

Apache Parquet offre numerosi vantaggi per l’archiviazione e il recupero dei dati rispetto ai metodi tradizionali come CSV.
Il formato Parquet è progettato per un’elaborazione più rapida dei dati di tipi complessi. In questo articolo parliamo di come il formato Parquet sia adatto alle esigenze di dati sempre crescenti di oggi.
Prima di approfondire i dettagli del formato Parquet, cerchiamo di capire cosa sono i dati CSV e le sfide che comporta per l’archiviazione dei dati.
Sommario:
Che cos’è l’archiviazione CSV?
Abbiamo tutti sentito parlare molto di CSV (Comma Separated Values), uno dei modi più comuni per organizzare e formattare i dati. L’archiviazione dei dati CSV è basata su righe. I file CSV vengono archiviati con estensione .csv. Possiamo archiviare e aprire dati CSV utilizzando Excel, Fogli Google o qualsiasi editor di testo. I dati sono facilmente visualizzabili una volta aperto il file.
Bene, non va bene, sicuramente non per un formato di database.
Inoltre, con l’aumento del volume dei dati, diventa difficile eseguire query, gestire e recuperare.
Ecco un esempio di dati archiviati in un file .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Se lo visualizziamo in Excel, possiamo vedere una struttura riga-colonna come di seguito:
Sfide con l’archiviazione CSV
Gli archivi basati su righe come CSV sono adatti per le operazioni di creazione, aggiornamento ed eliminazione.
Che dire di Read in CRUD, allora?
Immagina un milione di righe nel file .csv sopra. Ci vorrebbe un tempo ragionevole per aprire il file e cercare i dati che stai cercando. Non così bello. La maggior parte dei fornitori di servizi cloud come AWS addebita alle aziende una tariffa basata sulla quantità di dati scansionati o archiviati, anche in questo caso i file CSV consumano molto spazio.
L’archiviazione CSV non ha un’opzione esclusiva per archiviare i metadati, rendendo la scansione dei dati un’attività noiosa.
Allora, qual è la soluzione conveniente e ottimale per eseguire tutte le operazioni CRUD? Esploriamo.
Che cos’è l’archiviazione dei dati di Parquet?
Parquet è un formato di archiviazione open source per archiviare i dati. È ampiamente utilizzato negli ecosistemi Hadoop e Spark. I file Parquet vengono archiviati come estensione .parquet.
Il parquet è un formato altamente strutturato. Può anche essere utilizzato per ottimizzare dati grezzi complessi presenti in blocco nei data lake. Ciò può ridurre significativamente il tempo di interrogazione.
Parquet rende l’archiviazione dei dati efficiente e il recupero più rapido grazie a una combinazione di formati di archiviazione basati su righe e colonne (ibridi). In questo formato, i dati vengono partizionati sia orizzontalmente che verticalmente. Il formato Parquet elimina anche in larga misura il sovraccarico di analisi.
Il formato limita il numero complessivo di operazioni di I/O e, in definitiva, il costo.
Parquet memorizza anche i metadati, che memorizzano informazioni sui dati come lo schema dei dati, il numero di valori, la posizione delle colonne, il valore minimo, il valore massimo numero di gruppi di righe, il tipo di codifica, ecc. I metadati sono archiviati a diversi livelli nel file , rendendo più veloce l’accesso ai dati.
Nell’accesso basato su riga come CSV, il recupero dei dati richiede tempo poiché la query deve spostarsi in ogni riga e ottenere i valori di colonna particolari. Con il magazzino Parquet è possibile accedere contemporaneamente a tutte le colonne necessarie.
In sintesi,
- Parquet si basa sulla struttura a colonne per l’archiviazione dei dati
- È un formato dati ottimizzato per archiviare dati complessi in blocco nei sistemi di archiviazione
- Il formato Parquet include vari metodi per la compressione e la codifica dei dati
- Riduce significativamente il tempo di scansione dei dati e il tempo di query e occupa meno spazio su disco rispetto ad altri formati di archiviazione come CSV
- Riduce al minimo il numero di operazioni di I/O, riducendo i costi di archiviazione e di esecuzione delle query
- Include metadati che semplificano la ricerca dei dati
- Fornisce supporto open source
Formato dati parquet
Prima di entrare in un esempio, vediamo più nel dettaglio come vengono archiviati i dati nel formato Parquet:
Possiamo avere più partizioni orizzontali note come gruppi di righe in un file. All’interno di ogni gruppo di righe viene applicata la partizione verticale. Le colonne sono suddivise in più blocchi di colonna. I dati vengono archiviati come pagine all’interno dei blocchi di colonna. Ogni pagina contiene i valori dei dati codificati e i metadati. Come accennato in precedenza, anche i metadati dell’intero file vengono archiviati nel piè di pagina del file a livello di gruppo di righe.
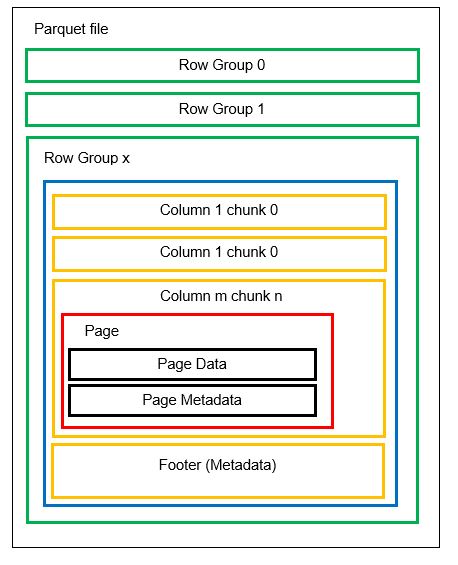
Poiché i dati sono suddivisi in blocchi di colonne, è facile anche aggiungere nuovi dati codificando i nuovi valori in un nuovo blocco e file. I metadati vengono quindi aggiornati per i file e i gruppi di righe interessati. Possiamo quindi dire che Parquet è un formato flessibile.
Parquet supporta in modo nativo la compressione dei dati utilizzando le tecniche di compressione della pagina e di codifica del dizionario. Vediamo un semplice esempio di compressione del dizionario:
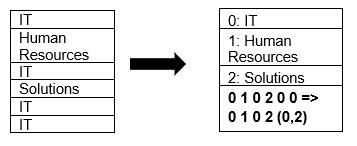
Si noti che nell’esempio sopra, vediamo la divisione IT 4 volte. Quindi, durante la memorizzazione nel dizionario, il formato codifica i dati con un altro valore facile da memorizzare (0,1,2…) insieme al numero di volte in cui viene ripetuto continuamente: IT, IT viene modificato in 0,2 per salvare più spazio. L’esecuzione di query sui dati compressi richiede meno tempo.
Confronto testa a testa
Ora che abbiamo una buona idea di come appaiono i formati CSV e Parquet, è tempo che alcune statistiche confrontino entrambi i formati:
CSV
Parquet
Formato di archiviazione basato su righe.
Un ibrido di formati di archiviazione basati su righe e su colonne.
Consuma molto spazio poiché non è disponibile alcuna opzione di compressione predefinita. Ad esempio, un file da 1 TB occuperà lo stesso spazio se archiviato su Amazon S3 o qualsiasi altro cloud.
Comprime i dati durante l’archiviazione, consumando così meno spazio. Un file da 1 TB archiviato in formato Parquet occuperà solo 130 GB di spazio.
Il tempo di esecuzione della query è lento a causa della ricerca basata su riga. Per ogni colonna, è necessario recuperare ogni riga di dati.
Il tempo di query è circa 34 volte più veloce a causa dell’archiviazione basata su colonne e della presenza di metadati.
È necessario scansionare più dati per query.
Circa il 99% in meno di dati viene scansionato per l’esecuzione della query, ottimizzando così le prestazioni.
La maggior parte dei dispositivi di archiviazione si carica in base allo spazio di archiviazione, quindi il formato CSV significa l’alto costo di archiviazione.
Minori costi di archiviazione poiché i dati vengono archiviati in un formato compresso e codificato.
Lo schema del file deve essere dedotto (che porta a errori) o fornito (noioso).
Lo schema del file è archiviato nei metadati.
Il formato è adatto per tipi di dati semplici.
Parquet è adatto anche per tipi complessi come schemi nidificati, array, dizionari.
Conclusione 👩💻
Abbiamo visto attraverso esempi che Parquet è più efficiente di CSV in termini di costi, flessibilità e prestazioni. È un meccanismo efficace per l’archiviazione e il recupero dei dati, soprattutto quando il mondo intero si sta muovendo verso l’archiviazione su cloud e l’ottimizzazione dello spazio. Tutte le principali piattaforme come Azure, AWS e BigQuery supportano il formato Parquet.