

La regressione e la classificazione sono due delle aree più fondamentali e significative dell’apprendimento automatico.
Può essere complicato distinguere tra algoritmi di regressione e classificazione quando si sta entrando nell’apprendimento automatico. Capire come funzionano questi algoritmi e quando utilizzarli può essere cruciale per fare previsioni accurate e decisioni efficaci.
Innanzitutto, vediamo l’apprendimento automatico.
Sommario:
Cos’è l’apprendimento automatico?
L’apprendimento automatico è un metodo per insegnare ai computer a imparare e prendere decisioni senza essere esplicitamente programmati. Implica l’addestramento di un modello informatico su un set di dati, consentendo al modello di effettuare previsioni o decisioni basate su modelli e relazioni nei dati.
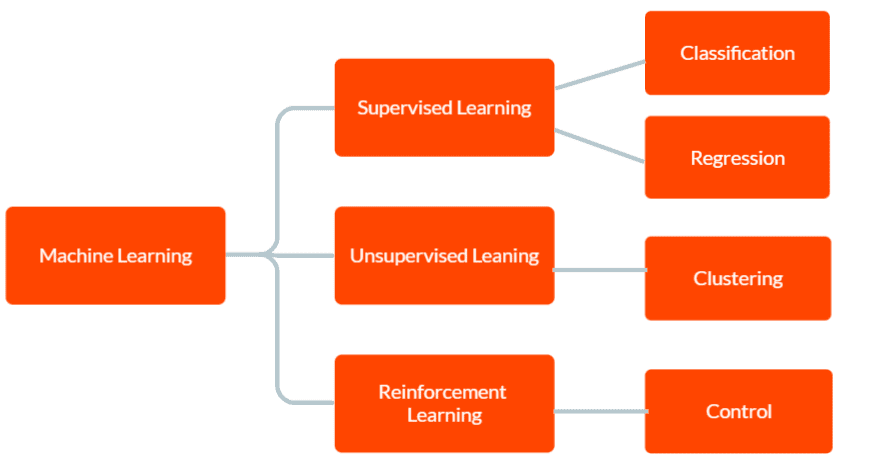
Esistono tre tipi principali di apprendimento automatico: apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo.
Nell’apprendimento supervisionato, il modello viene fornito con dati di addestramento etichettati, inclusi i dati di input e l’output corretto corrispondente. L’obiettivo è che il modello esegua previsioni sull’output per dati nuovi e invisibili in base ai modelli appresi dai dati di addestramento.
In Apprendimento non supervisionato, al modello non vengono forniti dati di addestramento etichettati. Invece, è lasciato scoprire modelli e relazioni nei dati in modo indipendente. Questo può essere utilizzato per identificare gruppi o cluster nei dati o per trovare anomalie o modelli insoliti.
E in Reinforcement Learning, un agente impara a interagire con il suo ambiente per massimizzare una ricompensa. Implica l’addestramento di un modello per prendere decisioni in base al feedback che riceve dall’ambiente.
L’apprendimento automatico viene utilizzato in varie applicazioni, tra cui il riconoscimento di immagini e parole, l’elaborazione del linguaggio naturale, il rilevamento di frodi e le auto a guida autonoma. Ha il potenziale per automatizzare molte attività e migliorare il processo decisionale in vari settori.
Questo articolo si concentra principalmente sui concetti di classificazione e regressione, che rientrano nell’apprendimento automatico supervisionato. Iniziamo!
Classificazione nell’apprendimento automatico

La classificazione è una tecnica di apprendimento automatico che implica l’addestramento di un modello per assegnare un’etichetta di classe a un dato input. È un’attività di apprendimento supervisionato, il che significa che il modello viene addestrato su un set di dati etichettato che include esempi dei dati di input e le etichette di classe corrispondenti.
Il modello ha lo scopo di apprendere la relazione tra i dati di input e le etichette di classe per prevedere l’etichetta di classe per input nuovi e invisibili.
Esistono molti algoritmi diversi che possono essere utilizzati per la classificazione, tra cui regressione logistica, alberi decisionali e macchine vettoriali di supporto. La scelta dell’algoritmo dipenderà dalle caratteristiche dei dati e dalle prestazioni desiderate del modello.
Alcune applicazioni di classificazione comuni includono il rilevamento dello spam, l’analisi del sentiment e il rilevamento delle frodi. In ciascuno di questi casi, i dati di input potrebbero includere testo, valori numerici o una combinazione di entrambi. Le etichette di classe possono essere binarie (ad esempio, spam o non spam) o multi-classe (ad esempio, sentimento positivo, neutro, negativo).
Ad esempio, considera un set di dati di recensioni dei clienti di un prodotto. I dati di input potrebbero essere il testo della recensione e l’etichetta della classe potrebbe essere una valutazione (ad esempio, positiva, neutra, negativa). Il modello verrebbe addestrato su un set di dati di recensioni etichettate e quindi sarebbe in grado di prevedere la valutazione di una nuova recensione che non aveva visto prima.
Tipi di algoritmi di classificazione ML
Esistono diversi tipi di algoritmi di classificazione nell’apprendimento automatico:
Regressione logistica
Questo è un modello lineare utilizzato per la classificazione binaria. Viene utilizzato per prevedere la probabilità che si verifichi un determinato evento. L’obiettivo della regressione logistica è trovare i migliori coefficienti (pesi) che minimizzino l’errore tra la probabilità prevista e il risultato osservato.
Questo viene fatto utilizzando un algoritmo di ottimizzazione, come la discesa del gradiente, per regolare i coefficienti fino a quando il modello si adatta ai dati di addestramento nel miglior modo possibile.
Alberi decisionali
Questi sono modelli ad albero che prendono decisioni in base ai valori delle caratteristiche. Possono essere utilizzati sia per la classificazione binaria che multiclasse. Gli alberi decisionali presentano numerosi vantaggi, tra cui la semplicità e l’interoperabilità.
Sono anche veloci da addestrare e fare previsioni e possono gestire sia dati numerici che categorici. Tuttavia, possono essere soggetti a sovradimensionamento, soprattutto se l’albero è profondo e ha molti rami.
Classificazione forestale casuale
Random Forest Classification è un metodo di ensemble che combina le previsioni di più alberi decisionali per fare una previsione più accurata e stabile. È meno incline all’overfitting rispetto a un singolo albero decisionale perché viene calcolata la media delle previsioni dei singoli alberi, il che riduce la varianza nel modello.
Ada Boost
Questo è un algoritmo di potenziamento che modifica in modo adattivo il peso degli esempi classificati erroneamente nel set di addestramento. Viene spesso utilizzato per la classificazione binaria.
Bayes ingenuo
Naïve Bayes si basa sul teorema di Bayes, che è un modo per aggiornare la probabilità di un evento sulla base di nuove prove. È un classificatore probabilistico spesso utilizzato per la classificazione del testo e il filtraggio dello spam.
K-vicino più prossimo
K-Nearest Neighbors (KNN) viene utilizzato per attività di classificazione e regressione. È un metodo non parametrico che classifica un punto dati in base alla classe dei suoi vicini più vicini. KNN ha diversi vantaggi, tra cui la sua semplicità e il fatto che è facile da implementare. Può anche gestire dati sia numerici che categorici e non fa alcuna ipotesi sulla distribuzione dei dati sottostanti.
Aumento del gradiente
Questi sono insiemi di studenti deboli che vengono addestrati in sequenza, con ogni modello che cerca di correggere gli errori del modello precedente. Possono essere utilizzati sia per la classificazione che per la regressione.
Regressione nell’apprendimento automatico
Nell’apprendimento automatico, la regressione è un tipo di apprendimento supervisionato in cui l’obiettivo è prevedere una variabile dipendente da una o più caratteristiche di input (chiamate anche predittori o variabili indipendenti).
Gli algoritmi di regressione vengono utilizzati per modellare la relazione tra gli input e l’output e fare previsioni basate su tale relazione. La regressione può essere utilizzata sia per le variabili dipendenti continue che per quelle categoriali.
In generale, l’obiettivo della regressione è costruire un modello in grado di prevedere con precisione l’output in base alle funzionalità di input e comprendere la relazione sottostante tra le funzionalità di input e l’output.
L’analisi di regressione viene utilizzata in vari campi, tra cui economia, finanza, marketing e psicologia, per comprendere e prevedere le relazioni tra diverse variabili. È uno strumento fondamentale nell’analisi dei dati e nell’apprendimento automatico e viene utilizzato per fare previsioni, identificare tendenze e comprendere i meccanismi sottostanti che guidano i dati.
Ad esempio, in un semplice modello di regressione lineare, l’obiettivo potrebbe essere quello di prevedere il prezzo di una casa in base alle sue dimensioni, posizione e altre caratteristiche. La dimensione della casa e la sua posizione sarebbero le variabili indipendenti, e il prezzo della casa sarebbe la variabile dipendente.
Il modello verrebbe addestrato sui dati di input che includono le dimensioni e l’ubicazione di diverse case, insieme ai prezzi corrispondenti. Una volta che il modello è stato addestrato, può essere utilizzato per fare previsioni sul prezzo di una casa, date le dimensioni e l’ubicazione.
Tipi di algoritmi di regressione ML
Gli algoritmi di regressione sono disponibili in varie forme e l’utilizzo di ciascun algoritmo dipende dal numero di parametri, come il tipo di valore dell’attributo, il modello della linea di tendenza e il numero di variabili indipendenti. Le tecniche di regressione che vengono spesso utilizzate includono:
Regressione lineare
Questo semplice modello lineare viene utilizzato per prevedere un valore continuo basato su un insieme di caratteristiche. Viene utilizzato per modellare la relazione tra le caratteristiche e la variabile target adattando una linea ai dati.
Regressione polinomiale
Si tratta di un modello non lineare utilizzato per adattare una curva ai dati. Viene utilizzato per modellare le relazioni tra le caratteristiche e la variabile target quando la relazione non è lineare. Si basa sull’idea di aggiungere termini di ordine superiore al modello lineare per catturare le relazioni non lineari tra le variabili dipendenti e indipendenti.
Regressione della cresta
Questo è un modello lineare che affronta l’overfitting nella regressione lineare. È una versione regolarizzata della regressione lineare che aggiunge un termine di penalità alla funzione di costo per ridurre la complessità del modello.
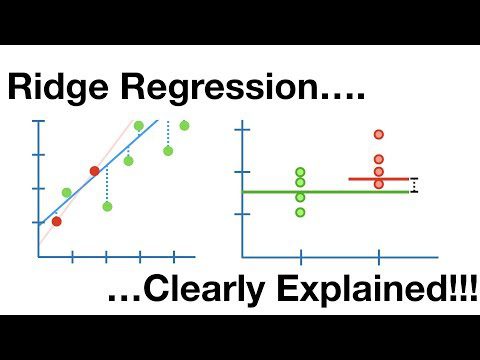
Supporta la regressione vettoriale
Come le SVM, la Support Vector Regression è un modello lineare che cerca di adattare i dati trovando l’iperpiano che massimizza il margine tra le variabili dipendenti e indipendenti.
Tuttavia, a differenza degli SVM, utilizzati per la classificazione, SVR viene utilizzato per le attività di regressione, in cui l’obiettivo è prevedere un valore continuo piuttosto che un’etichetta di classe.
Regressione del lazo
Questo è un altro modello lineare regolarizzato utilizzato per prevenire l’overfitting nella regressione lineare. Aggiunge un termine di penalità alla funzione di costo basato sul valore assoluto dei coefficienti.
Regressione lineare bayesiana
La regressione lineare bayesiana è un approccio probabilistico alla regressione lineare basato sul teorema di Bayes, che è un modo per aggiornare la probabilità di un evento sulla base di nuove prove.
Questo modello di regressione mira a stimare la distribuzione a posteriori dei parametri del modello dati i dati. Questo viene fatto definendo una distribuzione a priori sui parametri e quindi utilizzando il teorema di Bayes per aggiornare la distribuzione in base ai dati osservati.
Regressione contro classificazione
La regressione e la classificazione sono due tipi di apprendimento supervisionato, il che significa che vengono utilizzati per prevedere un output in base a un insieme di funzionalità di input. Tuttavia, ci sono alcune differenze fondamentali tra i due:
RegressioneClassificazioneDefinizioneUn tipo di apprendimento supervisionato che prevede un valore continuoUn tipo di apprendimento supervisionato che prevede un valore categoricoTipo di outputContinuoDiscretoMetriche di valutazioneErrore quadratico medio (MSE), errore quadratico medio (RMSE)Accuratezza, precisione, richiamo, punteggio F1AlgoritmiRegressione lineare, Lazo, Ridge, KNN, Albero delle decisioniRegressione logistica, SVM, Naïve Bayes, KNN, Albero delle decisioniComplessità del modelloModelli meno complessiModelli più complessiPresuppostiRelazione lineare tra caratteristiche e obiettivoNessun presupposto specifico sulla relazione tra caratteristiche e obiettivoSquilibrio della classeNon applicabilePuò essere un problemaValori anomaliPuò influire sulle prestazioni del modelloDi solito non è un problemaImportanza della caratteristicaLe caratteristiche sono classificate in base all’importanzaCaratteristiche non sono classificati in base all’importanzaApplicazioni di esempioPrevisione di prezzi, temperature, quantitàPrevisione se spam e-mail, previsione del tasso di abbandono dei clienti
Risorse di apprendimento
Potrebbe essere difficile scegliere le migliori risorse online per comprendere i concetti di machine learning. Abbiamo esaminato i corsi popolari forniti da piattaforme affidabili per presentarti i nostri consigli per i migliori corsi ML su regressione e classificazione.
#1. Bootcamp di classificazione dell’apprendimento automatico in Python
Questo è un corso offerto sulla piattaforma Udemy. Copre una varietà di algoritmi e tecniche di classificazione, inclusi alberi decisionali e regressione logistica, e supporta macchine vettoriali.

Puoi anche conoscere argomenti come l’overfitting, il compromesso bias-variance e la valutazione del modello. Il corso utilizza librerie Python come sci-kit-learn e panda per implementare e valutare modelli di machine learning. Quindi, per iniziare con questo corso è necessaria una conoscenza di base di Python.
#2. Masterclass sulla regressione dell’apprendimento automatico in Python
In questo corso Udemy, il trainer copre le basi e la teoria alla base di vari algoritmi di regressione, tra cui la regressione lineare, la regressione polinomiale e le tecniche di regressione Lasso & Ridge.
Alla fine di questo corso, sarai in grado di implementare algoritmi di regressione e valutare le prestazioni di modelli di apprendimento automatico addestrati utilizzando vari indicatori di prestazioni chiave.
Avvolgendo
Gli algoritmi di apprendimento automatico possono essere molto utili in molte applicazioni e possono aiutare ad automatizzare e semplificare molti processi. Gli algoritmi ML utilizzano tecniche statistiche per apprendere modelli nei dati e fare previsioni o decisioni basate su tali modelli.
Possono essere addestrati su grandi quantità di dati e possono essere utilizzati per eseguire attività che sarebbero difficili o dispendiose in termini di tempo per gli esseri umani da eseguire manualmente.
Ogni algoritmo ML ha i suoi punti di forza e di debolezza e la scelta dell’algoritmo dipende dalla natura dei dati e dai requisiti dell’attività. È importante scegliere l’algoritmo o la combinazione di algoritmi appropriati per il problema specifico che si sta tentando di risolvere.
È importante scegliere il giusto tipo di algoritmo per il tuo problema, poiché l’utilizzo del tipo sbagliato di algoritmo può portare a scarse prestazioni e previsioni imprecise. Se non sei sicuro di quale algoritmo utilizzare, può essere utile provare sia gli algoritmi di regressione che quelli di classificazione e confrontarne le prestazioni sul set di dati.
Spero che questo articolo ti sia stato utile per imparare la regressione rispetto alla classificazione nell’apprendimento automatico. Potresti anche essere interessato a conoscere i migliori modelli di Machine Learning.