
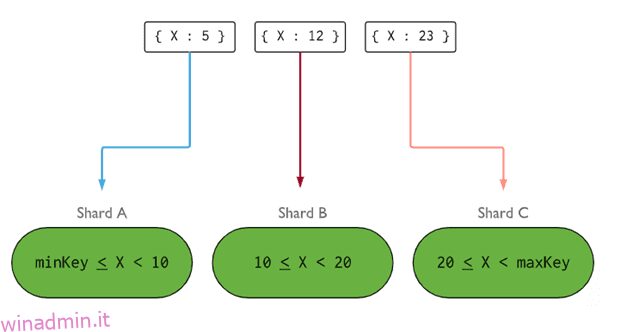
Lo sharding è un processo di suddivisione dell’ampia scala di set di dati in un blocco di set di dati più piccoli su più istanze MongoDB in un ambiente distribuito.
Sommario:
Cos’è lo Sharding?
Lo sharding di MongoDB ci fornisce una soluzione scalabile per archiviare una grande quantità di dati tra il numero di server piuttosto che archiviare su un singolo server.
In termini pratici, non è possibile archiviare dati in crescita esponenziale su una singola macchina. L’esecuzione di query su un’enorme quantità di dati archiviati su un singolo server potrebbe comportare un elevato utilizzo delle risorse e potrebbe non fornire una velocità effettiva di lettura e scrittura soddisfacente.
Fondamentalmente, esistono due tipi di metodi di ridimensionamento per eseguire la crescita dei dati con il sistema:
Il ridimensionamento verticale migliora le prestazioni del singolo server aggiungendo processori più potenti, aggiornando la RAM o aggiungendo più spazio su disco al sistema. Ma ci sono le possibili implicazioni dell’applicazione del ridimensionamento verticale in casi d’uso pratici con la tecnologia esistente e le configurazioni hardware.
Il ridimensionamento orizzontale funziona con l’aggiunta di più server e la distribuzione del carico su più server. Poiché ogni macchina gestirà il sottoinsieme dell’intero set di dati, fornisce una migliore efficienza e una soluzione conveniente piuttosto che implementare l’hardware di fascia alta. Ma richiede un’ulteriore manutenzione di un’infrastruttura complessa con un numero elevato di server.
Il partizionamento orizzontale di Mongo DB funziona con la tecnica di ridimensionamento orizzontale.
Componenti di partizionamento orizzontale
Per ottenere lo sharding in MongoDB, sono necessari i seguenti componenti:
Shard è un’istanza Mongo per gestire un sottoinsieme di dati originali. Gli shard devono essere distribuiti nel set di repliche.
Mongos è un’istanza Mongo e funge da interfaccia tra un’applicazione client e un cluster partizionato. Funziona come un router di query per frammenti.
Config Server è un’istanza Mongo che memorizza le informazioni sui metadati e i dettagli di configurazione del cluster. MongoDB richiede che il server di configurazione sia distribuito come set di repliche.
Architettura di partizionamento orizzontale
Il cluster MongoDB è costituito da una serie di set di repliche.
Ogni set di repliche è costituito da un minimo di 3 o più istanze mongo. Un cluster partizionato può essere costituito da più istanze di frammenti mongo e ogni istanza di frammenti funziona all’interno di un set di repliche di frammenti. L’applicazione interagisce con Mongos, che a sua volta comunica con i frammenti. Pertanto, in Sharding, le applicazioni non interagiscono mai direttamente con i nodi shard. Il router di query distribuisce i sottoinsiemi di dati tra i nodi shard in base alla chiave shard.
Implementazione dello sharding
Segui i passaggi seguenti per il partizionamento orizzontale
Passo 1
- Avvia il server di configurazione nel set di repliche e abilita la replica tra di loro.
mongod –configsvr –porta 27019 –replSet rs0 –dbpath C:datadata1 –bind_ip localhost
mongod –configsvr –porta 27018 –replSet rs0 –dbpath C:datadata2 –bind_ip localhost
mongod –configsvr –porta 27017 –replSet rs0 –dbpath C:datadata3 –bind_ip localhost
Passo 2
- Inizializza la replica impostata su uno dei server di configurazione.
rs.initiate( { _id : “rs0”, configsvr: true, membri: [ { _id: 0, host: “IP:27017” }, { _id: 1, host: “IP:27018” }, { _id: 2, host: “IP:27019” } ] })
rs.initiate( { _id : "rs0", configsvr: true, members: [ { _id: 0, host: "IP:27017" }, { _id: 1, host: "IP:27018" }, { _id: 2, host: "IP:27019" } ] })
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1593569257, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1593569257, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569257, 1)
}
Passaggio 3
- Avviare i server di partizionamento orizzontale nel set di repliche e abilitare la replica tra di essi.
mongod –shardsvr –porta 27020 –replSet rs1 –dbpath C:datadata4 –bind_ip localhost
mongod –shardsvr –porta 27021 –replSet rs1 –dbpath C:datadata5 –bind_ip localhost
mongod –shardsvr –porta 27022 –replSet rs1 –dbpath C:datadata6 –bind_ip localhost
MongoDB inizializza il primo server di partizionamento orizzontale come primario, per spostare l’utilizzo del server di partizionamento orizzontale primario movePrimary metodo.
Passaggio 4
- Inizializza il set di repliche su uno dei server partizionati.
rs.initiate( { _id : “rs0”, membri: [ { _id: 0, host: “IP:27020” }, { _id: 1, host: “IP:27021” }, { _id: 2, host: “IP:27022” } ] })
rs.initiate( { _id : "rs0", members: [ { _id: 0, host: "IP:27020" }, { _id: 1, host: "IP:27021" }, { _id: 2, host: "IP:27022" } ] })
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1593569748, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569748, 1)
}
Passaggio 5
- Avvia i mango per il cluster frammentato
mongos –port 40000 –configdb rs0/localhost:27019,localhost:27018, localhost:27017
Passaggio 6
- Collega il server di percorso mongo
mongo –porta 40000
- Ora aggiungi i server di partizionamento orizzontale.
sh.addShard( “rs1/localhost:27020,localhost:27021,localhost:27022”)
sh.addShard( "rs1/localhost:27020,localhost:27021,localhost:27022")
{
"shardAdded" : "rs1",
"ok" : 1,
"operationTime" : Timestamp(1593570212, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570212, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Passaggio 7
- Su mongo shell abilita lo sharding su DB e raccolte.
- Abilita partizionamento orizzontale su DB
sh.enableSharding (“geekFlareDB”)
sh.enableSharding("geekFlareDB")
{
"ok" : 1,
"operationTime" : Timestamp(1591630612, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1591630612, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Passaggio 8
- Per partizionare la chiave di partizionamento della raccolta (descritta più avanti in questo articolo) è necessario.
Sintassi: sh.shardCollection(“dbName.collectionName”, { “key” : 1 } )
sh.shardCollection("geekFlareDB.geekFlareCollection", { "key" : 1 } )
{
"collectionsharded" : "geekFlareDB.geekFlareCollection",
"collectionUUID" : UUID("0d024925-e46c-472a-bf1a-13a8967e97c1"),
"ok" : 1,
"operationTime" : Timestamp(1593570389, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570389, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Nota se la raccolta non esiste, crea come segue.
db.createCollection("geekFlareCollection")
{
"ok" : 1,
"operationTime" : Timestamp(1593570344, 4),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570344, 5),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Passaggio 9
Inserisci i dati nella raccolta. I registri Mongo inizieranno a crescere e indicano che un bilanciatore è in azione e tenta di bilanciare i dati tra gli shard.
Passaggio 10
L’ultimo passaggio consiste nel controllare lo stato del partizionamento orizzontale. Lo stato può essere verificato eseguendo sotto il comando sul nodo della rotta Mongos.
Stato di partizionamento orizzontale
Controlla lo stato di partizionamento orizzontale eseguendo il comando seguente sul nodo della route mongo.
sh.status()
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5ede66c22c3262378c706d21")
}
shards:
{ "_id" : "rs1", "host" : "rs1/localhost:27020,localhost:27021,localhost:27022", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs1
Time of Reported error: Tue Jun 09 2020 15:25:03 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs1 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs1", "partitioned" : true, "version" : { "uuid" : UUID("a770da01-1900-401e-9f34-35ce595a5d54"), "lastMod" : 1 } }
geekFlareDB.geekFlareCol
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
geekFlareDB.geekFlareCollection
shard key: { "product" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "product" : { "$minKey" : 1 } } -->> { "product" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs1", "partitioned" : false, "version" : { "uuid" : UUID("fbc00f03-b5b5-4d13-9d09-259d7fdb7289"), "lastMod" : 1 } }
mongos>
Distribuzione dei dati
Il router Mongos distribuisce il carico tra gli shard in base alla chiave shard e distribuisce i dati in modo uniforme; entra in azione il bilanciatore.
Il componente chiave per distribuire i dati tra i frammenti sono
- Un bilanciatore svolge un ruolo nel bilanciamento del sottoinsieme di dati tra i nodi partizionati. Balancer viene eseguito quando il server Mongos inizia a distribuire i carichi tra gli shard. Una volta avviato, Balancer ha distribuito i dati in modo più uniforme. Per controllare lo stato del bilanciatore, esegui sh.status() o sh.getBalancerState() o
sh.isBalancerRunning().
mongos> sh.isBalancerRunning() true mongos>
O
mongos> sh.getBalancerState() true mongos>
Dopo aver inserito i dati, potremmo notare alcune attività nel demone Mongos che afferma che sta spostando alcuni blocchi per gli shard specifici e così via, ovvero il bilanciatore sarà in azione cercando di bilanciare i dati tra gli shard. L'esecuzione del bilanciatore potrebbe causare problemi di prestazioni; quindi si suggerisce di eseguire il bilanciatore entro un determinato finestra di bilanciamento.
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5efbeff98a8bbb2d27231674")
}
shards:
{ "_id" : "rs1", "host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022", "state" : 1 }
{ "_id" : "rs2", "host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: yes
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs2
Time of Reported error: Wed Jul 01 2020 14:39:59 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
1024 : Success
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs2 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs2", "partitioned" : true, "version" : { "uuid" : UUID("a8b8dc5c-85b0-4481-bda1-00e53f6f35cd"), "lastMod" : 1 } }
geekFlareDB.geekFlareCollection
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs2 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs2", "partitioned" : false, "version" : { "uuid" : UUID("a28d7504-1596-460e-9e09-0bdc6450028f"), "lastMod" : 1 } }
mongos>
- Shard Key determina la logica per distribuire i documenti della raccolta partizionata tra gli shard. La chiave di partizione può essere un campo indicizzato o un campo composto indicizzato che deve essere presente in tutti i documenti della raccolta da inserire. I dati verranno partizionati in blocchi e ciascun blocco sarà associato alla chiave shard basata sull'intervallo. Sulla base della query dell'intervallo, il router deciderà quale shard memorizzerà il blocco.
La chiave shard può essere selezionata considerando cinque proprietà:
- Cardinalità
- Scrivi la distribuzione
- Leggi la distribuzione
- Leggi il targeting
- Leggi località
Una chiave shard ideale fa sì che MongoDB distribuisca uniformemente il carico tra tutti gli shard. La scelta di una buona chiave shard è estremamente importante.
 Immagine: MongoDB
Immagine: MongoDB
Rimozione del nodo shard
Prima di rimuovere gli shard dal cluster, l'utente deve garantire la migrazione sicura dei dati agli shard rimanenti. MongoDB si occupa del drenaggio sicuro dei dati verso altri nodi shard prima della rimozione del nodo shard richiesto.
Esegui il comando seguente per rimuovere lo shard richiesto.
Passo 1
Innanzitutto, dobbiamo determinare il nome host dello shard da rimuovere. Il comando seguente elencherà tutti gli shard presenti nel cluster insieme allo stato dello shard.
db.adminCommand( { listShards: 1 } )
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs1",
"host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022",
"state" : 1
},
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593572866, 15),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572866, 15),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Passo 2
Emettere il comando seguente per rimuovere lo shard richiesto dal cluster. Una volta emesso, il bilanciatore si occupa della rimozione dei blocchi dal nodo shard di drenaggio e quindi bilancia la distribuzione dei blocchi rimanenti tra i nodi degli shard rimanenti.
db.adminCommand( { removeShard: “shardedReplicaNodes” } )
mongos> db.adminCommand( { removeShard: "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022" } )
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "rs1",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1,
"operationTime" : Timestamp(1593572385, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572385, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Passaggio 3
Per controllare lo stato del frammento drenante, emettere di nuovo lo stesso comando.
db.adminCommand( { removeShard: “rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022” } )
Dobbiamo aspettare fino al completamento del drenaggio dei dati. i campi msg e state mostreranno se lo svuotamento dei dati è stato completato o meno, come segue
"msg" : "draining ongoing", "state" : "ongoing",
Possiamo anche controllare lo stato con il comando sh.status(). Una volta rimosso, il nodo partizionato non si rifletterà nell'output. Ma se il drenaggio sarà in corso, il nodo partizionato avrà lo stato di drenaggio come true.
Passaggio 4
Continua a controllare lo stato del drenaggio con lo stesso comando sopra, fino a quando lo shard richiesto non viene rimosso completamente.
Una volta completato, l'output del comando rifletterà il messaggio e lo stato come completato.
"msg" : "removeshard completed successfully", "state" : "completed", "shard" : "rs1", "ok" : 1,
Passaggio 5
Infine, dobbiamo controllare gli shard rimanenti nel cluster. Per controllare lo stato, inserisci sh.status() o db.adminCommand( { listShards: 1 } )
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593575215, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593575215, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Qui possiamo vedere che il frammento rimosso non è più presente nell'elenco dei frammenti.
Vantaggi dello sharding rispetto alla replica
- Nella replica, il nodo primario gestisce tutte le operazioni di scrittura, mentre i server secondari devono mantenere le copie di backup o servire operazioni di sola lettura. Ma nel partizionamento orizzontale insieme ai set di repliche, il carico viene distribuito tra un numero di server.
- Un singolo set di repliche è limitato a 12 nodi, ma non ci sono restrizioni sul numero di shard.
- La replica richiede hardware di fascia alta o ridimensionamento verticale per la gestione di set di dati di grandi dimensioni, che è troppo costoso rispetto all'aggiunta di server aggiuntivi nello sharding.
- Nella replica, le prestazioni di lettura possono essere migliorate aggiungendo più server slave/secondari, mentre, nello sharding, le prestazioni di lettura e scrittura saranno migliorate aggiungendo più nodi shard.
Limitazione dello sharding
- Il cluster Sharded non supporta l'indicizzazione univoca tra gli shard finché l'indice univoco non è preceduto dalla chiave shard completa.
- Tutte le operazioni di aggiornamento per la raccolta partizionata su uno o più documenti devono contenere la chiave partizionata o il campo _id nella query.
- Le raccolte possono essere partizionate se le loro dimensioni non superano la soglia specificata. Questa soglia può essere stimata sulla base della dimensione media di tutte le chiavi shard e della dimensione configurata dei blocchi.
- Lo sharding comprende limiti operativi sulla dimensione massima della raccolta o sul numero di suddivisioni.
- La scelta delle chiavi shard sbagliate porta a implicazioni sulle prestazioni.
Conclusione
MongoDB offre lo sharding integrato per implementare un database di grandi dimensioni senza compromettere le prestazioni. Spero che quanto sopra ti aiuti a configurare lo sharding di MongoDB. Successivamente, potresti voler familiarizzare con alcuni dei comandi MongoDB comunemente usati.