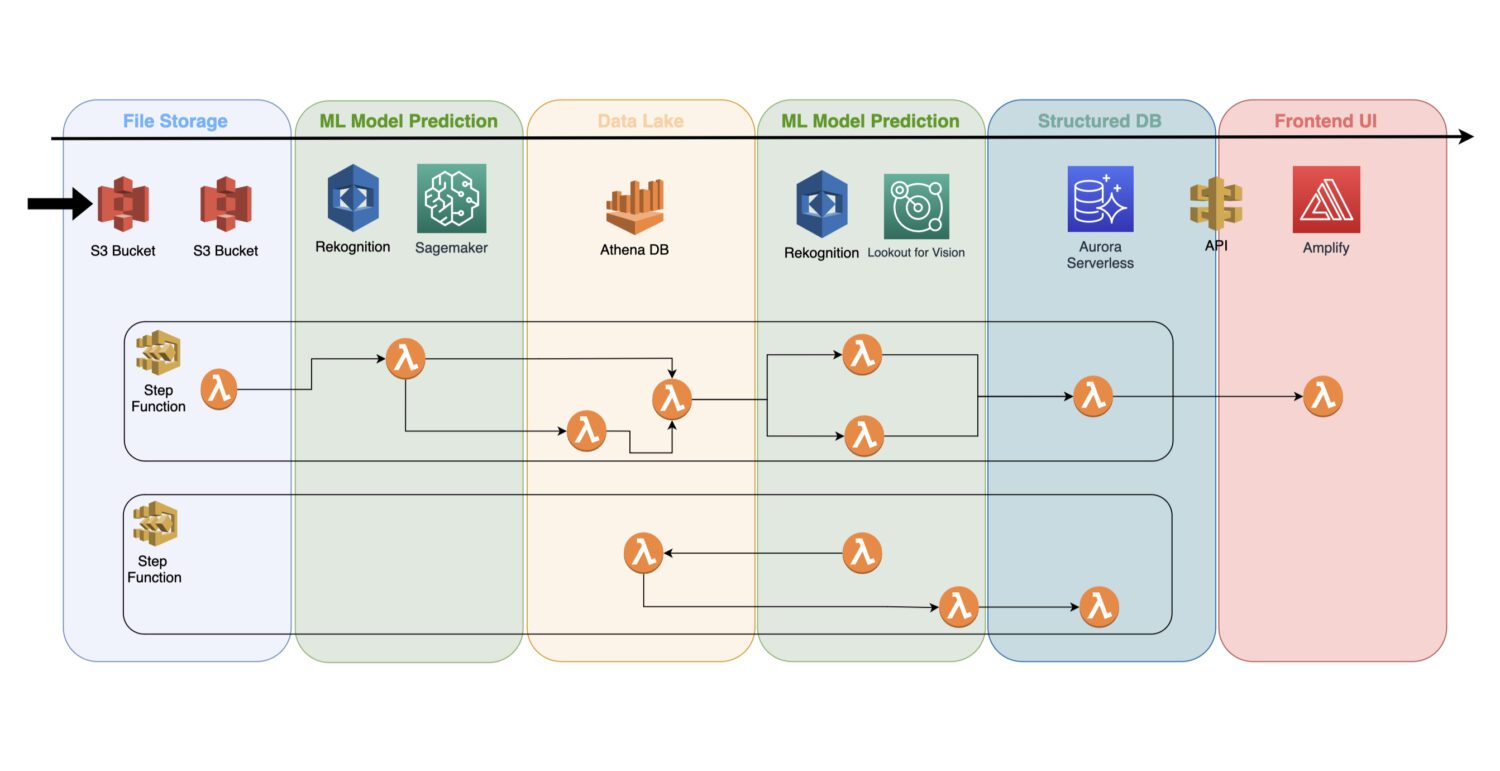
Un modello di apprendimento automatico addestrato è un servizio cloud che non utilizza server cluster in background; di conseguenza, può essere facilmente integrato in un’architettura serverless esistente.
L’automazione avviene tramite le funzioni lambda AWS, collegate in un processo a più fasi all’interno del servizio AWS Step Functions.
In genere, il rilevamento iniziale è necessario subito dopo l’acquisizione delle immagini e la loro pre-elaborazione nel bucket S3. In questa fase, si genera il rilevamento di anomalie elementari sulle immagini di input, salvando i risultati in un data lake, ad esempio rappresentato dal database Athena.
In alcuni casi, questo primo rilevamento potrebbe non essere sufficiente per il caso d’uso specifico e potrebbe essere necessario un’analisi più dettagliata. Ad esempio, il modello iniziale (come Rekognition) potrebbe rilevare un problema sul dispositivo, senza però riuscire a identificarne il tipo.
Per questo, è necessario un altro modello con capacità diverse. In tal caso, è possibile eseguire l’altro modello (ad esempio, Lookout for Vision) sul sottoinsieme di immagini in cui il primo modello ha rilevato un problema.
Questo è anche un buon metodo per ridurre i costi, in quanto si evita di eseguire il secondo modello sull’intero set di immagini, limitandosi al sottoinsieme più significativo.
Le funzioni AWS Lambda gestiscono tutte queste elaborazioni tramite codice Python o Javascript. L’implementazione dipende dalla natura dei processi e dal numero di funzioni AWS Lambda che è necessario includere in un flusso. Il limite di 15 minuti per la durata massima di una chiamata lambda AWS determina il numero di fasi che il processo può contenere.
Conclusioni
Lavorare con i modelli di machine learning nel cloud è un’attività stimolante. Per affrontare questo compito, è necessario un team con una vasta gamma di competenze.
Il team deve saper addestrare un modello, sia pre-costruito che creato da zero. Ciò implica una buona conoscenza della matematica e dell’algebra per bilanciare l’affidabilità e le prestazioni dei risultati.
Sono inoltre necessarie competenze avanzate di programmazione in Python o Javascript, nonché competenze in database e SQL. Dopo che il lavoro sui contenuti è stato completato, servono competenze DevOps per collegare il tutto a una pipeline che automatizzi la distribuzione e l’esecuzione.
Definire l’anomalia e addestrare il modello è solo una parte del lavoro. La vera sfida è integrare tutte queste attività in un unico team funzionale in grado di elaborare i risultati dei modelli e salvare i dati in modo efficace e automatizzato, per renderli accessibili agli utenti finali.
Per approfondire l’argomento, consulta le nostre risorse sul riconoscimento facciale per le aziende.