

Le reti generative contraddittorio (GAN) sono una delle moderne tecnologie che offrono molto potenziale in molti casi d’uso, dalla creazione di immagini invecchiate e dall’aumento della voce alla fornitura di varie applicazioni nel settore medico e di altro tipo.
Questa tecnologia avanzata può aiutarti a dare forma ai tuoi prodotti e servizi. Può anche essere utilizzato per migliorare la qualità dell’immagine per preservare i ricordi.
Mentre i GAN sono un vantaggio per molti, alcuni lo trovano preoccupante.
Ma cos’è esattamente questa tecnologia?
In questo articolo, discuterò cos’è un GAN, come funziona e le sue applicazioni.
Quindi, tuffiamoci subito!
Sommario:
Che cos’è una rete contraddittoria generativa?
Un Generative Adversarial Network (GAN) è un framework di apprendimento automatico costituito da due reti neurali in competizione per produrre previsioni più accurate come immagini, musica unica, disegni e così via.
GANs è stato progettato nel 2014 da un informatico e ingegnere, Ian Goodfellow, e alcuni dei suoi colleghi. Sono reti neurali profonde uniche in grado di generare nuovi dati simili a quelli su cui vengono addestrati. Si contendono in una partita a somma zero che si traduce in un agente che perde la partita mentre l’altro la vince.
In origine, i GAN erano proposti come modello generativo per l’apprendimento automatico, principalmente l’apprendimento non supervisionato. Ma i GAN sono utili anche per l’apprendimento completamente supervisionato, l’apprendimento semi-supervisionato e l’apprendimento per rinforzo.
I due blocchi in competizione in un GAN sono:
Il generatore: è una rete neurale convoluzionale che produce artificialmente output simili ai dati effettivi.
Il discriminatore: è una rete neurale deconvolutiva in grado di identificare quegli output creati artificialmente.
Concetti chiave
Per comprendere meglio il concetto di GAN, comprendiamo rapidamente alcuni importanti concetti correlati.
Apprendimento automatico (ML)

L’apprendimento automatico è una parte dell’intelligenza artificiale (AI) che prevede l’apprendimento e la creazione di modelli che sfruttano i dati per migliorare le prestazioni e l’accuratezza durante l’esecuzione di attività o l’adozione di decisioni o previsioni.
Gli algoritmi ML creano modelli basati sui dati di addestramento, migliorando con l’apprendimento continuo. Sono utilizzati in molteplici campi, tra cui visione artificiale, processo decisionale automatizzato, filtraggio e-mail, medicina, servizi bancari, qualità dei dati, sicurezza informatica, riconoscimento vocale, sistemi di raccomandazione e altro ancora.
Modello discriminante

Nell’apprendimento profondo e nell’apprendimento automatico, il modello discriminante funziona come un classificatore per distinguere tra un insieme di livelli o due classi.
Ad esempio, differenziando tra diversi frutti o animali.
Modello Generativo
Nei modelli generativi, vengono presi in considerazione campioni casuali per creare nuove immagini realistiche. Impara dalle immagini reali di alcuni oggetti o esseri viventi per generare le proprie idee realistiche ma imitate. Questi modelli sono di due tipi:
Autocodificatori variazionali: utilizzano codificatori e decodificatori che sono reti neurali separate. Questo funziona perché una data immagine realistica passa attraverso un codificatore per rappresentare queste immagini come vettori in uno spazio latente.
Successivamente, viene utilizzato un decodificatore per prendere queste interpretazioni per produrre alcune copie realistiche di queste immagini. All’inizio, la qualità dell’immagine potrebbe essere bassa, ma migliorerà dopo che il decoder sarà completamente funzionante e potrai ignorare il codificatore.
Reti generative contraddittorio (GAN): come discusso in precedenza, un GAN è una rete neurale profonda in grado di generare nuovi dati simili dall’input di dati che gli viene fornito. Rientra nell’apprendimento automatico non supervisionato, che è uno dei tipi di apprendimento automatico discussi di seguito.
Apprendimento supervisionato
Nell’addestramento supervisionato, una macchina viene addestrata utilizzando dati ben etichettati. Ciò significa che alcuni dati saranno già contrassegnati con la risposta corretta. Qui, alla macchina vengono forniti alcuni dati o esempi per consentire all’algoritmo di apprendimento supervisionato di analizzare i dati di addestramento e produrre un risultato accurato da questi dati etichettati.
Apprendimento senza supervisione
L’apprendimento non supervisionato implica l’addestramento di una macchina con l’aiuto di dati che non sono né etichettati né classificati. Consente all’algoritmo di apprendimento automatico di lavorare su quei dati senza guida. In questo tipo di apprendimento, il compito della macchina è classificare i dati non ordinati in base a modelli, somiglianze e differenze senza un precedente addestramento dei dati.
Pertanto, i GAN sono associati all’esecuzione dell’apprendimento non supervisionato in ML. Ha due modelli che possono scoprire e apprendere automaticamente i modelli dai dati di input. Questi due modelli sono generatore e discriminatore.
Capiamoli un po’ di più.
Parti di un GAN
Il termine “adversarial” è incluso in GAN perché ha due parti: generatore e denominatore in competizione. Questo viene fatto per acquisire, esaminare e replicare le variazioni dei dati in un set di dati. Comprendiamo meglio queste due parti di un GAN.
Generatore
Un generatore è una rete neurale in grado di apprendere e generare punti dati falsi come immagini e audio che sembrano realistici. Viene utilizzato nella formazione e migliora con l’apprendimento continuo.
I dati generati dal generatore sono usati come esempio negativo per l’altra parte, il denominatore che vedremo in seguito. Il generatore prende un vettore casuale a lunghezza fissa come input per produrre un output campione. Mira a presentare l’output davanti al discriminatore in modo che possa classificare se è reale o falso.
Il generatore è addestrato con questi componenti:
- Vettori di input rumorosi
- Una rete di generatori per trasformare un input casuale nell’istanza di dati
- Una rete di discriminatori per classificare i dati generati
- Una perdita del generatore per penalizzare il generatore in quanto non riesce a ingannare il discriminatore
Il generatore funziona come un ladro per replicare e creare dati realistici per ingannare il discriminatore. Mira ad aggirare diversi controlli effettuati. Sebbene possa fallire terribilmente nelle fasi iniziali, continua a migliorare finché non genera più dati realistici e di alta qualità e può evitare i test. Dopo aver raggiunto questa capacità, puoi utilizzare solo il generatore senza richiedere un discriminatore separato.
Discriminatore

Un discriminatore è anche una rete neurale in grado di distinguere tra un’immagine falsa e reale o altri tipi di dati. Come un generatore, svolge un ruolo fondamentale durante la fase di allenamento.
Si comporta come la polizia per catturare il ladro (dati falsi dal generatore). Mira a rilevare immagini false e anomalie in un’istanza di dati.
Come discusso in precedenza, il generatore impara e continua a migliorare per raggiungere un punto in cui diventa autosufficiente per produrre immagini di alta qualità che non richiedono un discriminatore. Quando i dati di alta qualità del generatore vengono passati attraverso il discriminatore, non è più possibile distinguere tra un’immagine reale e falsa. Quindi, sei a posto con solo il generatore.
Come funziona GAN?
In una rete contraddittoria generativa (GAN), tre cose implicano:
- Un modello generativo per descrivere il modo in cui i dati vengono generati.
- Un ambiente contraddittorio in cui viene addestrato un modello.
- Reti neurali profonde come algoritmi di intelligenza artificiale per l’allenamento.
Le due reti neurali di GAN, generatore e discriminatore, vengono utilizzate per giocare a un gioco contraddittorio. Il generatore prende i dati di input, come file audio, immagini, ecc., per generare un’istanza di dati simile mentre il discriminatore convalida l’autenticità di tale istanza di dati. Quest’ultimo determinerà se l’istanza di dati che ha esaminato è reale o meno.
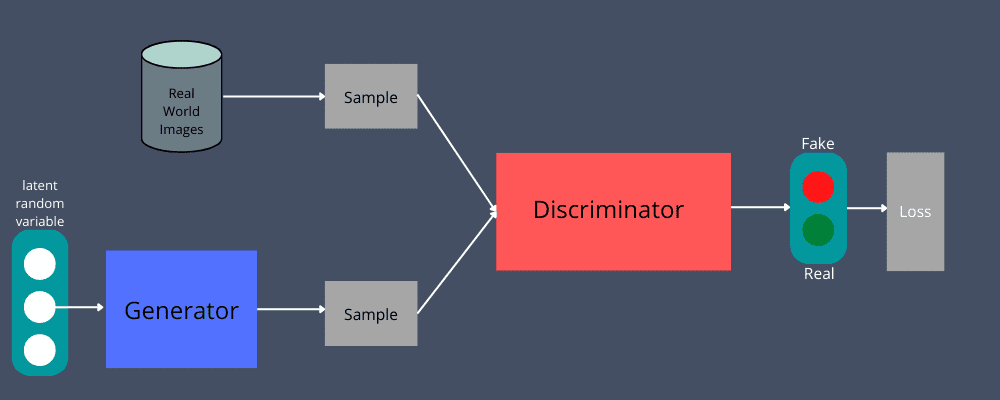
Ad esempio, vuoi verificare se una determinata immagine è reale o falsa. È possibile utilizzare input di dati generati manualmente per alimentare il generatore. Creerà nuove immagini replicate come output.
Mentre lo fa, il generatore mira a considerare autentiche tutte le immagini che genera, nonostante siano false. Vuole creare risultati accettabili per mentire ed evitare di essere scoperti.
Successivamente, questo output andrà al discriminatore insieme a una serie di immagini da dati reali per rilevare se queste immagini sono autentiche o meno. Funziona negativamente sul generatore, non importa quanto duramente provi a imitare; il discriminatore aiuterà a distinguere i dati fattuali da quelli falsi.
Il discriminatore prenderà sia i dati falsi che quelli reali per restituire una probabilità di 0 o 1. Qui, 1 rappresenta l’autenticità mentre 0 rappresenta un falso.
Ci sono due cicli di feedback in questo processo:
- Il generatore si unisce a un circuito di feedback con un discriminatore
- Il discriminatore si unisce a un altro ciclo di feedback con un insieme di immagini reali
Un addestramento GAN funziona perché sia il generatore che il discriminatore sono in addestramento. Il generatore apprende continuamente passando input falsi, mentre il discriminatore imparerà a migliorare il rilevamento. Qui, entrambi sono dinamici.
Il discriminatore è una rete convolutiva in grado di classificare le immagini che gli vengono fornite. Funziona come un classificatore binomiale per etichettare le immagini come false o reali.
D’altra parte, il generatore è come una rete convoluzionale inversa che preleva campioni di dati casuali per produrre immagini. Tuttavia, il discriminatore verifica i dati con l’aiuto di tecniche di downsampling come il max-pooling.
Entrambe le reti cercano di ottimizzare una funzione di perdita o obiettivo opposta e diversa in un gioco contraddittorio. Le loro perdite consentono loro di spingersi l’uno contro l’altro ancora più duramente.
Tipi di GAN

Le reti contraddittorie generative sono di diversi tipi in base all’implementazione. Ecco i principali tipi di GAN utilizzati attivamente:
- GAN condizionale (CGAN): è una tecnica di apprendimento profondo che coinvolge parametri condizionali specifici per aiutare a distinguere tra dati reali e falsi. Include anche un parametro aggiuntivo – “y” nella fase del generatore per produrre i dati corrispondenti. Inoltre, le etichette vengono aggiunte a questo input e vengono inviate al discriminatore per consentirgli di verificare se i dati sono autentici o falsi.
- Vanilla GAN: è un tipo GAN semplice in cui il discriminatore e il generatore sono perceptron più semplici e multistrato. I suoi algoritmi sono semplici, ottimizzando l’equazione matematica con l’aiuto della discesa del gradiente stocastico.
- Deep convolutional GAN (DCGAN): è popolare e considerata l’implementazione GAN di maggior successo. DCGAN è costituito da ConvNet anziché da perceptron multistrato. Questi ConvNet vengono applicati senza utilizzare tecniche come il max-pooling o la connessione completa dei livelli.
- Super Resolution GAN (SRGAN): è un’implementazione GAN che utilizza una rete neurale profonda insieme a una rete contraddittoria per aiutare a produrre immagini di alta qualità. SRGAN è particolarmente utile per aumentare in modo efficiente le immagini originali a bassa risoluzione in modo che i loro dettagli siano migliorati e gli errori siano ridotti al minimo.
- Laplacian Pyramid GAN (LAPGAN): è una rappresentazione lineare e invertibile che include più immagini passa-banda posizionate a otto spazi l’una dall’altra con residui di bassa frequenza. LAPGAN utilizza diverse reti di discriminatori e generatori e più livelli di piramide laplaciana.
LAPGAN è ampiamente utilizzato in quanto produce una qualità dell’immagine di prim’ordine. Queste immagini vengono prima sottocampionate a ogni livello della piramide e poi ridimensionate a ogni livello, dove alle idee viene dato un po’ di rumore finché non ottengono le dimensioni originali.
Applicazioni dei GAN
Le reti generative contraddittorie sono utilizzate in vari campi, come ad esempio:
Scienza

I GAN possono fornire un modo accurato e veloce per modellare la formazione di getti ad alta energia e condurre esperimenti di fisica. Queste reti possono anche essere addestrate per stimare i colli di bottiglia nell’esecuzione di simulazioni per la fisica delle particelle che consumano risorse pesanti.
I GAN possono accelerare la simulazione e migliorare la fedeltà della simulazione. Inoltre, i GAN possono aiutare a studiare la materia oscura simulando la lente gravitazionale e migliorando le immagini astronomiche.
Videogiochi

Il mondo dei videogiochi ha anche sfruttato i GAN per aumentare i dati bidimensionali a bassa risoluzione utilizzati nei videogiochi più vecchi. Ti aiuterà a ricreare tali dati in risoluzioni 4k o anche superiori attraverso l’allenamento delle immagini. Successivamente, puoi eseguire il downsampling dei dati o delle immagini per renderli adatti alla risoluzione reale del videogioco.
Fornisci una formazione adeguata ai tuoi modelli GAN. Possono offrire immagini 2D più nitide e chiare di qualità impressionante rispetto ai dati nativi, pur mantenendo i dettagli dell’immagine reale, come i colori.
I videogiochi che hanno sfruttato i GAN includono Resident Evil Remake, Final Fantasy VIII e IX e altro ancora.
Arte e Moda
Puoi utilizzare i GAN per generare arte, ad esempio creare immagini di individui che non sono mai esistiti, fotografie dipinte, produrre immagini di modelli di moda irreali e molti altri. Viene anche utilizzato nei disegni che generano ombre e schizzi virtuali.
Pubblicità

L’utilizzo dei GAN per creare e produrre i tuoi annunci farà risparmiare tempo e risorse. Come visto sopra, se vuoi vendere i tuoi gioielli, puoi creare un modello immaginario che assomigli a un vero essere umano con l’aiuto di GAN.
In questo modo, puoi far indossare alla modella i tuoi gioielli e mostrarli ai tuoi clienti. Ti eviterà di assumere un modello e di pagarlo. Puoi anche eliminare le spese extra come il pagamento del trasporto, l’affitto di uno studio, l’organizzazione di fotografi, truccatori, ecc.
Ciò sarà di grande aiuto se sei un’azienda in crescita e non puoi permetterti di assumere un modello o ospitare un’infrastruttura per le riprese pubblicitarie.
Sintesi audio
Puoi creare file audio da una serie di clip audio con l’aiuto di GAN. Questo è anche noto come audio generativo. Per favore, non confonderlo con Amazon Alexa, Apple Siri o altre voci AI in cui i frammenti vocali sono cuciti bene e prodotti su richiesta.
Invece, l’audio generativo utilizza le reti neurali per studiare le proprietà statistiche di una sorgente audio. Successivamente, riproduce direttamente quelle proprietà in un determinato contesto. Qui, la modellazione rappresenta il modo in cui il parlato cambia dopo ogni millisecondo.
Trasferisci l’apprendimento

Gli studi avanzati sull’apprendimento del trasferimento utilizzano i GAN per allineare gli spazi delle funzionalità più recenti come l’apprendimento per rinforzo profondo. Per questo, gli embedding della fonte e il compito mirato vengono forniti al discriminatore per determinare il contesto. Successivamente, il risultato viene propagato indietro tramite l’encoder. In questo modo, il modello continua ad apprendere.
Altre applicazioni dei GAN includono:
- Diagnosi di perdita della vista totale o parziale rilevando immagini glaucomatose
- Visualizza il design industriale, l’interior design, gli articoli di abbigliamento, le scarpe, le borse e altro ancora
- ricostruire le caratteristiche facciali forensi di una persona malata
- creare modelli 3D di un elemento da un’immagine, produrre nuovi oggetti come una nuvola di punti 3D, modellare modelli di movimento in un video
- Mostra l’aspetto di una persona con un’età che cambia
- Aumento dei dati come il miglioramento del classificatore DNN
- Disegna una caratteristica mancante in una mappa, migliora le viste stradali, trasferisci gli stili di mappatura e altro ancora
- Produrre immagini, sostituire un sistema di ricerca di immagini, ecc.
- Genera input di controllo per un sistema dinamico non lineare utilizzando una variazione GAN
- Analizza gli effetti del cambiamento climatico su una casa
- Crea il volto di una persona prendendo la sua voce come input
- Crea nuove molecole per diversi bersagli proteici nel cancro, nella fibrosi e nell’infiammazione
- Anima le gif da un’immagine normale
Esistono molte più applicazioni di GAN in varie aree e il loro utilizzo è in espansione. Tuttavia, ci sono anche più casi del suo uso improprio. Le immagini umane basate su GAN sono state utilizzate per casi d’uso sinistri come la produzione di video e immagini falsi.
I GAN possono anche essere utilizzati per creare foto e profili realistici di persone sui social media che non sono mai esistite sulla terra. Altri usi impropri dei GNA sono la creazione di pornografia falsa senza il consenso di individui in primo piano, la distribuzione di video contraffatti di candidati politici e così via.
Sebbene i GNA possano essere un vantaggio in molti campi, il loro uso improprio può anche essere disastroso. Pertanto, per il suo utilizzo devono essere applicate linee guida adeguate.
Conclusione
I GAN sono un notevole esempio di tecnologia moderna. Fornisce un modo unico e migliore per generare dati e aiutare in funzioni come la diagnosi visiva, la sintesi di immagini, la ricerca, l’aumento dei dati, le arti e la scienza e molti altri.
Potresti anche essere interessato a piattaforme di machine learning a basso codice e senza codice per la creazione di applicazioni innovative.