

Usa le pipe di Linux per coreografare il modo in cui collaborano le utility della riga di comando. Semplifica i processi complessi e aumenta la produttività sfruttando una raccolta di comandi autonomi e trasformandoli in un team unico. Ti mostriamo come.
Sommario:
I tubi sono ovunque
I pipe sono una delle funzionalità della riga di comando più utili che hanno i sistemi operativi Linux e Unix. I tubi sono usati in innumerevoli modi. Guarda qualsiasi articolo della riga di comando di Linux, su qualsiasi sito web, non solo sul nostro, e vedrai che i tubi fanno la loro comparsa il più delle volte. Ho esaminato alcuni articoli Linux di winadmin.it e le pipe sono usate in tutti loro, in un modo o nell’altro.
Le pipe di Linux consentono di eseguire azioni che non sono supportate immediatamente da conchiglia. Ma poiché la filosofia di progettazione di Linux è quella di avere molte piccole utilità che eseguono le proprie funzione dedicata molto benee senza funzionalità inutili – il mantra “fai una cosa e fallo bene” – puoi mettere insieme stringhe di comandi insieme a pipe in modo che l’output di un comando diventi l’input di un altro. Ogni comando che invii porta il suo talento unico alla squadra e presto scopri di aver messo insieme una squadra vincente.
Un semplice esempio
Supponiamo di avere una directory piena di molti diversi tipi di file. Vogliamo sapere quanti file di un certo tipo si trovano in quella directory. Ci sono altri modi per farlo, ma l’obiettivo di questo esercizio è introdurre i tubi, quindi lo faremo con i tubi.
Possiamo ottenere facilmente un elenco dei file usando ls:
ls
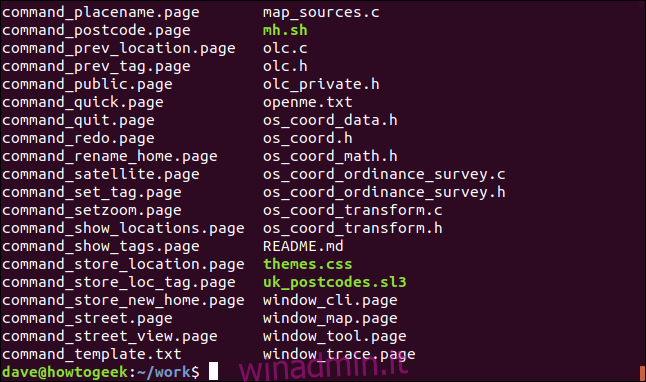
Per separare il tipo di file di interesse, useremo grep. Vogliamo trovare i file che hanno la parola “pagina” nel loro nome file o estensione file.
Useremo il carattere speciale della shell “|” per convogliare l’output da ls a grep.
ls | grep "page"

grep stampa le righe che corrisponde al suo modello di ricerca. Quindi questo ci dà un elenco contenente solo file “.page”.
Anche questo banale esempio mostra la funzionalità dei tubi. L’output di ls non è stato inviato alla finestra del terminale. È stato inviato a grep come dati per il comando grep con cui lavorare. L’output che vediamo proviene da grep, che è l’ultimo comando in questa catena.
Estendere la nostra catena
Cominciamo ad estendere la nostra catena di comandi in pipe. Noi possiamo contare i file “.page” aggiungendo il comando wc. Useremo l’opzione -l (conteggio righe) con wc. Nota che abbiamo anche aggiunto l’opzione -l (formato lungo) a ls. Lo useremo a breve.
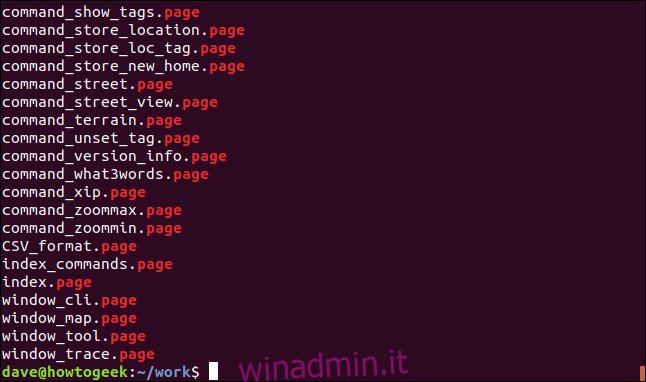
ls - | grep "page" | wc -l

grep non è più l’ultimo comando della catena, quindi non ne vediamo l’output. L’output di grep viene inserito nel comando wc. L’output che vediamo nella finestra del terminale è da wc. wc segnala che sono presenti 69 file “.page” nella directory.
Estendiamo di nuovo le cose. Toglieremo il comando wc dalla riga di comando e lo sostituiremo con awk. Ci sono nove colonne nell’output di ls con l’opzione -l (formato lungo). Useremo awk per colonne di stampa cinque, tre e nove. Queste sono le dimensioni, il proprietario e il nome del file.
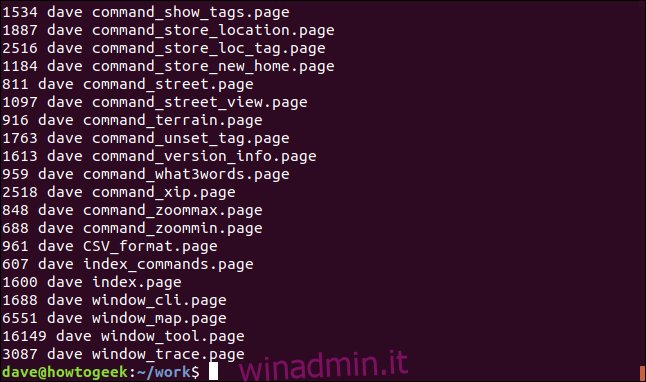
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}'

Otteniamo un elenco di quelle colonne, per ciascuno dei file corrispondenti.
Ora passeremo quell’output attraverso il comando sort. Useremo l’opzione -n (numerico) per far sapere a sort che dovrebbe essere la prima colonna trattati come numeri.
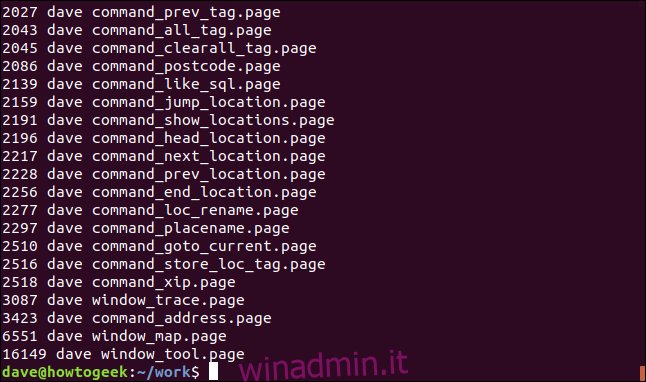
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n

L’output è ora ordinato in base alle dimensioni del file, con la nostra selezione personalizzata di tre colonne.
Aggiunta di un altro comando
Concluderemo aggiungendo il comando tail. Gli diremo di elencare i file ultime cinque righe di output solo.
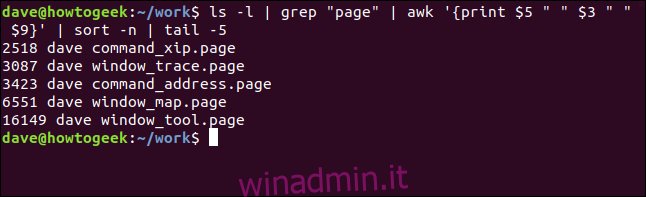
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n | tail -5

Ciò significa che il nostro comando si traduce in qualcosa come “mostrami i cinque file” .page “più grandi in questa directory, ordinati per dimensione.” Ovviamente non esiste un comando per farlo, ma usando le pipe, abbiamo creato il nostro. Potremmo aggiungere questo, o qualsiasi altro comando lungo, come alias o funzione di shell per salvare tutta la digitazione.
Ecco l’output:
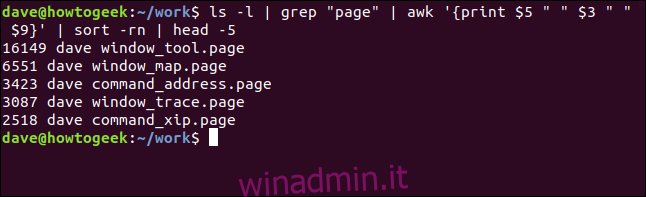
Potremmo invertire l’ordine delle dimensioni aggiungendo l’opzione -r (reverse) al comando di ordinamento e usando head invece di tail per scegliere le linee dall’alto dell’output.

Questa volta i cinque file “.page” più grandi sono elencati dal più grande al più piccolo:
Alcuni esempi recenti
Ecco due esempi interessanti tratti da recenti articoli geek How-To.
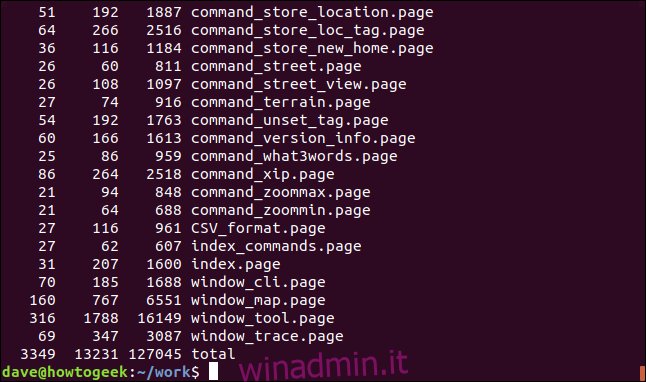
Alcuni comandi, come xargscommand, sono progettati per avere l’input trasmesso a loro. Ecco un modo in cui possiamo far contare i file parole, caratteri e linee in più file, inserendo ls in xargs che quindi alimenta l’elenco dei nomi di file a wc come se fossero stati passati a wc come parametri della riga di comando.
ls *.page | xargs wc

Il numero totale di parole, caratteri e righe è elencato nella parte inferiore della finestra del terminale.
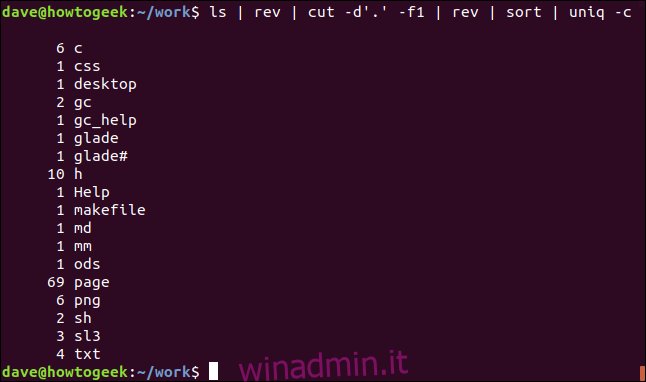
Ecco un modo per ottenere un elenco ordinato delle estensioni di file univoche nella directory corrente, con un conteggio di ciascun tipo.
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c

C’è molto da fare qui.
ls: elenca i file nella directory
rev: Inverte il testo nei nomi dei file.
taglio: Taglia la corda alla prima occorrenza del delimitatore specificato “.”. Il testo dopo questo viene scartato.
rev: inverte il testo rimanente, che è l’estensione del nome del file.
ordina: ordina l’elenco alfabeticamente.
uniq: conta il numero di ciascuno voce univoca nell’elenco.
L’output mostra l’elenco delle estensioni di file, in ordine alfabetico con un conteggio di ogni tipo univoco.
Named Pipes
C’è un altro tipo di pipe a nostra disposizione, chiamato named pipe. Le pipe negli esempi precedenti vengono create al volo dalla shell quando elabora la riga di comando. I tubi vengono creati, utilizzati e quindi eliminati. Sono transitori e non lasciano traccia di se stessi. Esistono solo finché il comando che li utilizza è in esecuzione.
Le pipe con nome appaiono come oggetti persistenti nel filesystem, quindi puoi vederle usando ls. Sono persistenti perché sopravvivranno al riavvio del computer, sebbene tutti i dati non letti in essi contenuti in quel momento verranno eliminati.
Le pipe con nome sono state utilizzate molto contemporaneamente per consentire a diversi processi di inviare e ricevere dati, ma non le vedo usate in questo modo da molto tempo. Senza dubbio ci sono persone là fuori che ancora li usano con grande effetto, ma non ne ho incontrati di recente. Ma per completezza, o semplicemente per soddisfare la tua curiosità, ecco come puoi usarli.
Le pipe con nome vengono create con il comando mkfifo. Questo comando creerà una pipe con nome chiamato “geek-pipe” nella directory corrente.
mkfifo geek-pipe

Possiamo vedere i dettagli della named pipe se usiamo il comando ls con l’opzione -l (formato lungo):
ls -l geek-pipe

Il primo carattere dell’elenco è una “p”, che significa che è una pipa. Se fosse una “d”, significherebbe che l’oggetto del file system è una directory e un trattino “-” significherebbe che è un file normale.
Utilizzando il tubo denominato
Usiamo la nostra pipa. Le pipe senza nome che abbiamo usato nei nostri esempi precedenti hanno passato i dati immediatamente dal comando di invio al comando di ricezione. I dati inviati tramite una named pipe rimarranno nella pipe fino a quando non verranno letti. I dati sono effettivamente conservati in memoria, quindi la dimensione della named pipe non varierà negli elenchi ls indipendentemente dal fatto che vi siano dati o meno.
Useremo due finestre di terminale per questo esempio. Userò l’etichetta:
# Terminal-1
in una finestra di terminale e
# Terminal-2
nell’altro, in modo da poter distinguere tra loro. L’hash “#” dice alla shell che ciò che segue è un commento e di ignorarlo.
Prendiamo la totalità del nostro esempio precedente e reindirizziamolo nella named pipe. Quindi stiamo usando sia pipe senza nome che named in un comando:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c > geek-pipe

Stiamo reindirizzando il contenuto della named pipe in cat, in modo che cat visualizzerà quel contenuto nella seconda finestra del terminale. Ecco l'output:
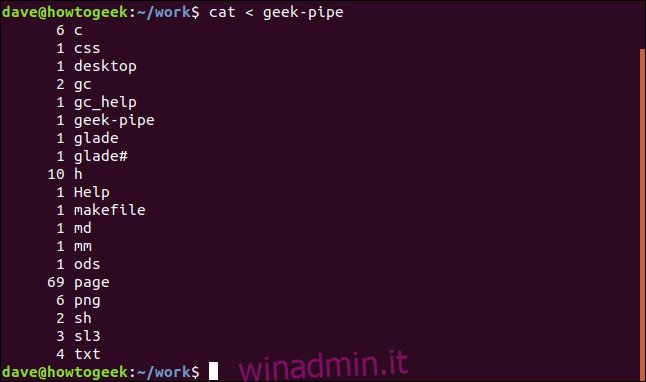
E vedrai che sei stato riportato al prompt dei comandi nella prima finestra del terminale.

Allora, cosa è appena successo.
Abbiamo reindirizzato alcuni output nella named pipe.
La prima finestra di terminale non è tornata al prompt dei comandi.
I dati sono rimasti nel tubo fino a quando non sono stati letti dal tubo nel secondo terminale.
Siamo stati riportati al prompt dei comandi nella prima finestra del terminale.
Potresti pensare di poter eseguire il comando nella prima finestra del terminale come attività in background aggiungendo una & alla fine del comando. E avresti ragione. In tal caso, saremmo tornati immediatamente al prompt dei comandi.
Lo scopo di non utilizzare l'elaborazione in background era evidenziare che una named pipe è un processo di blocco. Mettere qualcosa in una pipe con nome apre solo un'estremità della pipe. L'altra estremità non viene aperta finché il programma di lettura non estrae i dati. Il kernel sospende il processo nella prima finestra del terminale fino a quando i dati non vengono letti dall'altra estremità del pipe.
Il potere dei tubi
Al giorno d'oggi, le pipe con nome sono qualcosa di una novità.
I semplici vecchi pipe di Linux, d'altra parte, sono uno degli strumenti più utili che puoi avere nel tuo toolkit della finestra del terminale. La riga di comando di Linux inizia a prendere vita per te e ottieni un nuovo potenziamento quando puoi orchestrare una raccolta di comandi per produrre una prestazione coerente.
Suggerimento di separazione: è meglio scrivere i comandi in pipe aggiungendo un comando alla volta e facendo funzionare quella parte, quindi piping nel comando successivo.