
Reddit offre feed JSON per ogni subreddit. Ecco come creare uno script Bash che scarica e analizza un elenco di post da qualsiasi subreddit che ti piace. Questa è solo una cosa che puoi fare con i feed JSON di Reddit.
Sommario:
Installazione di Curl e JQ
Utilizzeremo curl per recuperare il feed JSON da Reddit e jq per analizzare i dati JSON ed estrarre i campi desiderati dai risultati. Installa queste due dipendenze usando apt-get su Ubuntu e altre distribuzioni Linux basate su Debian. Su altre distribuzioni Linux, utilizza invece lo strumento di gestione dei pacchetti della tua distribuzione.
sudo apt-get install curl jq
Recupera alcuni dati JSON da Reddit
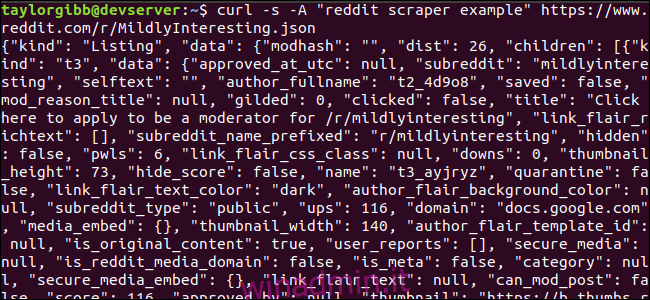
Vediamo come appare il feed di dati. Usa curl per recuperare gli ultimi post dal file Leggermente interessante subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Nota come le opzioni usate prima dell’URL: -s costringono curl a essere eseguito in modalità silenziosa in modo da non vedere alcun output, tranne i dati dai server di Reddit. L’opzione successiva e il parametro che segue, -A “reddit scraper example”, imposta una stringa di user agent personalizzata che aiuta Reddit a identificare il servizio che accede ai propri dati. I server API Reddit applicano limiti di velocità basati sulla stringa dell’agente utente. L’impostazione di un valore personalizzato farà sì che Reddit segmenterà il nostro limite di velocità lontano da altri chiamanti e ridurrà la possibilità di ottenere un errore HTTP 429 Rate Limit Exceeded.
L’output dovrebbe riempire la finestra del terminale e assomigliare a questo:
Ci sono molti campi nei dati di output, ma tutto ciò che ci interessa sono Titolo, Permalink e URL. Puoi vedere un elenco completo dei tipi e dei loro campi nella pagina della documentazione API di Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Estrazione di dati dall’output JSON
Vogliamo estrarre Titolo, Permalink e URL dai dati di output e salvarli in un file delimitato da tabulazioni. Possiamo usare strumenti di elaborazione del testo come sed e grep, ma abbiamo un altro strumento a nostra disposizione che comprende le strutture dati JSON, chiamato jq. Per il nostro primo tentativo, usiamolo per stampare e codificare a colori l’output. Useremo la stessa chiamata di prima, ma questa volta, inviamo l’output attraverso jq e gli istruiremo per analizzare e stampare i dati JSON.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Annotare il punto che segue il comando. Questa espressione analizza semplicemente l’input e lo stampa così com’è. L’output sembra ben formattato e codificato a colori:
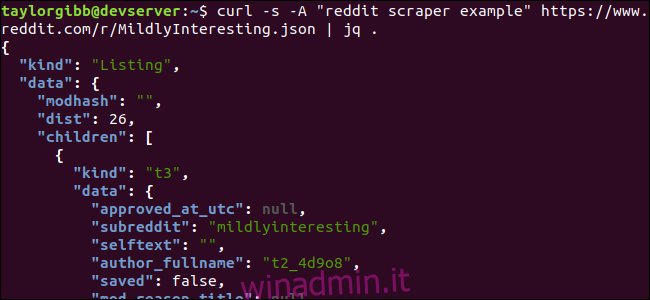
Esaminiamo la struttura dei dati JSON che otteniamo da Reddit. Il risultato principale è un oggetto che contiene due proprietà: tipo e dati. Quest’ultimo possiede una proprietà chiamata children, che include una serie di post in questo subreddit.
Ogni elemento dell’array è un oggetto che contiene anche due campi chiamati tipo e dati. Le proprietà che vogliamo catturare sono nell’oggetto dati. jq si aspetta un’espressione che può essere applicata ai dati di input e produce l’output desiderato. Deve descrivere i contenuti in termini di gerarchia e appartenenza a un array, nonché come trasformare i dati. Eseguiamo di nuovo l’intero comando con l’espressione corretta:
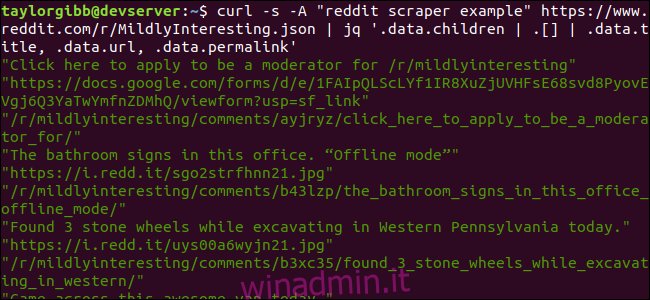
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
L’output mostra Titolo, URL e Permalink ciascuno sulla propria riga:
Immergiamoci nel comando jq che abbiamo chiamato:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Ci sono tre espressioni in questo comando separate da due simboli pipe. I risultati di ciascuna espressione vengono passati alla successiva per un’ulteriore valutazione. La prima espressione filtra tutto tranne l’array di elenchi di Reddit. Questo output viene reindirizzato nella seconda espressione e forzato in un array. La terza espressione agisce su ogni elemento dell’array ed estrae tre proprietà. Maggiori informazioni su jq e la sua sintassi delle espressioni possono essere trovate in manuale ufficiale di jq.
Mettere tutto insieme in uno script
Mettiamo insieme la chiamata API e la post-elaborazione JSON in uno script che genererà un file con i post desiderati. Aggiungeremo il supporto per il recupero dei post da qualsiasi subreddit, non solo / r / MildlyInteresting.
Apri il tuo editor e copia il contenuto di questo frammento in un file chiamato scrape-reddit.sh
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Questo script verificherà prima se l’utente ha fornito un nome subreddit. In caso contrario, esce con un messaggio di errore e un codice di ritorno diverso da zero.
Successivamente, memorizzerà il primo argomento come nome del subreddit e creerà un nome file con la data in cui verrà salvato l’output.
L’azione inizia quando curl viene chiamato con un’intestazione personalizzata e l’URL del subreddit da scrape. L’output viene reindirizzato a jq dove viene analizzato e ridotto a tre campi: Titolo, URL e Permalink. Queste righe vengono lette, una alla volta, e salvate in una variabile utilizzando il comando read, tutto all’interno di un ciclo while, che continuerà fino a quando non ci saranno più righe da leggere. L’ultima riga del blocco while interno fa eco ai tre campi, delimitati da un carattere di tabulazione, quindi lo convoglia tramite il comando tr in modo che le virgolette doppie possano essere eliminate. L’output viene quindi aggiunto a un file.
Prima di poter eseguire questo script, dobbiamo assicurarci che gli siano state concesse le autorizzazioni di esecuzione. Usa il comando chmod per applicare queste autorizzazioni al file:
chmod u+x scrape-reddit.sh
Infine, esegui lo script con un nome subreddit:
./scrape-reddit.sh MildlyInteresting
Un file di output viene generato nella stessa directory e il suo contenuto sarà simile a questo:
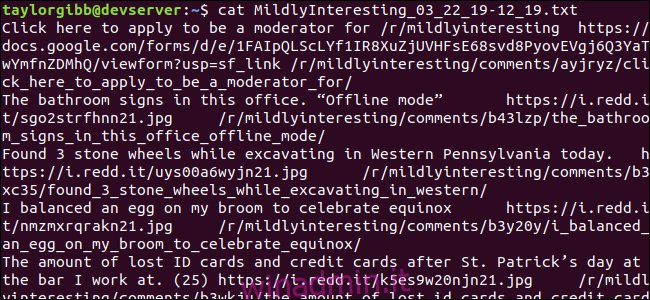
Ogni riga contiene i tre campi che stiamo cercando, separati da un carattere di tabulazione.
Andare avanti
Reddit è una miniera d’oro di contenuti e media interessanti ed è tutto facilmente accessibile tramite la sua API JSON. Ora che hai un modo per accedere a questi dati ed elaborare i risultati puoi fare cose come:
Prendi gli ultimi titoli da / r / WorldNews e inviali al tuo desktop usando notifica-invio
Integra le migliori battute di / r / DadJokes nel Message-Of-The-Day del tuo sistema
Ottieni la migliore immagine di oggi da / r / aww e rendila lo sfondo del desktop
Tutto questo è possibile utilizzando i dati forniti e gli strumenti che hai sul tuo sistema. Buon hacking!