
I dati sono la linfa vitale di qualsiasi azienda. È la chiave del successo ed è essenziale per raccogliere informazioni, prendere decisioni e migliorare le operazioni.
Un’azienda fa affidamento sui propri dati e applicazioni per operare ogni giorno. Ma cosa succede quando uno dei loro database o sistemi fallisce?
Tutte le informazioni e i dati aziendali critici potrebbero essere a rischio.
Fortunatamente, ci sono modi per evitare che ciò accada. Uno dei metodi più efficaci per proteggere i dati aziendali è la replica del database. È qualcosa che ogni piccola, media e grande impresa deve adattarsi per sopravvivere alla concorrenza.
In questo articolo, parlerò di cos’è la replica dei dati, di come funziona e di altri aspetti importanti.
Quindi iniziamo!
Sommario:
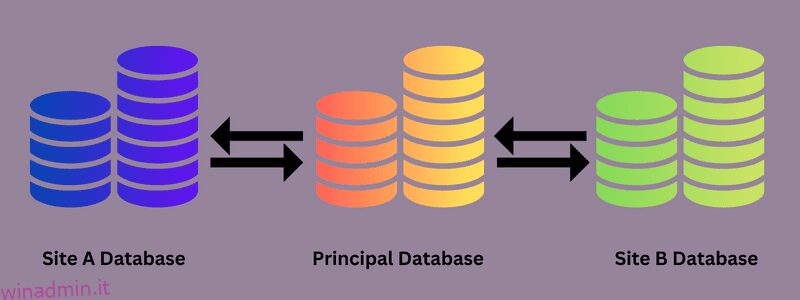
Che cos’è la replica del database?
Il trasferimento di dati da un database di origine a uno o più database di destinazione è noto come replica del database. Spesso comporta la copia o lo streaming di dati da un database a un altro in modo che tutti gli utenti possano accedere ai dati sincronizzati indipendentemente dal sistema utilizzato per visualizzarli.
Se i dati vengono modificati, uno strumento di replica dei dati assicurerà che le modifiche vengano implementate anche nel database di destinazione. Di conseguenza, viene creata una rete di archiviazione dei dati distribuita con una maggiore disponibilità in più sedi, consentendo a tutti di accedere rapidamente a dati vitali e rilevanti.
Utilizzando una soluzione di replica dei dati, è probabile che si notino un miglioramento della coerenza dei dati in ogni nodo, una riduzione della ridondanza dei dati, un’affidabilità dei dati più significativa e, infine, un aumento delle prestazioni.
La replica del database può avvenire in tempo reale, poiché i dati vengono creati, modificati e distrutti nel database di origine o come parte di un’operazione batch.
Come funziona la replica dei dati?
La replica del database può essere eseguita una sola volta o come processo continuo. Coinvolge tutte le fonti di dati di un’organizzazione e un sistema di gestione di database distribuito (DDBMS) viene utilizzato per trasferire o distribuire i dati a tutte le fonti.
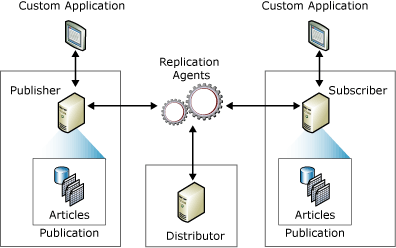
Eventuali modifiche, aggiunte ed eliminazioni apportate al database di origine vengono automaticamente sincronizzate con gli altri database di destinazione, se tali modifiche sono necessarie. Secondo il paradigma software convenzionale Publisher-Subscriber, uno o più “editori” e “abbonati” sono coinvolti nel processo di replica dei dati.
 Credito immagine: Microsoft
Credito immagine: Microsoft
Un “editore” è un sistema o il database di origine su cui vengono apportate modifiche e un “abbonato” è un sistema su cui vengono replicate le modifiche.
Qualsiasi modifica eseguita su un sistema “editore” viene quindi replicata nei database “abbonato”. Gli utenti possono anche apportare modifiche nei database degli abbonati, che vengono quindi replicati nel database dell’editore. Questo distribuisce le modifiche a tutti gli altri abbonati nella rete se il sistema è bidirezionale.
Inoltre, la maggior parte degli abbonati ha un collegamento fisso con l’editore, consentendo modifiche o aggiornamenti automatici senza intervento manuale. Questi aggiornamenti possono avvenire in batch a intervalli regolari oppure possono essere attivati e applicati in tempo reale.
Tipi di replica del database
Alcuni dei tipi di replica del database sono:
#1. Replica di tabelle complete
La replica della tabella completa crea una copia del database di origine completo nell’archivio di destinazione. Sposta le righe dall’editore all’abbonato, incluse le righe nuove, modificate ed esistenti.
Tuttavia, questo approccio di replica è associato a un elevato costo di manutenzione a causa della potenza di calcolo e dei requisiti di larghezza di banda della rete necessari per copiare tutto. Sforza la rete e può creare ritardi di replica, specialmente quando il volume di dati è maggiore.
#2. Replica di istantanee
Uno snapshot del database di origine viene utilizzato in questa replica del database per replicare i dati nel database di destinazione di destinazione. Non considera le modifiche ai dati come nuove, aggiornate o cancellate; invece, crea una copia di ciò che raccoglie in quel momento.
Quando le modifiche ai dati sono molto poche, questa tecnica di replica è preferibile. È significativamente più veloce della replica dell’intera tabella, ma non tiene traccia dei dati eliminati definitivamente.

#3. Unisci replica
La replica di tipo merge è un processo che trasferisce e distribuisce oggetti e dati del database da un database all’altro con la sincronizzazione del database. È complesso poiché questo processo consente agli abbonati e agli editori di modificare il database, causando frequenti conflitti di dati relativi alla versione.
Gli agenti di merge distribuiti sui server sincronizzano tutte le modifiche e seguono un processo di risoluzione dei conflitti predefinito per risolvere qualsiasi conflitto di dati.
#4. Replica incrementale basata su chiave
La replica incrementale basata su chiave controlla le chiavi o gli indici in un database per cercare modifiche come l’eliminazione, il nuovo e l’aggiornamento. Il meccanismo di replica copia quindi solo le chiavi di replica richieste nel database di replica per riflettere le modifiche dall’ultimo aggiornamento. Queste chiavi sono solitamente un timestamp, una data o un numero intero.
Poiché solo le modifiche indicate vengono replicate nel database di replica, il processo è più rapido. Sfortunatamente, questo metodo non abilita le eliminazioni definitive perché il valore critico viene rimosso cancellando il record del database primario.
#5. Replica incrementale basata su log
Questo tipo di replica del database duplica i dati in base al file di registro binario del database. Dopo aver ispezionato il file di registro binario, ti fornirà informazioni sulle modifiche apportate al database primario, ad esempio aggiornamenti, inserimenti o eliminazioni. Successivamente, le stesse modifiche o aggiornamenti vengono eseguiti nel database di destinazione.
Questo è uno dei metodi di replica dei dati più utilizzati in quanto è efficiente, soprattutto per i database statici. Inoltre, la maggior parte dei fornitori di database lo supporta, inclusi Oracle, MongoDB, MySQL e PostgreSQL.
#6. Replica transazionale
Quando c’è un nuovo sviluppo nei dati di origine, la replica transazionale sposta tutti i dati esistenti dal database di origine alla posizione di destinazione. Quindi esegue la stessa transazione nelle repliche.
Sebbene sia un metodo di replica efficiente, i modelli trovano utilizzo principalmente nelle attività di lettura e potrebbero non consentire operazioni di creazione, eliminazione o aggiornamento.
Perché è importante la replica dei database?

La replica del database è importante per i seguenti motivi:
Affidabilità e disponibilità dei dati
La replica dei dati promuove la disponibilità dei dati. Svolge un ruolo importante quando un server si guasta in circostanze insolite fornendo backup del database. In questo modo, può salvarti la giornata perché i dati sono disponibili in altre posizioni. Inoltre, migliora l’affidabilità dei dati mantenendo i dati pertinenti e più recenti salvati in modo sicuro in più server.
Ripristino di emergenza
La replica del database è utile durante uno scenario di errore del server. È una meravigliosa tecnica di gestione e ripristino dei disastri poiché replica e archivia i dati e le modifiche recenti in altre posizioni del server invece di fare affidamento su un singolo server.
Prestazioni del server
L’accesso ai dati è molto più veloce quando i dati vengono elaborati e gestiti su più server. Inoltre, gli amministratori possono liberare i cicli di elaborazione sul server originale per operazioni di scrittura che richiedono più risorse indirizzando tutte le operazioni di lettura dei dati a una replica.
Migliori prestazioni di rete
La conservazione di più copie degli stessi dati in posizioni diverse può ridurre la latenza di accesso ai dati perché è possibile recuperare i dati rilevanti dalla posizione in cui viene eseguita la transazione.
Ad esempio, gli utenti nei paesi europei potrebbero avvertire problemi di latenza durante l’accesso ai dati dai data center australiani. Pertanto, posizionare una replica di questi dati vicino all’utente può migliorare i tempi di accesso bilanciando allo stesso tempo il carico di rete.
Miglioramento delle prestazioni del sistema di test

La replica del database semplifica la distribuzione e la sincronizzazione dei dati per i sistemi di test che richiedono un accesso rapido per un processo decisionale più rapido.
Backup del database rispetto alla replica del database
Sia il backup del database che la replica del database variano in diversi modi. Alcuni di loro sono i seguenti:
- I backup del database devono essere ricostruiti e ripristinati prima di poter essere utilizzati. A differenza dei backup del database, la replica dei dati non richiede la ricostruzione e può essere utilizzata immediatamente.
- I backup del database sono costituiti da file o cartelle, file di dati del database e file dell’applicazione, a seconda dei protocolli di backup-ripristino dell’organizzazione. Al contrario, la replica del database viene spesso utilizzata per duplicare interi volumi o file system, database e applicazioni.
- Il backup e la replica sono entrambe misure di protezione dei dati. Il primo riguarda l’abbassamento degli obiettivi del punto di ripristino (RPO) e la prevenzione della perdita di dati. Mentre quest’ultimo è progettato per ridurre gli obiettivi del tempo di ripristino (RTO), garantendo la continuità aziendale e riducendo al minimo i tempi di inattività.
- Il backup del database è un metodo a basso costo per evitare la perdita totale dei dati. È essenziale per la conformità e non garantisce la continuità operativa. Al contrario, la replica assicura che le applicazioni ei processi aziendali siano sempre disponibili, anche dopo un’interruzione di corrente.
- Il backup del database riguarda la conformità e il ripristino granulare, come l’archiviazione a lungo termine dei record aziendali. D’altra parte, la replica e il ripristino del database si concentrano sul ripristino di emergenza, la rapida e semplice ripresa delle operazioni a seguito di un’interruzione o di un danneggiamento.
- Il backup del database è comunemente utilizzato sul posto di lavoro per qualsiasi cosa, dai server di produzione ai desktop. Al contrario, la replica del database viene spesso utilizzata per applicazioni mission-critical che devono essere sempre disponibili.
Tecniche di Replica di Database

Le organizzazioni possono replicare i dati seguendo una tecnica precisa per spostare i dati. Queste strategie differiscono dai tipi di replica sopra descritti.
#1. Replica completa del database
La replica completa del database replica un intero database per l’utilizzo su host diversi. Ciò garantisce la quantità più significativa di ridondanza e disponibilità dei dati. Per le aziende globali, ciò consente agli utenti in Asia di accedere agli stessi dati delle loro controparti in Nord America alla stessa velocità. Se il server asiatico si guasta, gli utenti possono utilizzare i propri server europei o nordamericani come backup.
Tuttavia, lo svantaggio di questa tecnica è la procedura di aggiornamento lenta. È anche difficile mantenere coerente la posizione di ogni file, il che è significativo se i dati cambiano continuamente.
#2. Replica parziale del database
La replica parziale del database è il processo attraverso il quale i dati in un database vengono separati in parti e salvati in posizioni diverse, a seconda della rilevanza di ciascun sito.
Periti assicurativi, consulenti finanziari e professionisti delle vendite traggono vantaggio dalla replica parziale. Questi dipendenti possono trasportare i database parziali su altri dispositivi o laptop e sincronizzarli regolarmente con un server centrale.
Per gli analisti, potrebbe essere più economico mantenere i dati europei in Europa, i dati australiani in Australia, ecc. Ciò significa mantenere i dati vicino ai consumatori mantenendo un set di dati completo presso la sede centrale per analisi di alto livello.
Svantaggi della replica del database

Sebbene la replica dei dati possa apportare un valore significativo al tuo lavoro e alla tua azienda, presenta anche i seguenti svantaggi:
Costi più elevati
Quando i dati vengono replicati e archiviati in più posizioni, richiedono più spazio di archiviazione e risorse di elaborazione. Questa maggiore domanda di risorse hardware e di calcolo può portare a costi più elevati, inclusi l’acquisto e la manutenzione di ulteriori dispositivi di storage, server e infrastrutture di rete.
Vincoli di tempo
La replica dei dati è un processo complesso che implica la copia dei dati da una posizione a più altre posizioni e il mantenimento della coerenza tra tutte le copie. Questo processo può richiedere molto tempo, soprattutto per le organizzazioni che devono replicare grandi quantità di dati.
Larghezza di banda
Con l’aumentare del volume dei dati replicati, aumentano anche i requisiti di larghezza di banda, il che può sovraccaricare le risorse di rete.
Dati incoerenti
Quando si replicano i dati in un ambiente distribuito, esiste il rischio che i dati non siano più sincronizzati se gli aggiornamenti non vengono eseguiti in modo coerente in tutte le repliche. Ciò può comportare dati incoerenti e potrebbe richiedere uno sforzo aggiuntivo per la risoluzione.
Casi d’uso della replica del database

Esistono molti casi in cui è possibile utilizzare la replica dei dati, ad esempio:
Bilancio del carico
Replicando i dati su più server, il carico viene distribuito su questi server per migliorarne le prestazioni. Pertanto, il bilanciamento del carico garantisce che un singolo server non sia sopraffatto da troppe richieste e che il sistema rimanga disponibile e reattivo anche durante i periodi di traffico elevato.
Archiviazione dati
Un data warehouse è un repository centralizzato per l’archiviazione di grandi quantità di dati da più fonti. La replica dei dati da queste origini al data warehouse consente alle organizzazioni di analizzare e creare report sui propri dati in modo centralizzato e organizzato.
Distribuzione interregionale
La replica dei dati in più regioni consente alle organizzazioni di migliorare l’accessibilità e la ridondanza dei dati. Se un’area subisce un’interruzione, è comunque possibile accedere ai dati da un’altra area. Inoltre, disporre di dati in più regioni può aiutare a migliorare la velocità di accesso per gli utenti in diverse parti del mondo.
Backup e archiviazione
La replica dei dati nello storage secondario aiuta le organizzazioni a conservare una copia a lungo termine dei propri dati. Ciò consente loro di accedere facilmente ai dati e garantisce che non vengano persi anche in caso di guasto dell’archiviazione principale.
Sincronizzazione dei dati
La replica dei dati tra più sistemi aiuta a garantire che i dati rimangano sincronizzati, coerenti e aggiornati ovunque. Questo è importante per applicazioni come l’e-commerce, dove gli stessi dati devono essere accessibili da più sistemi.
Collaborazione multisito
La replica dei dati tra più siti consente alle organizzazioni di condividere i dati in tempo reale, favorendo la collaborazione e una maggiore produttività. Ciò è particolarmente utile per le organizzazioni con team in più sedi o aziende che devono condividere dati con partner o clienti.
Risorse di apprendimento
Ecco alcune risorse di apprendimento per aiutarti a comprendere meglio l’argomento:
#1. Replica del database di Bettina Kemme
Questo libro ti aiuterà a comprendere i diversi meccanismi di controllo della concorrenza e della replica e i problemi che li riguardano.
#2. Replica del database: una guida completa:
Questo libro ti preparerà ad affrontare le sfide della replica di database spiegando e rispondendo alle tue domande.
Conclusione
La replica dei dati è una strategia sottovalutata nel mondo odierno in rapida crescita e basato sui dati. Quindi, se sei un imprenditore, rimarrai sorpreso dai suoi vantaggi.
Tuttavia, con l’aumentare del numero di fonti e destinazioni, le aziende devono essere preparate ad affrontare le sfide che ne derivano. Ecco perché una strategia di replica dei dati affidabile e scalabile può tornarti utile.
Puoi anche esplorare alcuni utili software di monitoraggio del database per analizzare le prestazioni.