
Milioni di record di dati vengono generati ogni singolo giorno nei sistemi informatici odierni. Questi includono le transazioni finanziarie, l’effettuazione di un ordine o i dati del sensore dell’auto. Per elaborare questi eventi di flusso di dati in tempo reale e per spostare in modo affidabile i record degli eventi tra diversi sistemi aziendali, è necessario Apache Kafka.
Apache Kafka è una soluzione di streaming di dati open source che gestisce oltre 1 milione di record al secondo. Oltre a questo elevato throughput, Apache Kafka offre elevata scalabilità e disponibilità, bassa latenza e archiviazione permanente.
Aziende come LinkedIn, Uber e Netflix si affidano ad Apache Kafka per l’elaborazione in tempo reale e lo streaming dei dati. Il modo più semplice per iniziare con Apache Kafka è averlo installato e funzionante sul tuo computer locale. Ciò ti consente non solo di vedere il server Apache Kafka in azione, ma anche di produrre e consumare messaggi.
Con l’esperienza pratica nell’avvio del server, nella creazione di argomenti e nella scrittura di codice Java utilizzando il client Kafka, sarai pronto a utilizzare Apache Kafka per soddisfare tutte le tue esigenze di pipeline di dati.
Sommario:
Come scaricare Apache Kafka sul tuo computer locale
È possibile scaricare l’ultima versione di Apache Kafka dal file link ufficiale. Il contenuto scaricato verrà compresso in formato .tgz. Una volta scaricato, dovrai estrarre lo stesso.
Se sei Linux, apri il tuo terminale. Successivamente, vai alla posizione in cui hai scaricato la versione compressa di Apache Kafka. Esegui il seguente comando:
tar -xzvf kafka_2.13-3.5.0.tgz
Al termine del comando, troverai una nuova directory chiamata kafka_2.13-3.5.0. Navigare all’interno della cartella utilizzando:
cd kafka_2.13-3.5.0
Ora puoi elencare il contenuto di questa directory usando il comando ls.
Per gli utenti Windows, puoi seguire gli stessi passaggi. Se non riesci a trovare il comando tar, puoi utilizzare uno strumento di terze parti come WinZip per aprire l’archivio.
Come avviare Apache Kafka sul tuo computer locale
Dopo aver scaricato ed estratto Apache Kafka, è ora di iniziare a eseguirlo. Non ha programmi di installazione. Puoi iniziare a usarlo direttamente tramite la riga di comando o la finestra del terminale.
Prima di iniziare con Apache Kafka, assicurati di avere Java 8+ installato sul tuo sistema. Apache Kafka richiede un’installazione Java in esecuzione.
#1. Esegui il server Apache Zookeeper
Il primo passo è eseguire Apache Zookeeper. Lo ottieni pre-scaricato come parte dell’archivio. È un servizio responsabile della gestione delle configurazioni e della sincronizzazione per altri servizi.
Una volta che sei all’interno della directory in cui hai estratto il contenuto dell’archivio, esegui il seguente comando:
Per utenti Linux:
bin/zookeeper-server-start.sh config/zookeeper.properties
Per utenti Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
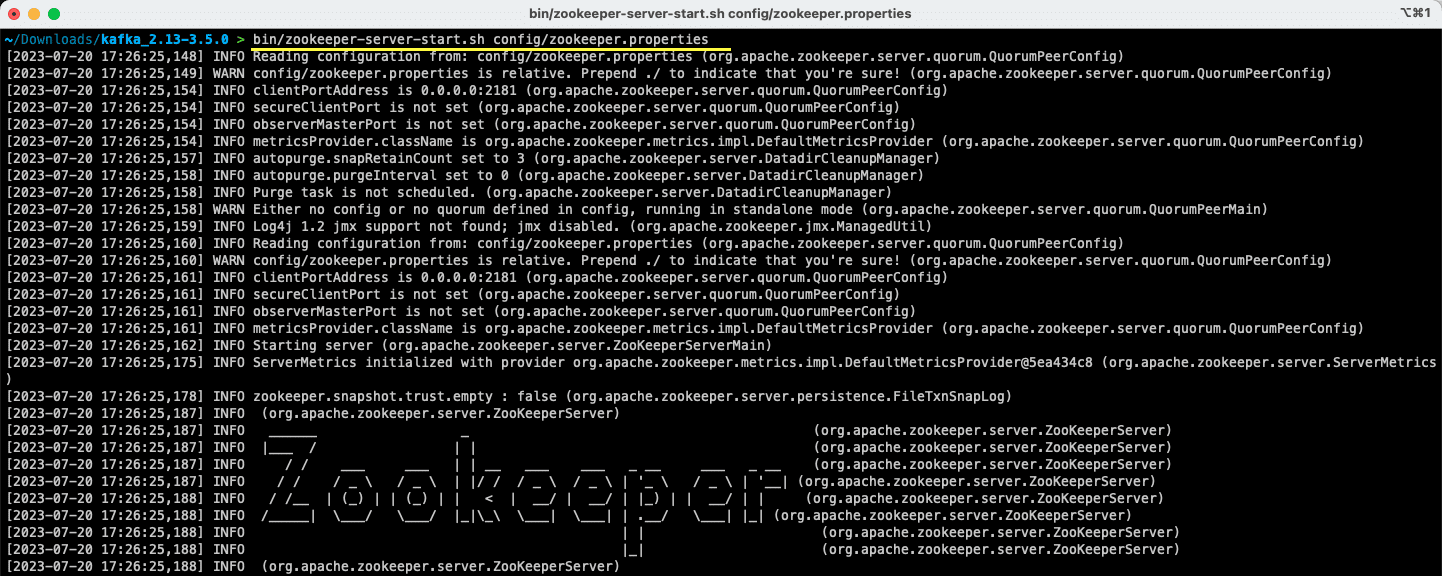
Il file zookeeper.properties fornisce le configurazioni per l’esecuzione del server Apache Zookeeper. È possibile configurare proprietà come la directory locale in cui verranno archiviati i dati e la porta su cui verrà eseguito il server.
#2. Avvia il server Apache Kafka
Ora che il server Apache Zookeeper è stato avviato, è il momento di avviare il server Apache Kafka.
Apri un nuovo terminale o una finestra del prompt dei comandi e vai alla directory in cui sono presenti i file estratti. Quindi puoi avviare il server Apache Kafka usando il comando seguente:
Per utenti Linux:
bin/kafka-server-start.sh config/server.properties
Per utenti Windows:
bin/windows/kafka-server-start.bat config/server.properties
Hai il tuo server Apache Kafka in esecuzione. Nel caso in cui si desideri modificare la configurazione predefinita, è possibile farlo modificando il file server.properties. I diversi valori sono presenti nel documentazione ufficiale.
Come usare Apache Kafka sul tuo computer locale
Ora sei pronto per iniziare a utilizzare Apache Kafka sul tuo computer locale per produrre e consumare messaggi. Poiché i server Apache Zookeeper e Apache Kafka sono attivi e funzionanti, vediamo come puoi creare il tuo primo argomento, produrre il tuo primo messaggio e consumare lo stesso.
Quali sono i passaggi per creare un argomento in Apache Kafka?
Prima di creare il tuo primo argomento, cerchiamo di capire cos’è effettivamente un argomento. In Apache Kafka, un argomento è un archivio dati logico che aiuta nello streaming dei dati. Pensalo come il canale attraverso il quale i dati vengono trasportati da un componente all’altro.
Un argomento supporta multi-produttori e multi-consumatori: più di un sistema può scrivere e leggere da un argomento. A differenza di altri sistemi di messaggistica, qualsiasi messaggio di un argomento può essere consumato più di una volta. Inoltre, puoi anche menzionare il periodo di conservazione dei tuoi messaggi.
Prendiamo l’esempio di un sistema (produttore) che produce dati per transazioni bancarie. E un altro sistema (consumatore) consuma questi dati e invia una notifica dell’app all’utente. Per facilitare questo, è necessario un argomento.
Apri un nuovo terminale o una finestra del prompt dei comandi e vai alla directory in cui hai estratto l’archivio. Il seguente comando creerà un argomento chiamato transazioni:
Per utenti Linux:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Per utenti Windows:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
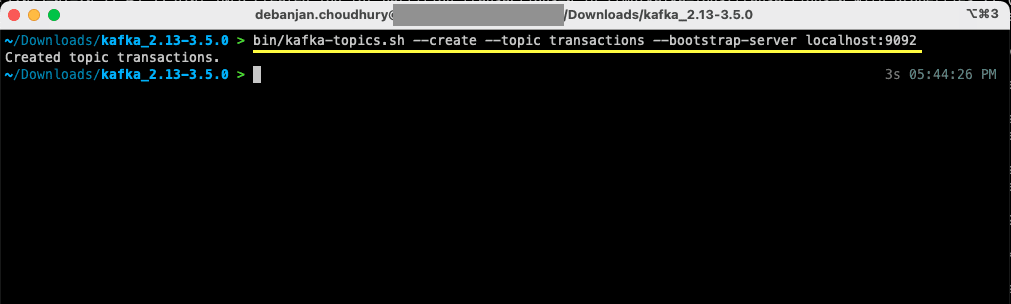
Ora hai creato il tuo primo argomento e sei pronto per iniziare a produrre e consumare messaggi.
Come produrre un messaggio per Apache Kafka?
Con il tuo argomento Apache Kafka pronto, ora puoi produrre il tuo primo messaggio. Apri un nuovo terminale o una finestra del prompt dei comandi oppure usa lo stesso che hai usato per creare l’argomento. Successivamente, assicurati di essere nella directory corretta in cui hai estratto il contenuto dell’archivio. Puoi utilizzare la riga di comando per produrre il tuo messaggio sull’argomento utilizzando il seguente comando:
Per utenti Linux:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Per utenti Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Una volta eseguito il comando, vedrai che il tuo terminale o la finestra del prompt dei comandi è in attesa di input. Scrivi il tuo primo messaggio e premi Invio.
> This is a transactional record for $100
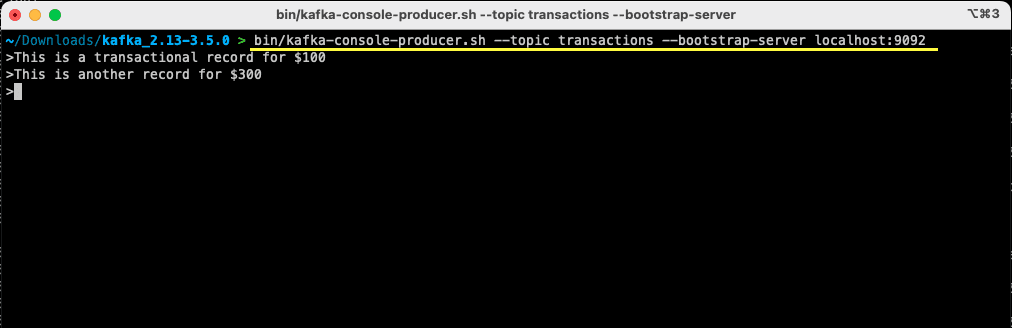
Hai prodotto il tuo primo messaggio per Apache Kafka sul tuo computer locale. Successivamente, ora sei pronto per consumare questo messaggio.
Come consumare un messaggio da Apache Kafka?
A condizione che il tuo argomento sia stato creato e tu abbia prodotto un messaggio per il tuo argomento Kafka, ora puoi consumare quel messaggio.
Apache Kafka ti consente di collegare più consumatori allo stesso argomento. Ogni consumatore può far parte di un gruppo di consumatori – un identificatore logico. Ad esempio, se disponi di due servizi che devono consumare gli stessi dati, possono avere gruppi di consumatori diversi.
Tuttavia, se disponi di due istanze dello stesso servizio, ti consigliamo di evitare di consumare ed elaborare lo stesso messaggio due volte. In tal caso, entrambi avranno lo stesso gruppo di consumatori.
Nel terminale o nella finestra del prompt dei comandi, assicurati di essere nella directory corretta. Utilizzare il seguente comando per avviare il consumatore:
Per utenti Linux:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Per utenti Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Vedrai apparire sul tuo terminale il messaggio che hai precedentemente prodotto. Ora hai utilizzato Apache Kafka per consumare il tuo primo messaggio.
Il comando kafka-console-consumer accetta molti argomenti passati. Vediamo cosa significa ciascuno di essi:
- Il –topic menziona l’argomento da cui consumerai
- –from-beginning indica al consumatore della console di iniziare a leggere i messaggi fin dal primo messaggio presente
- Il tuo server Apache Kafka è menzionato tramite l’opzione –bootstrap-server
- Inoltre, puoi menzionare il gruppo di consumatori passando il parametro –group
- In assenza di un parametro del gruppo di consumatori, viene generato automaticamente
Con il consumatore della console in esecuzione, puoi provare a produrre nuovi messaggi. Vedrai che vengono consumati tutti e vengono visualizzati nel tuo terminale.
Ora che hai creato il tuo argomento e hai prodotto e consumato correttamente i messaggi, integriamolo con un’applicazione Java.
Come creare Apache Kafka producer e consumer utilizzando Java
Prima di iniziare, assicurati di avere Java 8+ installato sul tuo computer locale. Apache Kafka fornisce la propria libreria client che consente di connettersi senza problemi. Se stai usando Maven per gestire le tue dipendenze, aggiungi la seguente dipendenza al tuo pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Puoi anche scaricare la libreria dal Deposito Maven e aggiungilo al tuo classpath Java.
Una volta che la tua libreria è a posto, apri un editor di codice a tua scelta. Vediamo come puoi avviare il tuo produttore e consumatore utilizzando Java.
Crea un produttore Java Apache Kafka
Con la libreria kafka-clients in atto, sei pronto per iniziare a creare il tuo produttore Kafka.
Creiamo una classe chiamata SimpleProducer.java. Questo sarà responsabile della produzione di messaggi sull’argomento che hai creato in precedenza. All’interno di questa classe, creerai un’istanza di org.apache.kafka.clients.producer.KafkaProducer. Successivamente, utilizzerai questo produttore per inviare i tuoi messaggi.
Per creare il produttore Kafka, sono necessari l’host e la porta del server Apache Kafka. Poiché lo stai eseguendo sul tuo computer locale, l’host sarà localhost. Dato che non hai modificato le proprietà predefinite all’avvio del server, la porta sarà 9092. Considera il seguente codice che ti aiuterà a creare il tuo producer:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Noterai che sono state impostate tre proprietà. Esaminiamo rapidamente ciascuno di essi:
- BOOTSTRAP_SERVERS_CONFIG consente di definire dove è in esecuzione il server Apache Kafka
- KEY_SERIALIZER_CLASS_CONFIG indica al produttore quale formato utilizzare per inviare le chiavi del messaggio.
- Il formato per l’invio del messaggio effettivo viene definito utilizzando la proprietà VALUE_SERIALIZER_CLASS_CONFIG.
Poiché invierai messaggi di testo, entrambe le proprietà sono impostate per utilizzare StringSerializer.class.
Per inviare effettivamente un messaggio al tuo argomento, devi utilizzare il metodo producer.send() che accetta un ProducerRecord. Il codice seguente fornisce un metodo che invierà un messaggio all’argomento e stamperà la risposta insieme all’offset del messaggio.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Con l’intero codice a posto, ora puoi inviare messaggi al tuo argomento. Puoi utilizzare un metodo principale per testarlo, come presentato nel codice seguente:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
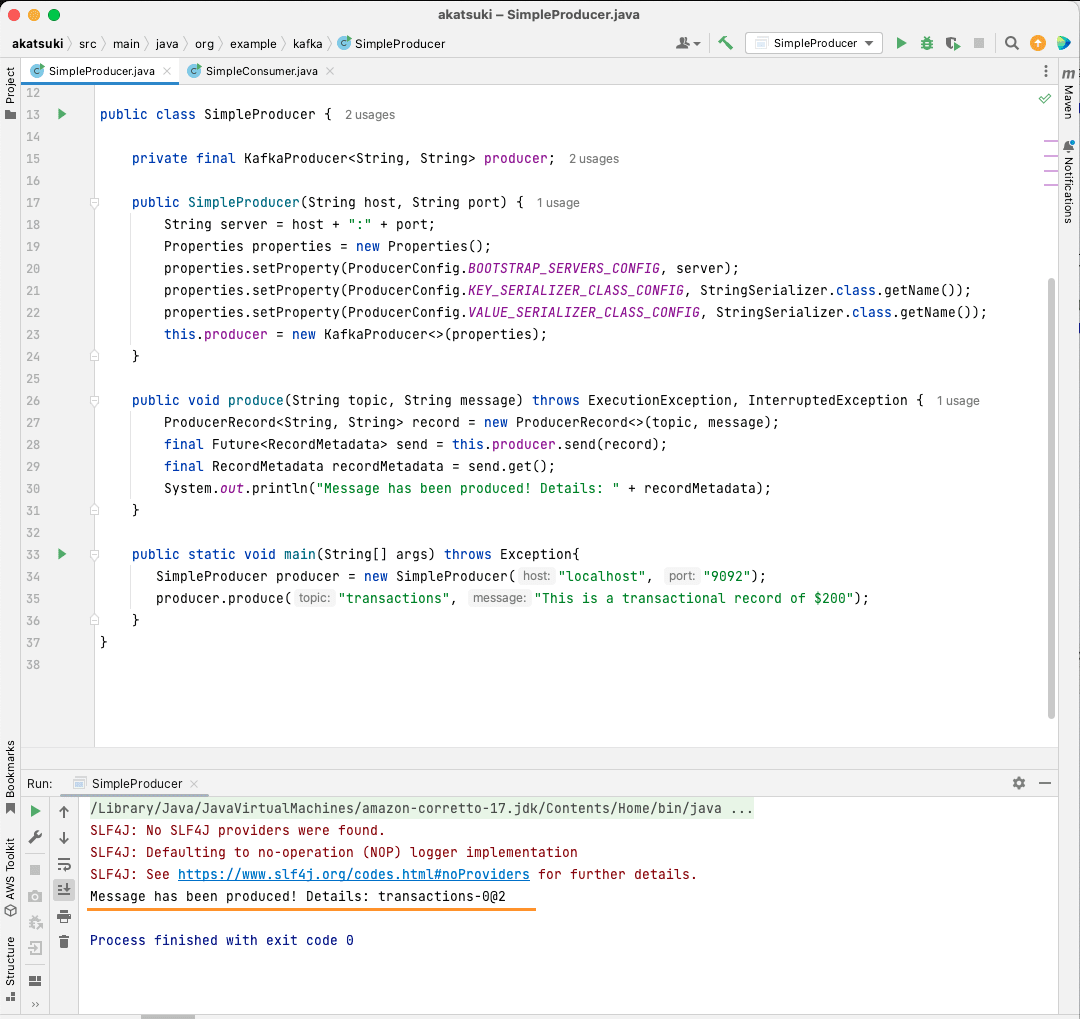
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
In questo codice, stai creando un SimpleProducer che si connette al tuo server Apache Kafka sul tuo computer locale. Utilizza internamente KafkaProducer per produrre messaggi di testo sul tuo argomento.
Creare un consumatore Java Apache Kafka
È ora di creare un consumatore di Apache Kafka utilizzando il client Java. Crea una classe chiamata SimpleConsumer.java. Successivamente, creerai un costruttore per questa classe, che inizializza org.apache.kafka.clients.consumer.KafkaConsumer. Per creare il consumatore, sono necessari l’host e la porta su cui viene eseguito il server Apache Kafka. Inoltre, è necessario il gruppo di consumatori e l’argomento da cui si desidera consumare. Utilizza lo snippet di codice indicato di seguito:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Analogamente a Kafka Producer, anche Kafka Consumer accetta un oggetto Properties. Diamo un’occhiata a tutte le diverse proprietà impostate:
- BOOTSTRAP_SERVERS_CONFIG indica al consumatore dove è in esecuzione il server Apache Kafka
- Il gruppo di consumatori viene menzionato utilizzando GROUP_ID_CONFIG
- Quando il consumatore inizia a consumare, AUTO_OFFSET_RESET_CONFIG ti consente di menzionare da quanto tempo vuoi iniziare a consumare messaggi da
- KEY_DESERIALIZER_CLASS_CONFIG indica al consumatore il tipo di chiave del messaggio
- VALUE_DESERIALIZER_CLASS_CONFIG indica il tipo di consumatore del messaggio effettivo
Poiché, nel tuo caso, consumerai messaggi di testo, le proprietà del deserializzatore sono impostate su StringDeserializer.class.
Ora consumerai i messaggi dal tuo argomento. Per mantenere le cose semplici, una volta consumato il messaggio, stamperai il messaggio sulla console. Vediamo come è possibile ottenere ciò utilizzando il codice seguente:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Questo codice continuerà a interrogare l’argomento. Quando ricevi un record del consumatore, il messaggio verrà stampato. Metti alla prova il tuo consumatore in azione utilizzando un metodo principale. Inizierai un’applicazione Java che continuerà a consumare l’argomento ea stampare i messaggi. Arrestare l’applicazione Java per terminare il consumatore.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Quando esegui il codice, noterai che non solo consuma il messaggio prodotto dal tuo produttore Java, ma anche quelli che hai prodotto tramite il produttore della console. Questo perché la proprietà AUTO_OFFSET_RESET_CONFIG è stata impostata su prima.
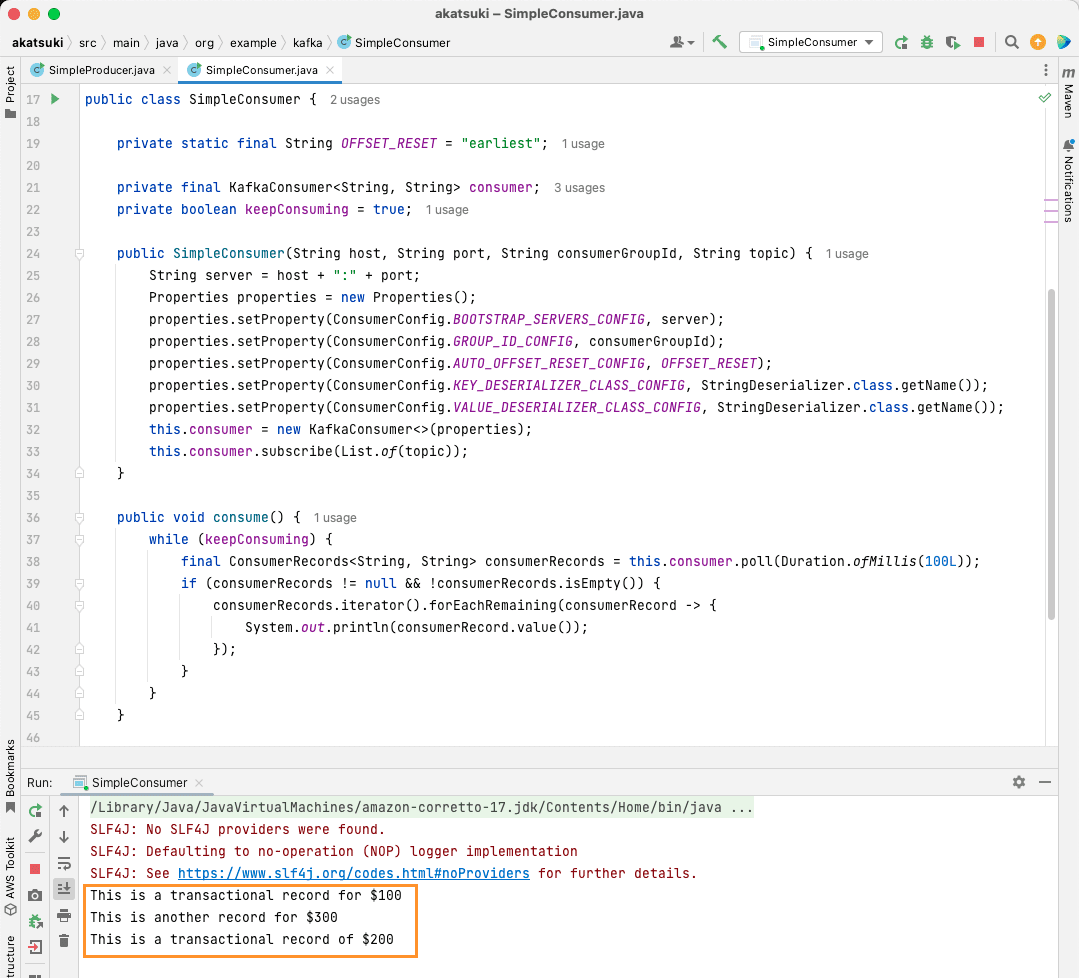
Con SimpleConsumer in esecuzione, è possibile utilizzare il produttore della console o l’applicazione Java SimpleProducer per produrre ulteriori messaggi sull’argomento. Li vedrai consumati e stampati sulla console.
Soddisfa tutte le tue esigenze di pipeline di dati con Apache Kafka
Apache Kafka ti consente di gestire con facilità tutti i requisiti della tua pipeline di dati. Con l’installazione di Apache Kafka sul tuo computer locale, puoi esplorare tutte le diverse funzionalità fornite da Kafka. Inoltre, il client Java ufficiale ti consente di scrivere, connetterti e comunicare in modo efficiente con il tuo server Apache Kafka.
Essendo un sistema di streaming dati versatile, scalabile e altamente performante, Apache Kafka può davvero essere un punto di svolta per te. Puoi usarlo per il tuo sviluppo locale o persino integrarlo nei tuoi sistemi di produzione. Proprio come è facile da configurare localmente, impostare Apache Kafka per applicazioni più grandi non è un compito arduo.
Se stai cercando piattaforme di streaming di dati, puoi guardare le migliori piattaforme di dati di streaming per l’analisi e l’elaborazione in tempo reale.