
Il web scraping consente di raccogliere in modo efficiente grandi quantità di dati da Internet in modo molto veloce ed è particolarmente utile nei casi in cui i siti Web non espongono i propri dati in modo strutturato attraverso l’uso di API (Application Programming Interface).
Ad esempio, immagina di creare un’applicazione che confronti i prezzi degli articoli su siti di e-commerce. Come procederesti? Un modo è controllare manualmente il prezzo degli articoli su tutti i siti e registrare i risultati. Tuttavia, questo non è un modo intelligente poiché ci sono migliaia di prodotti sulle piattaforme di e-commerce e ci vorrebbe un’eternità per estrarre i dati rilevanti.
Un modo migliore per farlo è attraverso il web scraping. Il web scraping è il processo di estrazione automatica dei dati da pagine web e siti web attraverso l’uso di software.
Gli script software, denominati web scraper, vengono utilizzati per accedere ai siti Web e recuperare dati dai siti Web. I dati recuperati, solitamente in forma non strutturata, possono quindi essere analizzati e archiviati in modo strutturato che sia significativo per gli utenti.
Il web scraping è molto prezioso nell’estrazione dei dati in quanto fornisce l’accesso a una grande quantità di dati e consente l’automazione, in modo tale da poter pianificare l’esecuzione dello script di web scraping in determinati orari o in risposta a determinati trigger. Il web scraping ti consente inoltre di ottenere aggiornamenti in tempo reale e semplifica la conduzione di ricerche di mercato.

Molte aziende e aziende si affidano al web scraping per estrarre dati da analizzare. Le aziende specializzate in risorse umane, e-commerce, finanza, settore immobiliare, viaggi, social media e ricerca utilizzano il web scraping per estrarre dati rilevanti dai siti web.
Google stessa utilizza il web scraping per indicizzare i siti web su Internet in modo da poter fornire risultati di ricerca pertinenti agli utenti.
Tuttavia, è importante prestare attenzione durante la rottamazione del web. Sebbene lo scraping dei dati accessibili al pubblico non sia illegale, alcuni siti Web non consentono lo scraping. Ciò potrebbe essere dovuto al fatto che dispongono di informazioni sensibili sugli utenti, che i loro termini di servizio vietano esplicitamente il web scraping o che proteggono la proprietà intellettuale.
Inoltre, alcuni siti Web non consentono il web scraping in quanto può sovraccaricare il server del sito Web e comportare un aumento dei costi della larghezza di banda, soprattutto quando il web scraping viene eseguito su larga scala.
Per verificare se un sito web può essere eliminato, aggiungi robots.txt all’URL del sito web. robots.txt viene utilizzato per indicare ai bot quali parti del sito Web possono essere raschiate. Ad esempio, per verificare se riesci a raschiare Google, vai su google.com/robots.txt
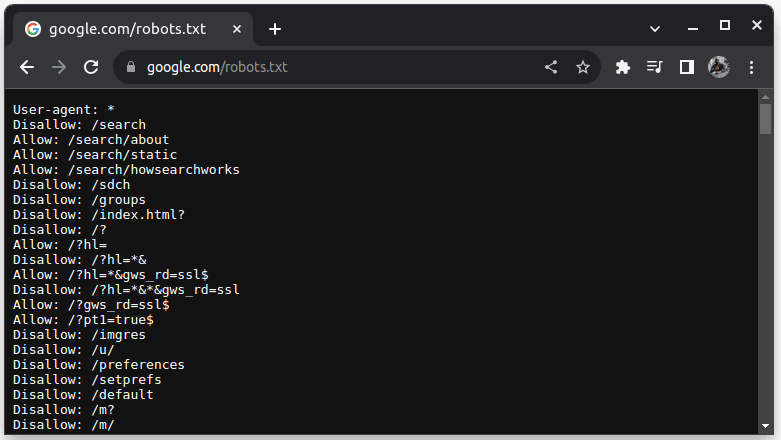
User-agent: * si riferisce a tutti i bot o script software e crawler. Disallow viene utilizzato per dire ai bot che non possono accedere a nessun URL in una directory, ad esempio /search. Consenti indica le directory da cui possono accedere agli URL.
Un esempio di sito che non consente lo scraping è LinkedIn. Per verificare se riesci a raschiare LinkedIn, vai su linkedin.com/robots.txt
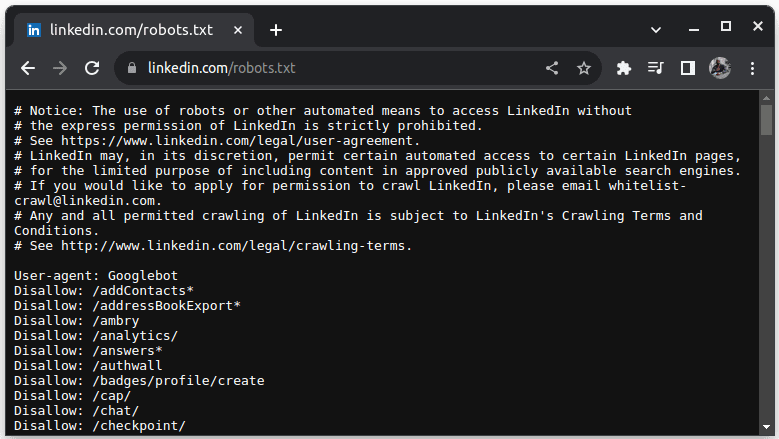
Come puoi vedere, non ti è consentito eseguire lo scraping di LinkedIn senza il loro permesso. Controlla sempre se un sito Web consente lo scraping per evitare problemi legali.
Sommario:
Perché Java è un linguaggio adatto per il Web Scraping
Sebbene sia possibile creare un web scraper con una varietà di linguaggi di programmazione, Java è particolarmente ideale per questo lavoro per una serie di motivi. Innanzitutto, Java ha un ricco ecosistema e una vasta comunità e fornisce una varietà di librerie di web scraping come JSoup, WebMagic e HTMLUnit, che semplificano la scrittura di web scraper.

Fornisce inoltre librerie di analisi HTML per semplificare il processo di estrazione dei dati da documenti HTML e librerie di rete come HttpURLConnection per effettuare richieste a diversi URL di siti Web.
Il forte supporto di Java per la concorrenza e il multithreading è utile anche nel web scraping poiché consente l’elaborazione parallela e la gestione di attività di web scraping con richieste multiple, consentendo di eseguire lo scraping di più pagine contemporaneamente. Poiché la scalabilità è un punto di forza di Java, puoi comodamente raschiare siti Web su larga scala utilizzando un web scraper scritto in Java.
Anche il supporto multipiattaforma di Java è utile in quanto consente di scrivere un web scraper ed eseguirlo in qualsiasi sistema dotato di una Java Virtual Machine compatibile. Pertanto, è possibile scrivere un web scraper in un sistema operativo o dispositivo ed eseguirlo in un sistema operativo diverso senza la necessità di modificare il web scraper.
Java può essere utilizzato anche con browser headless come Headless Chrome, HTML Unit, Headless Firefox e PhantomJs, tra gli altri. Un browser headless è un browser senza interfaccia utente grafica. I browser headless possono simulare le interazioni dell’utente e sono molto utili quando si recuperano siti Web che richiedono interazioni dell’utente.
Per finire, Java è un linguaggio molto popolare e ampiamente utilizzato che è supportato e può essere facilmente integrato con una varietà di strumenti come database e framework di elaborazione dati. Ciò è vantaggioso perché garantisce che durante la raccolta dei dati, tutti gli strumenti necessari per la raccolta, l’elaborazione e l’archiviazione dei dati probabilmente supportino Java.
Vediamo come possiamo utilizzare Java per il web scrapping.
Java per Web Scraping: prerequisiti
Per utilizzare Java nel web scraping, devono essere soddisfatti i seguenti prerequisiti:
1. Java: dovresti avere Java installato, preferibilmente l’ultima versione con supporto a lungo termine. Nel caso in cui Java non sia installato, vai su Installa Java per sapere come installare Java sul tuo computer
2. Ambiente di sviluppo integrato (IDE): dovresti avere un IDE installato sul tuo computer. In questo tutorial utilizzeremo IntelliJ IDEA, ma puoi utilizzare qualsiasi IDE con cui hai familiarità.
3. Maven: verrà utilizzato per la gestione delle dipendenze e per installare una libreria di web scraping.
Nel caso in cui Maven non sia installato, puoi installarlo aprendo il terminale ed eseguendo:
sudo apt install maven
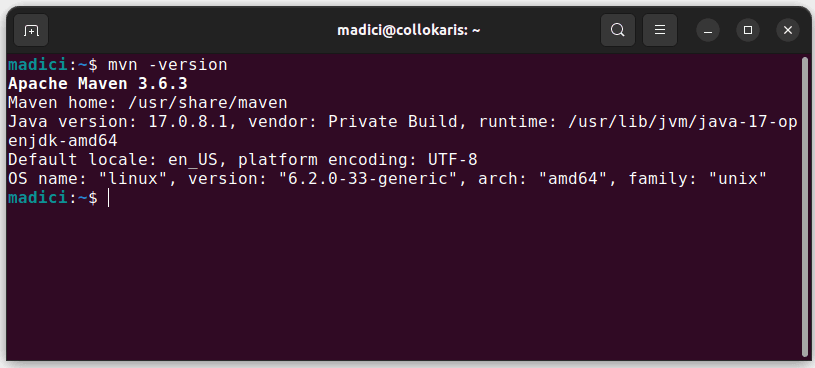
Questo installa Maven dal repository ufficiale. Puoi confermare che Maven è stato installato correttamente eseguendo:
mvn -version
Nel caso in cui l’installazione abbia avuto successo, dovresti ottenere un output del genere:
Impostazione dell’ambiente
Per configurare il tuo ambiente:
1. Apri IntelliJ IDEA. Sulla barra dei menu a sinistra, fai clic su Progetti, quindi seleziona Nuovo progetto.
2. Nella finestra Nuovo progetto che si apre, riempila come mostrato di seguito. Assicurati che la lingua sia impostata su Java e il sistema di compilazione su Maven. Puoi dare al progetto il nome che preferisci, quindi utilizzare Posizione per specificare la cartella in cui desideri creare il progetto. Una volta terminato, fai clic su Crea.
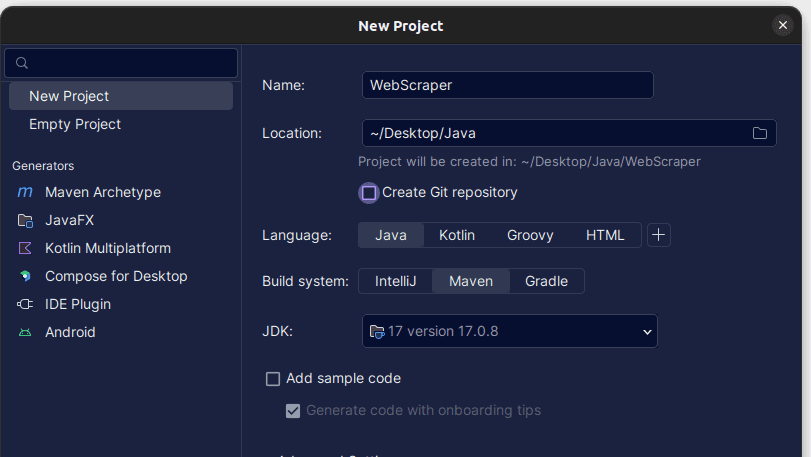
3. Una volta creato il progetto, dovresti avere un pom.xml nel tuo progetto come mostrato di seguito.
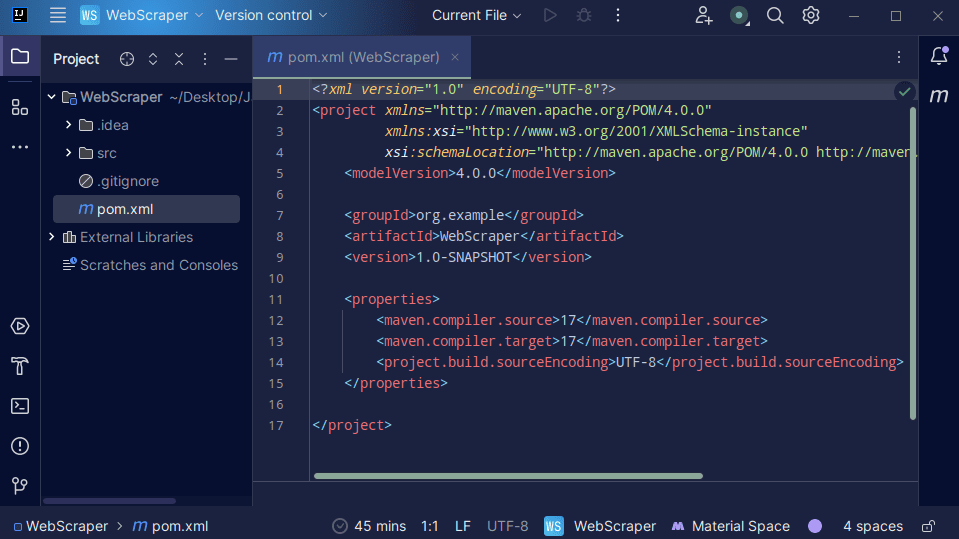
Il file pom.xml viene creato da Maven e contiene informazioni sul progetto e dettagli di configurazione utilizzati da Maven per creare il progetto. È questo file che utilizziamo anche per indicare che utilizzeremo librerie esterne.
Nella creazione di un web scraper, utilizzeremo la libreria jsoup. Dobbiamo quindi aggiungerlo come dipendenza nel file pom.xml in modo che Maven possa renderlo disponibile nel nostro progetto.
4. Aggiungi la dipendenza jsoup nel file pom.xml copiando il codice seguente e aggiungendolo al file pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Il risultato dovrebbe essere quello mostrato di seguito:
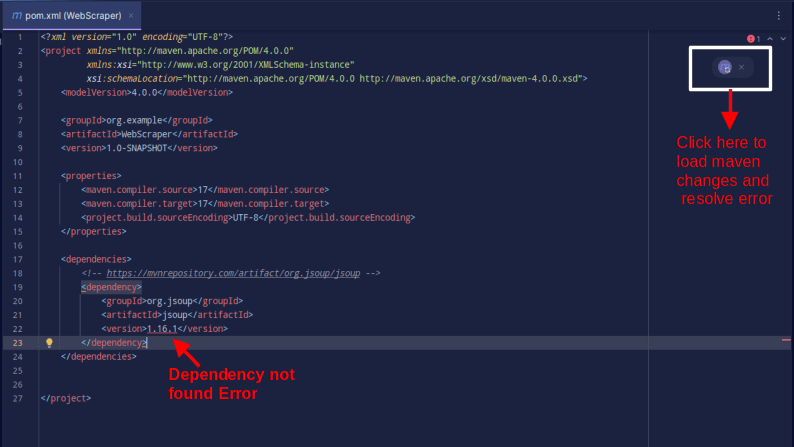
Nel caso in cui riscontri un errore che indica che la dipendenza non può essere trovata, fai clic sull’icona indicata per Maven per caricare le modifiche apportate, caricare la dipendenza e rimuovere l’errore.
Con ciò, il tuo ambiente è completamente impostato.
Web scraping con Java
Per lo scraping web, estrarremo i dati da ScrapeThisSiteche fornisce una sandbox in cui gli sviluppatori possono esercitarsi nel web scraping senza incorrere in problemi legali.
Per raschiare un sito Web utilizzando Java
1. Sulla barra dei menu a sinistra su IntelliJ, aprire la directory src, quindi la directory principale, che si trova all’interno della directory src. La directory principale contiene una directory chiamata java; fare clic con il tasto destro su di esso e selezionare Nuovo, quindi Classe Java
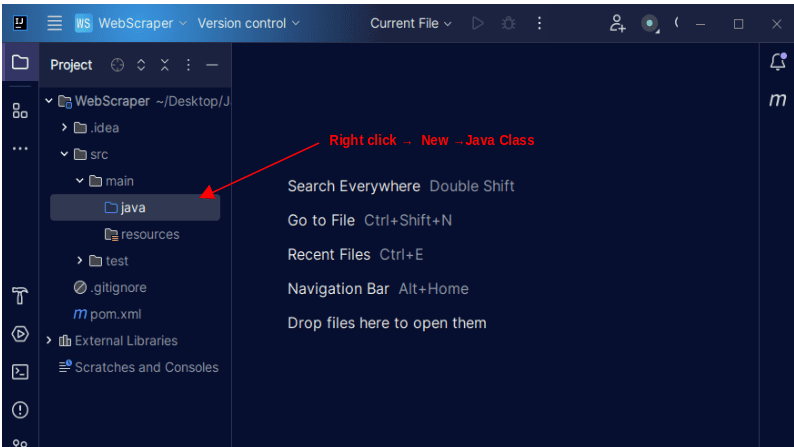
Assegna alla classe il nome che preferisci, ad esempio WebScraper, quindi premi Invio per creare una nuova classe Java.
Apri il file appena creato contenente le classi Java appena create.
2. Il Web scraping implica l’acquisizione di dati dai siti Web. Pertanto, dobbiamo specificare l’URL da cui vogliamo recuperare i dati. Una volta specificato l’URL, dobbiamo connetterci all’URL ed effettuare una richiesta GET per recuperare il contenuto HTML della pagina.
Il codice che fa ciò è mostrato di seguito:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Produzione:
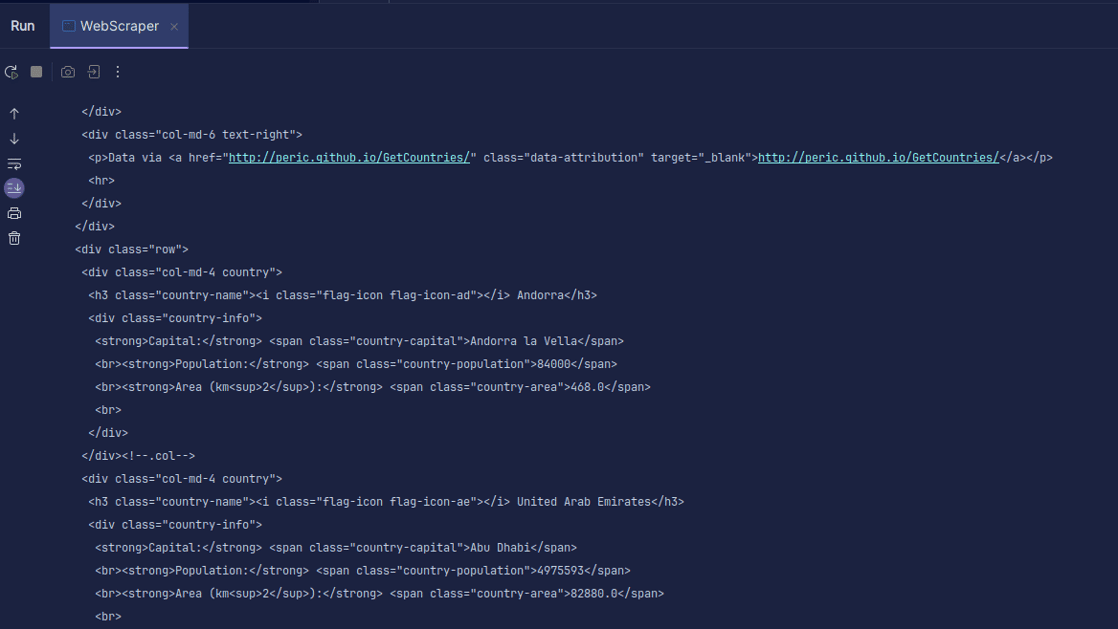
Come puoi vedere, viene restituito l’HTML della pagina ed è ciò che stiamo stampando. Durante lo scraping, l’URL specificato potrebbe contenere un errore e la risorsa che stai tentando di eseguire lo scraping potrebbe non esistere affatto. Ecco perché è importante racchiudere il nostro codice in un’istruzione try-catch.
La linea:
Document doc = Jsoup.connect(url).get();
Viene utilizzato per connettersi all’URL che desideri raschiare. Il metodo get() viene utilizzato per effettuare una richiesta GET e recuperare l’HTML sulla pagina. Il risultato restituito viene quindi archiviato in un oggetto Documento JSOUP, denominato doc. La memorizzazione del risultato in un documento JSOUP consente di utilizzare l’API JSOUP per manipolare l’HTML restituito.
3. Vai a ScrapeThisSite e ispezionare la pagina. Nell’HTML, dovresti vedere la struttura mostrata di seguito:
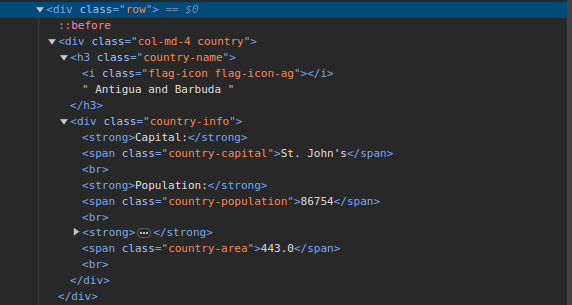
Tieni presente che tutti i paesi nella pagina sono archiviati in una struttura simile. C’è un div con una classe chiamata country con un elemento h3 con una classe country-name contenente il nome di ciascun paese nella pagina.
All’interno del div principale, c’è un altro div con una classe di informazioni sul paese e contiene informazioni come capitale, popolazione e area del paese. Possiamo usare questi nomi di classi per selezionare gli elementi HTML ed estrarre informazioni da essi.
4. Estrai il contenuto specifico dall’HTML sulla pagina utilizzando le seguenti righe:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Stiamo utilizzando il metodo select() per selezionare gli elementi dall’HTML della pagina che corrispondono allo specifico selettore CSS che passiamo. Nel nostro caso, passiamo i nomi delle classi. Dall’ispezione della pagina, abbiamo visto che tutte le informazioni sul paese nella pagina sono archiviate sotto un div con una classe di paese.
Ogni paese ha il proprio div con una classe di paese e il div contiene informazioni come il nome del paese, la capitale e la popolazione.
Pertanto, selezioniamo prima tutti i paesi nella pagina utilizzando la classe .country. Quindi lo memorizziamo in una variabile chiamata paesi di tipo Elementi, che funziona proprio come un elenco. Utilizziamo quindi un ciclo for per esplorare i paesi ed estrarre il nome del paese, la capitale e la popolazione e stampare ciò che viene trovato.
La nostra intera base di codice è mostrata di seguito:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Produzione:
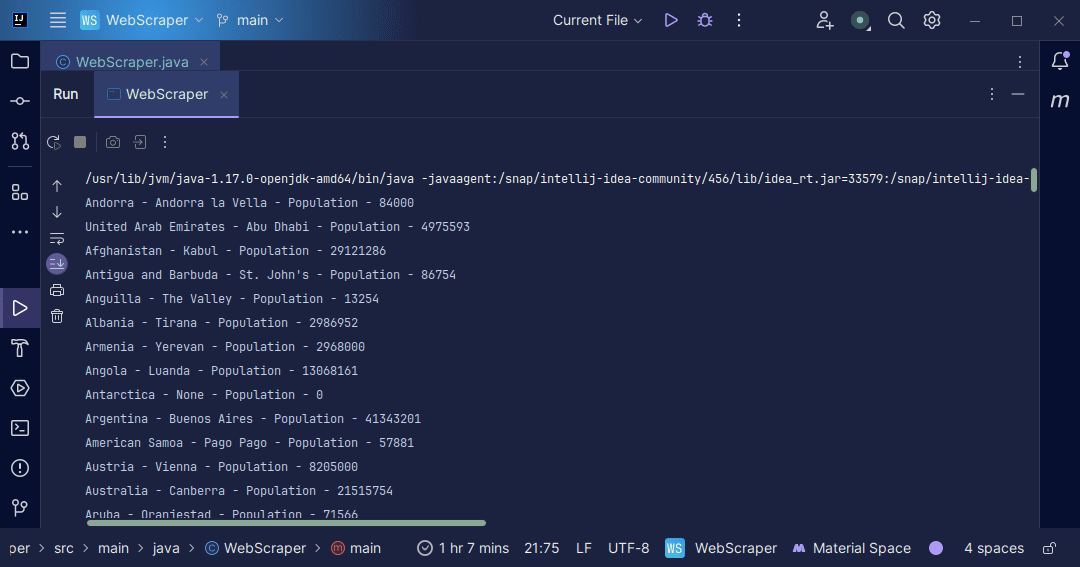
Con le informazioni che otteniamo dalla pagina, possiamo fare una serie di cose, come stamparle come abbiamo appena fatto o archiviarle in un file nel caso in cui desideriamo eseguire un’ulteriore elaborazione dei dati.
Conclusione
Il web scraping è un modo eccellente per estrarre dati non strutturati da siti Web, archiviare i dati in modo strutturato ed elaborare i dati per estrarre informazioni significative. Tuttavia, è importante prestare attenzione durante il web scraping, poiché alcuni siti Web non consentono il web scraping.
Per sicurezza, utilizza i siti Web che forniscono sandbox per esercitarti nella rottamazione. Altrimenti, controlla sempre il file robots.txt di ogni sito web che desideri eliminare per scoprire se il sito Web consente lo scraping.
quando si scrive web scrapper, Java è un linguaggio eccellente in quanto fornisce librerie che rendono il web scraping più semplice ed efficiente. Come sviluppatore Java, costruire un web scraper ti aiuterà a sviluppare ulteriormente le tue capacità di programmazione. Quindi vai avanti e scrivi il tuo web scrapper o modifica quello utilizzato nell’articolo per estrarre diversi tipi di informazioni. Buona programmazione!
Puoi anche esplorare alcune popolari soluzioni di web scraping basate su cloud.