

È ora di scegliere la migliore opzione di database serverless che si adatta meglio alla tua applicazione moderna.
Serverless Database è stato specificamente progettato per gestire carichi di lavoro imprevedibili che possono cambiare rapidamente. Di conseguenza, molte organizzazioni hanno adottato l’architettura serverless per creare moderne architetture basate sugli eventi. Ciò ha visto un aumento della popolarità all’interno dell’ecosistema delle tecnologie serverless.
Sommario:
Introduzione al database senza server
L’elaborazione senza server richiede un database senza server. Questi database sono specificamente progettati per gestire carichi di lavoro imprevedibili che possono cambiare rapidamente. Cosa c’è di più?
Puoi pagare solo per le risorse del database che utilizzi al secondo. Inoltre, i database cloud come Amazon Aurora, compatibili con MySQL e PostgreSQL, possono essere completamente gestiti e scalati fino a 64 TB.
Questo database può essere creato scegliendo la dimensione dell’istanza. Funziona bene quando c’è un carico di lavoro, una frequenza di richiesta e requisiti di elaborazione prevedibili.
Può essere difficile organizzare la giusta quantità di capacità nei casi in cui il carico di lavoro è imprevedibile e c’è un volume elevato di richieste per pochi minuti ogni settimana o un giorno. Tuttavia, potrebbe non essere l’opzione migliore pagarla su base continuativa.
È qui che entra in gioco il database serverless.
Funzionalità di database senza server

Ecco le caratteristiche principali dei Database Serverless:
- Accesso in tempo reale: l’accesso ai tuoi dati è disponibile a un buon livello. Indicizza automaticamente i dati e li rende immediatamente disponibili. Ciò ti consente di interrogare, leggere, aggiornare e aggiungere elementi al tuo database serverless in modo costante. Cosa c’è di più? Sarai in grado di accedervi istantaneamente tramite le funzioni.
- Scalabilità infinita: puoi aumentare o diminuire le dimensioni dei database serverless in qualsiasi momento. Si avviano e si chiudono in base alle esigenze dell’applicazione. Ridimensionerà le unità di calcolo (ACU nel caso di Aurora Serverless) per gestire le tue query, leggere e scrivere nello stesso cluster di dati. Questa automazione ti consentirà di eseguire tutte le tue funzioni contemporaneamente e garantire che i tuoi dati rimangano coerenti.
- Elevata sicurezza: le applicazioni moderne possono essere esposte a utenti malintenzionati e non attendibili su scala globale. Assicura che ogni applicazione che interagisce con lo stesso database passi lo stesso protocollo di controllo degli accessi. Riduce la superficie di attacco, che rappresenta un rischio cruciale per le aziende.
- Disponibilità: il database senza server offre la possibilità di ridurre la latenza. Questo approccio consente all’utente di leggere i dati delle funzioni guidate dagli eventi.
- Schemaless: Schemaless ti consente di gestire tutti gli output di dati dalle tue funzioni. È facile integrare il database serverless con le tue funzioni utilizzando questo approccio “gestisci tutto”. Questa è una caratteristica unica nei database Serverless.
Ora esploriamo alcuni dei migliori database serverless per le applicazioni moderne.
Fauna
Fauna è un database distribuito e senza server. Fauna offre un’estrema flessibilità. È possibile regolare diversi parametri per soddisfare le esigenze del progetto. Fauna può essere utilizzato come valore-chiave, grafico, database relazionale basato su documenti o tradizionale. Puoi creare uno schema o liberare i dati.
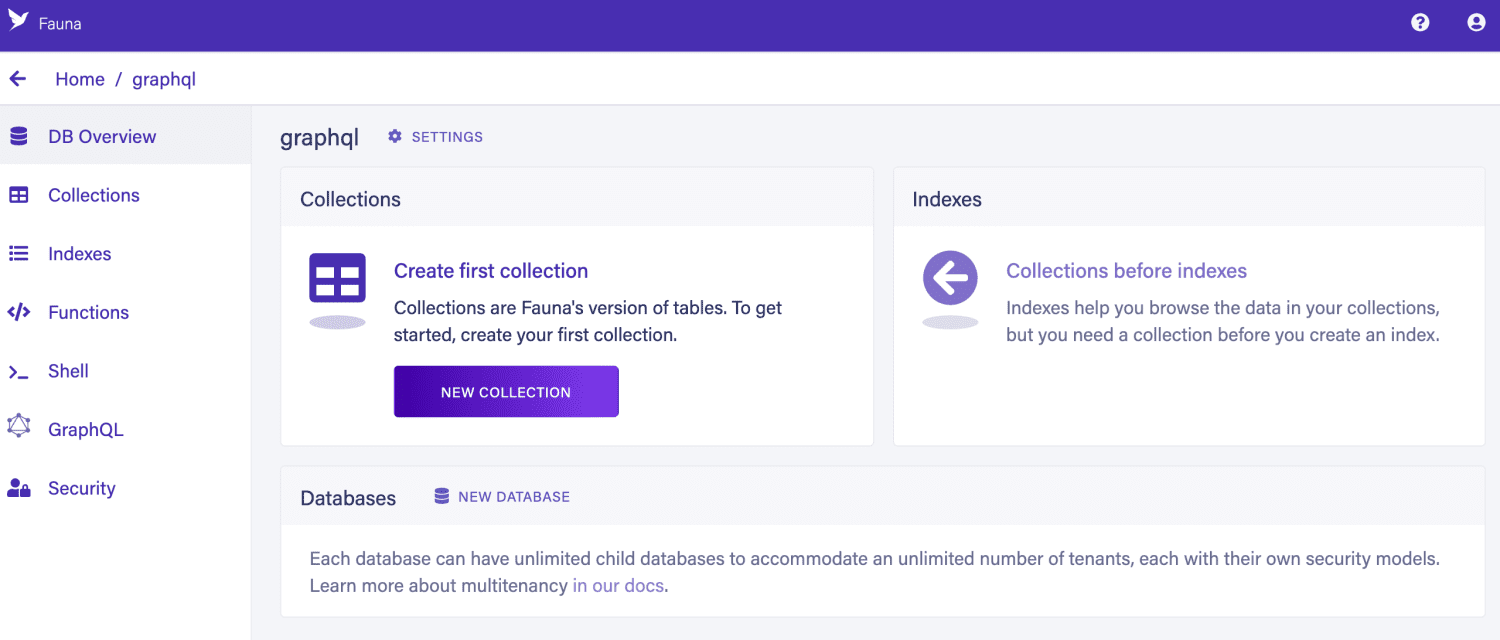
È estremamente versatile. Fauna può essere eseguito nel cloud, in locale o incorporato nella nostra applicazione. Offre inoltre le opzioni di distribuzione più popolari come le immagini della macchina o le immagini della finestra mobile. Questa applicazione può essere eseguita a velocità molto elevate e funziona bene con le transazioni ACID.
Aurora Amazzonica
Amazon Aurora è un servizio di archiviazione dati relazionale a cui è possibile accedere dal cloud Amazon. Questo servizio è ampiamente utilizzato per l’archiviazione dei dati. Consente l’archiviazione dei dati basata sul valore a bassa latenza.
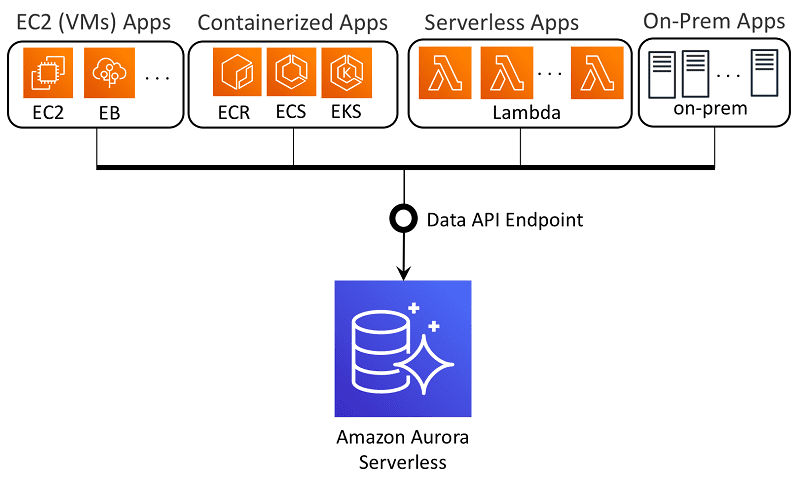 Credito immagine: AWS
Credito immagine: AWS
Amazon Aurora è un database relazionale compatibile con PostgreSQL e MySQL che consolida l’accessibilità e le prestazioni dei database tradizionali con l’affidabilità e la semplicità dei database commerciali a 1/10 del costo. Utilizza un approccio in cluster alla replica dei dati nella zona di accessibilità di AWS per un’efficiente disponibilità dei dati.
Amazon Aurora ha molti sottosistemi ad alte prestazioni. Lo storage distribuito più veloce viene utilizzato dai motori MySQL e PostgreSQL. Aurora accelera il throughput e le prestazioni di MySQL rispettivamente di 5 volte e 3 volte rispetto al sistema attuale.
Il database può essere scalato fino a 64 terabyte, fornendo supporto per l’implementazione aziendale. Amazon Aurora è completamente gestito da Amazon Relational Database Service (RDS), che automatizza le attività amministrative come il provisioning dell’hardware, la disposizione dei dati, la correzione, i rinforzi e altro ancora.
Bit.io
bit.io ti consente di configurare rapidamente e facilmente un database PostgreSQL. Trascina e rilascia i file per caricare i dati in un database PostgreSQL. Puoi anche inserire un URL per un file, inviare dati da R o Python o utilizzare qualsiasi altro client Postgres/HTTP.
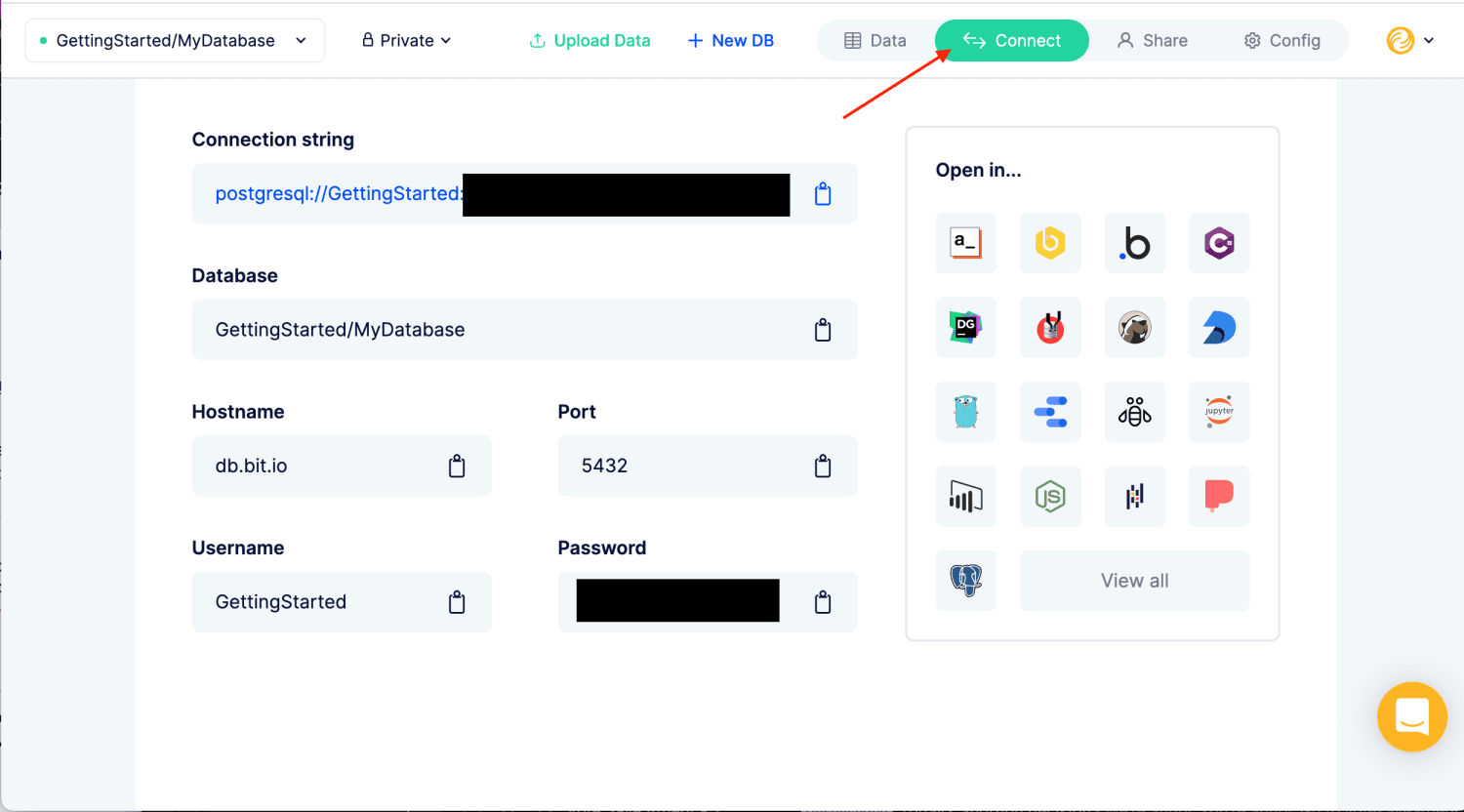
L’editor SQL nel browser ti consente di lavorare con i dati utilizzando uno qualsiasi dei tuoi strumenti di analisi dei dati preferiti, inclusi client SQL, notebook R e Python, riga di comando e molti altri.
bit.io fornisce un database PostgreSQL completo. Può essere utilizzato rapidamente e praticamente senza alcuna configurazione. Si integra inoltre con un numero crescente di strumenti di dati. bit.io funzionerà con qualsiasi strumento che supporti PostgreSQL.
Upstash
Upstash, un database cloud di memoria senza server creato da Upstash Inc (una società con sede in California). Può essere utilizzato come livello di memorizzazione nella cache o come database. Non richiede la gestione di cluster o server di database. È completamente senza server.
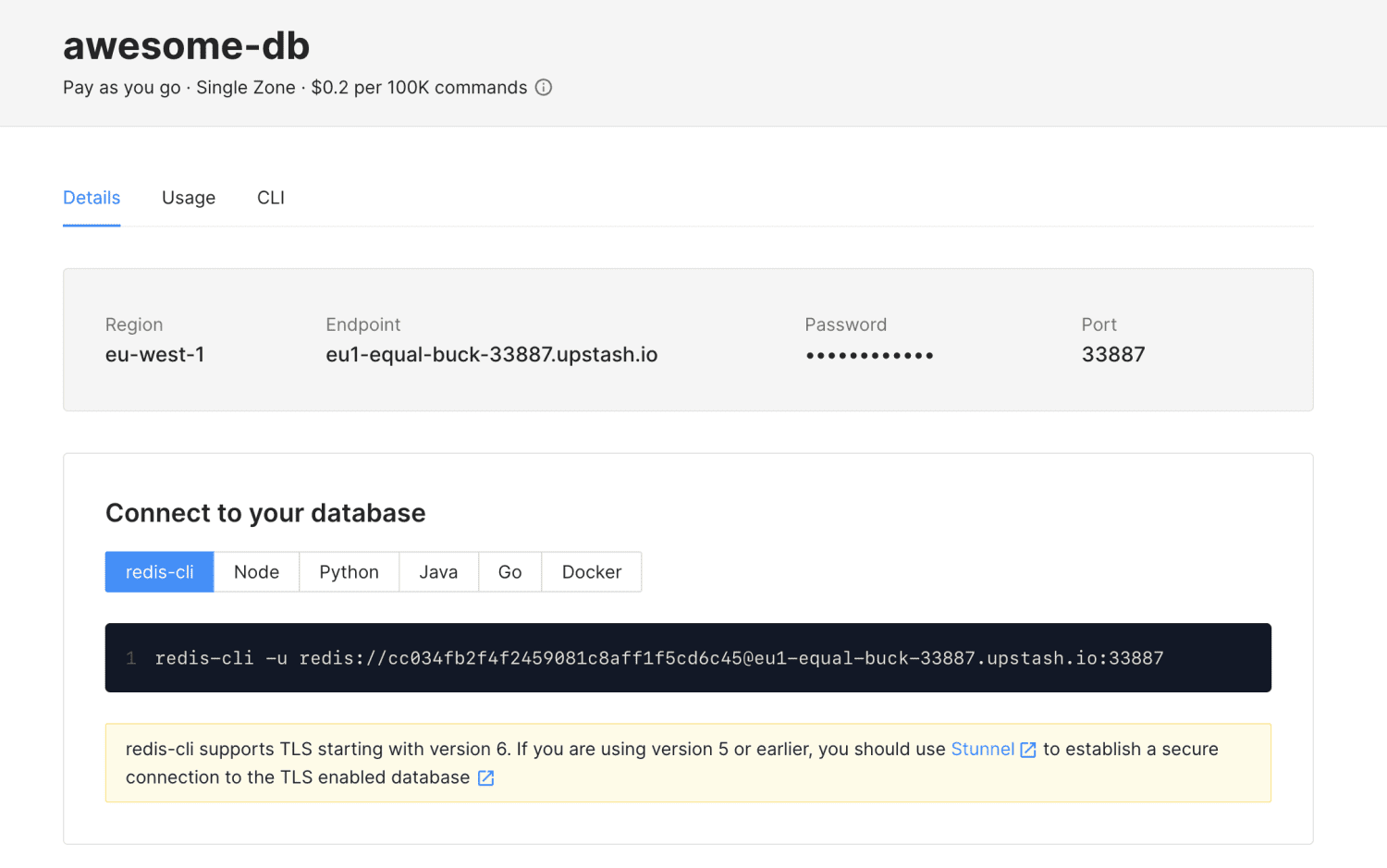
Ecco perché le tecnologie Serverless come Upstash sono così utili. Upstash non addebita nulla se non lo usi. Upstash può essere utilizzato per casi d’uso popolari di Redis come:
- Cache generale
- Cache della sessione
- Classifiche
- Code
- Misurazione dell’utilizzo (conteggio)
- Filtraggio dei contenuti
Caratteristiche
- Progettato per serverless
- Paga mentre vai
- Bassa latenza
- Stoccaggio durevole e veloce
Xata
Xata, un database senza server, dispone di potenti funzionalità di ricerca e analisi integrate. Xata utilizza un modello di database relazionale con uno schema rigoroso (schema) e supporta oggetti simili a JSON. I record sono organizzati in tabelle che vengono poi raggruppate in database.
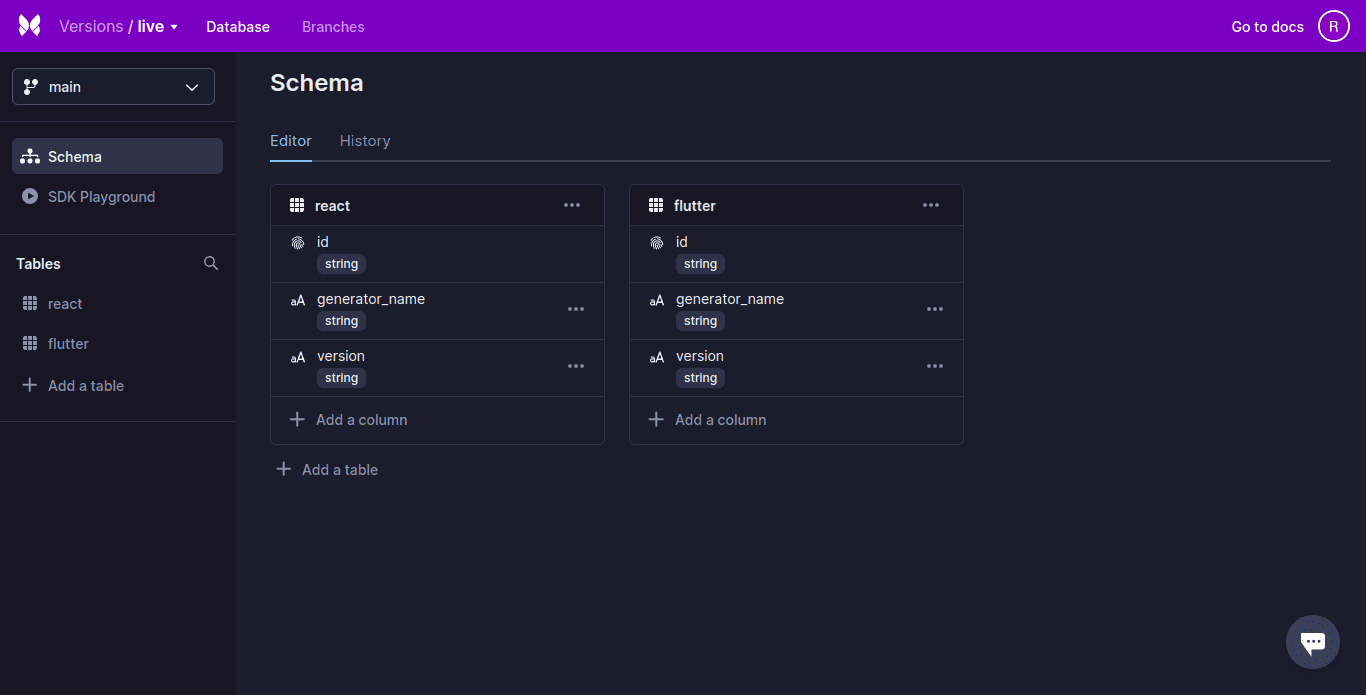
Xata supporta le colonne ricche e le relazioni tra le tabelle possono essere rappresentate utilizzando le colonne di collegamento. Questi sono simili alla chiave esterna.
Xata, un nuovo tipo di servizio cloud, offre un livello di astrazione oltre a più archivi di dati per semplificare lo sviluppo e il funzionamento delle applicazioni. Questo tipo di servizio è chiamato Serverless Data Platform. Questo documento può essere utilizzato per aiutarti a replicare l’architettura, che ti darà alcuni dei vantaggi dell’utilizzo di Xata.
SurrealDB
SurrealDB, un database cloud NewSQL innovativo, può essere utilizzato per applicazioni serverless, jamstack, a pagina singola, tradizionali e serverless. Offre flessibilità e valore finanziario senza pari. Può essere distribuito in ambienti di elaborazione on-premise, embedded o edge, oltre a poter essere distribuito sul cloud.
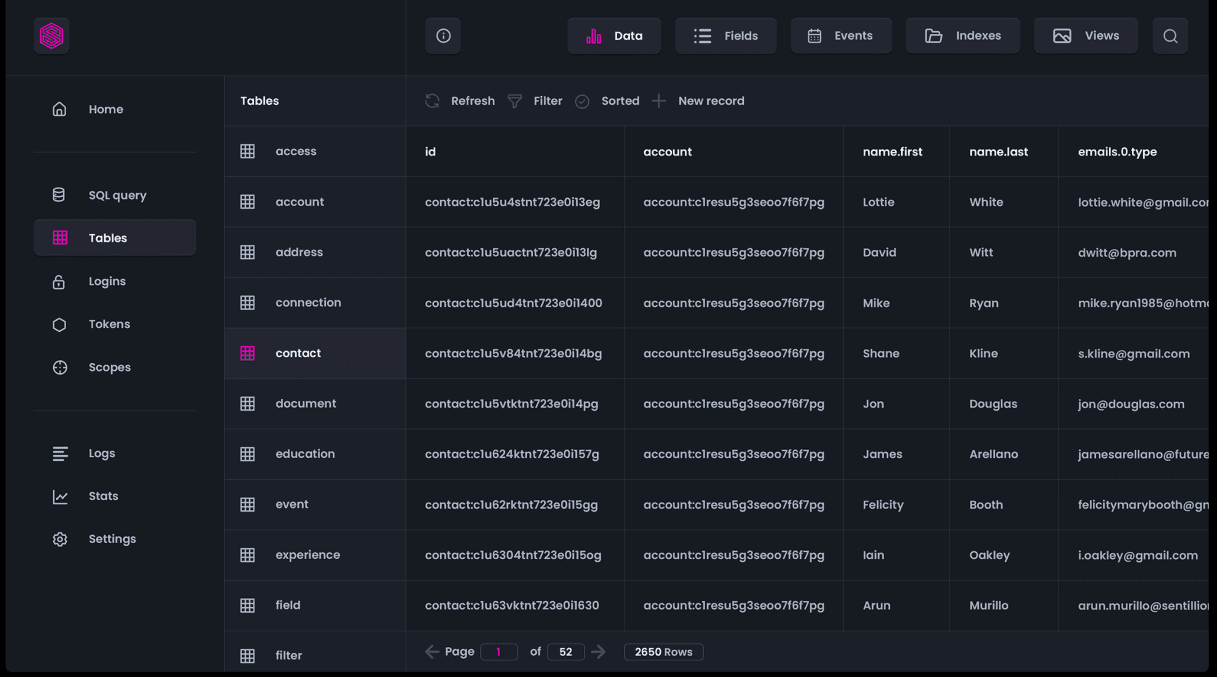
Il tuo team non ha bisogno di essere fluente in complessi linguaggi di database. Anche le funzionalità avanzate sono semplici e dirette, ma comunque veloci e performanti. Puoi dimenticarti di ridimensionare server, database, sistemi di bilanciamento del carico ed endpoint API.
SurrealDB rimuove la complessità dal tuo stack e ti consente di scalare con una piattaforma distribuita e altamente disponibile. SurrealDB Cloud ti consente di implementare ovunque.
CosmoDB
Azure Cosmos DB, un database distribuito globale basato su JSON, è disponibile come “Platform as a Service (PaaS) in Microsoft Azure. Consente agli utenti di creare e distribuire automaticamente applicazioni nei data center di Azure senza configurazione.
Fa parte di Azure ed è disponibile in tutte le aree. Inoltre, replica i dati su più data center nella rete.
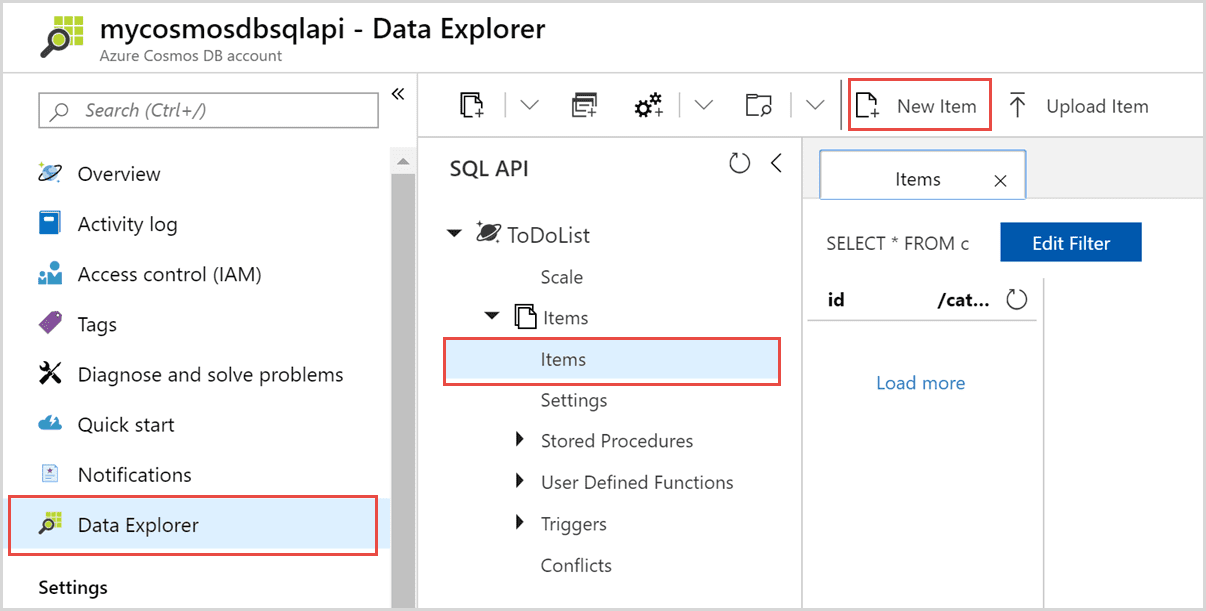
Sono disponibili molte interfacce, la più interessante delle quali è basata su SQL. CosmosDB è il servizio ideale per le organizzazioni che elaborano, interrogano e gestiscono molte informazioni importanti e di breve durata.
ScarafaggioDB
CockroachDB, un database SQL distribuito costruito su un valore-chiave coerente e un archivio transazionale, è chiamato CockroachDB.
È scritto in Go ed è completamente open-source. I suoi obiettivi principali includono il supporto delle transazioni ACID, il ridimensionamento orizzontale e la sopravvivenza. Mira a tollerare qualsiasi cosa, dal guasto di un singolo disco a un’intera operazione di ripristino di emergenza, senza alcun intervento manuale e con interruzioni di latenza minime.
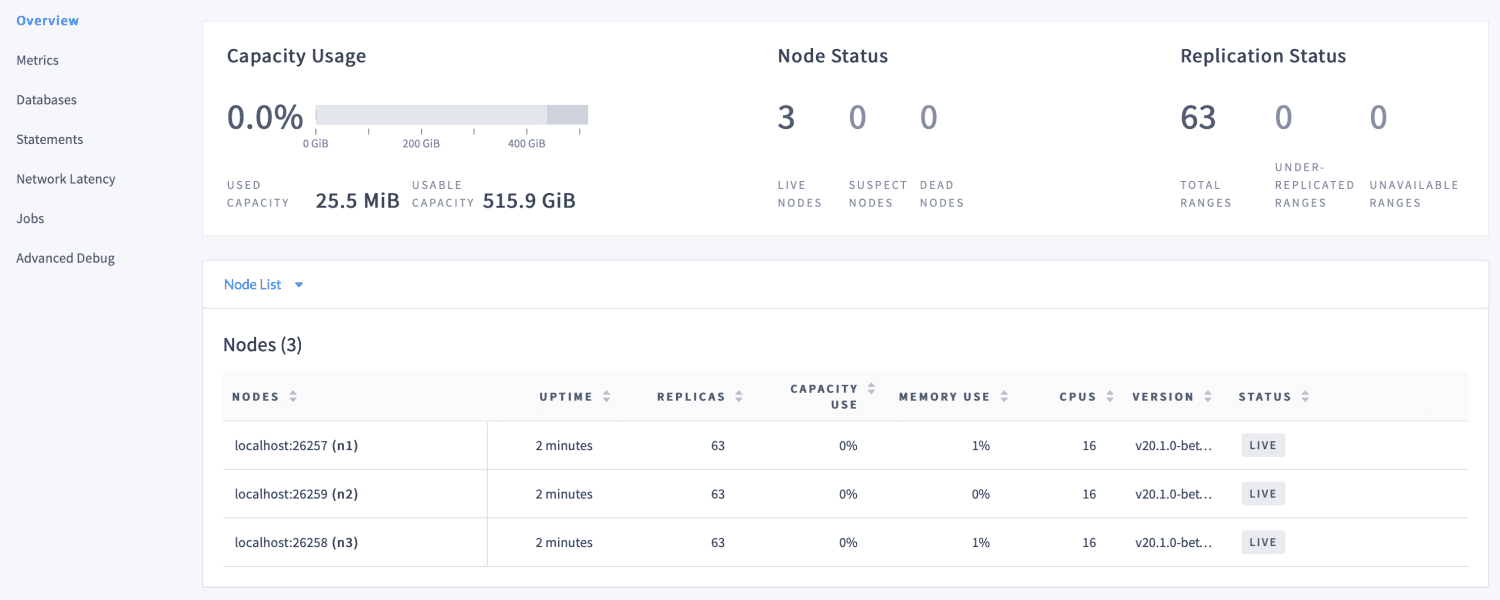
CockroachDB è una buona scelta per le applicazioni che necessitano di dati affidabili, accurati e disponibili su tutte le scale. Puoi accedere all’interfaccia utente di amministrazione, che viene fornita in bundle con CockroachDB all’indirizzo http://localhost:8080 non appena il cluster è attivo e funzionante.
Fornisce informazioni sulla configurazione del cluster e del database e ci assiste nell’ottimizzazione delle prestazioni del cluster monitorando metriche come integrità, metriche di runtime, replica e dettagli del nodo.
PlanetScale
PlanetScale, una nuova piattaforma DBaaS, ti consente di avviare rapidamente un database senza alcuna gestione della connessione. I database PlanetScale sono stati progettati per gli sviluppatori e i loro flussi di lavoro. Puoi implementare un database completamente gestito che ha l’affidabilità e la flessibilità di MySQL. I loro database sono basati su MySQL 8.0.
PlanetScale offre due tipi di rami di database: produzione e sviluppo. La sua funzione di ramificazione ti consente di trattare i tuoi database come codice. È possibile creare un ramo dallo schema del database di produzione che verrà utilizzato per ambienti di sviluppo isolati.
Conclusione
Quindi si trattava dei migliori database serverless per le applicazioni moderne. I database serverless, e in particolare Amazon Aurora Serverless, sono un futuro promettente. Perché ora possiamo concentrarci sugli elementi essenziali dell’accesso in tempo reale ai dati, sulla scalabilità e sulla sicurezza con questa nuova tecnologia.
Potresti anche essere interessato a 7 modi in cui il serverless computing è una tecnologia in crescita.