

MapReduce offre un modo efficace, veloce ed economico per creare applicazioni.
Questo modello utilizza concetti avanzati come l’elaborazione parallela, la località dei dati e così via, per fornire molti vantaggi a programmatori e organizzazioni.
Ma ci sono così tanti modelli e framework di programmazione disponibili sul mercato che diventa difficile scegliere.
E quando si tratta di Big Data, non puoi semplicemente scegliere qualsiasi cosa. È necessario scegliere tali tecnologie in grado di gestire grandi quantità di dati.
MapReduce è un’ottima soluzione a questo.
In questo articolo, parlerò di cos’è veramente MapReduce e di come può essere utile.
Iniziamo!
Sommario:
Che cos’è MapReduce?
MapReduce è un modello di programmazione o framework software all’interno del framework Apache Hadoop. Viene utilizzato per creare applicazioni in grado di elaborare dati di grandi dimensioni in parallelo su migliaia di nodi (chiamati cluster o griglie) con tolleranza di errore e affidabilità.
Questa elaborazione dei dati avviene su un database o un file system in cui sono archiviati i dati. MapReduce può funzionare con un file system Hadoop (HDFS) per accedere e gestire grandi volumi di dati.
Questo framework è stato introdotto nel 2004 da Google ed è reso popolare da Apache Hadoop. È un livello di elaborazione o un motore in Hadoop che esegue programmi MapReduce sviluppati in diversi linguaggi, inclusi Java, C++, Python e Ruby.
I programmi MapReduce nel cloud computing funzionano in parallelo, quindi, adatti per eseguire analisi di dati su larga scala.
MapReduce mira a suddividere un’attività in attività più piccole e multiple utilizzando le funzioni “mappa” e “riduci”. Mapperà ogni attività e quindi la ridurrà a diverse attività equivalenti, il che si tradurrà in una minore potenza di elaborazione e sovraccarico sulla rete del cluster.
Esempio: supponi di preparare un pasto per una casa piena di ospiti. Quindi, se provi a preparare tutti i piatti e fai tutti i processi da solo, diventerà frenetico e richiederà tempo.
Ma supponi di coinvolgere alcuni dei tuoi amici o colleghi (non ospiti) per aiutarti a preparare il pasto distribuendo diversi processi a un’altra persona che può svolgere i compiti contemporaneamente. In tal caso, preparerai il pasto in modo più semplice e veloce mentre i tuoi ospiti sono ancora in casa.
MapReduce funziona in modo simile con le attività distribuite e l’elaborazione parallela per consentire un modo più rapido e semplice per completare una determinata attività.
Apache Hadoop consente ai programmatori di utilizzare MapReduce per eseguire modelli su grandi set di dati distribuiti e utilizzare tecniche avanzate di machine learning e statistiche per trovare modelli, fare previsioni, individuare correlazioni e altro ancora.
Caratteristiche di MapReduce
Alcune delle caratteristiche principali di MapReduce sono:
- Interfaccia utente: otterrai un’interfaccia utente intuitiva che fornisce dettagli ragionevoli su ogni aspetto del framework. Ti aiuterà a configurare, applicare e ottimizzare le tue attività senza problemi.

- Carico utile: le applicazioni utilizzano le interfacce Mapper e Reducer per abilitare la mappa e ridurre le funzioni. Il mappatore associa le coppie chiave-valore di input a coppie chiave-valore intermedie. Riduttore viene utilizzato per ridurre le coppie chiave-valore intermedie che condividono una chiave ad altri valori più piccoli. Svolge tre funzioni: ordinare, mescolare e ridurre.
- Partitioner: Controlla la divisione delle chiavi intermedie di output della mappa.
- Reporter: è una funzione per segnalare lo stato di avanzamento, aggiornare i contatori e impostare messaggi di stato.
- Contatori: rappresenta i contatori globali definiti da un’applicazione MapReduce.
- OutputCollector: questa funzione raccoglie i dati di output da Mapper o Reducer invece di output intermedi.
- RecordWriter: scrive l’output dei dati o le coppie chiave-valore nel file di output.
- DistributedCache: distribuisce in modo efficiente file di sola lettura più grandi che sono specifici dell’applicazione.
- Compressione dei dati: il writer dell’applicazione può comprimere sia gli output del lavoro che gli output delle mappe intermedie.
- Saltare record errati: puoi saltare diversi record errati durante l’elaborazione degli input della mappa. Questa funzione può essere controllata attraverso la classe – SkipBadRecords.
- Debug: avrai la possibilità di eseguire script definiti dall’utente e abilitare il debug. Se un’attività in MapReduce non riesce, puoi eseguire lo script di debug e trovare i problemi.
MapReduce Architecture
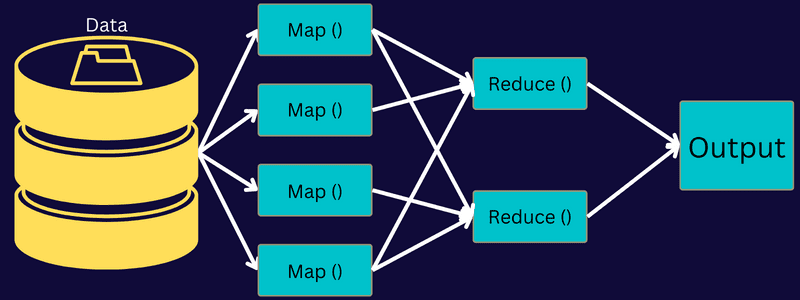
Comprendiamo l’architettura di MapReduce andando più a fondo nei suoi componenti:
- Lavoro: un lavoro in MapReduce è l’attività effettiva che il client MapReduce desidera eseguire. Comprende diversi compiti più piccoli che si combinano per formare il compito finale.
- Job History Server: è un processo daemon per archiviare e salvare tutti i dati storici su un’applicazione o un’attività, come i registri generati dopo o prima dell’esecuzione di un lavoro.
- Client: un client (programma o API) porta un lavoro a MapReduce per l’esecuzione o l’elaborazione. In MapReduce, uno o più client possono inviare continuamente lavori a MapReduce Manager per l’elaborazione.
- MapReduce Master: un MapReduce Master divide un lavoro in diverse parti più piccole, assicurando che le attività procedano contemporaneamente.
- Parti del lavoro: i lavori secondari o le parti del lavoro si ottengono dividendo il lavoro principale. Vengono elaborati e infine combinati per creare l’attività finale.
- Dati di input: è il set di dati fornito a MapReduce per l’elaborazione delle attività.
- Dati di output: è il risultato finale ottenuto una volta che l’attività è stata elaborata.
Quindi, ciò che accade realmente in questa architettura è che il client invia un lavoro al MapReduce Master, che lo divide in parti più piccole e uguali. Ciò consente di elaborare il lavoro più velocemente poiché le attività più piccole richiedono meno tempo per essere elaborate anziché le attività più grandi.
Tuttavia, assicurati che le attività non siano divise in attività troppo piccole, perché se lo fai, potresti dover affrontare un sovraccarico maggiore nella gestione delle divisioni e perdere molto tempo su questo.
Successivamente, le parti del lavoro vengono rese disponibili per procedere con le attività Mappa e Riduci. Inoltre, le attività Mappa e Riduci hanno un programma adatto basato sul caso d’uso su cui sta lavorando il team. Il programmatore sviluppa il codice basato sulla logica per soddisfare i requisiti.
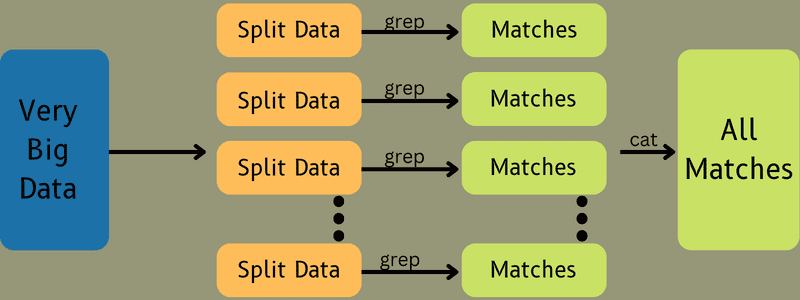
Successivamente, i dati di input vengono inviati all’attività della mappa in modo che la mappa possa generare rapidamente l’output come coppia chiave-valore. Invece di archiviare questi dati su HDFS, viene utilizzato un disco locale per archiviare i dati per eliminare la possibilità di replica.
Una volta completata l’attività, è possibile eliminare l’output. Quindi, la replica diventerà un eccesso quando memorizzerai l’output su HDFS. L’output di ciascuna attività della mappa verrà inviato all’attività di riduzione e l’output della mappa verrà fornito alla macchina che esegue l’attività di riduzione.
Successivamente, l’output verrà unito e passato alla funzione di riduzione definita dall’utente. Infine, l’output ridotto verrà archiviato su un HDFS.
Inoltre, il processo può avere diverse attività Mappa e Riduci per l’elaborazione dei dati a seconda dell’obiettivo finale. Gli algoritmi Mappa e Riduci sono ottimizzati per mantenere la complessità temporale o spaziale minima.
Poiché MapReduce coinvolge principalmente le attività Mappa e Riduci, è pertinente capirne di più. Quindi, discutiamo le fasi di MapReduce per avere un’idea chiara di questi argomenti.
Fasi di MapReduce
Carta geografica
I dati di input vengono mappati nell’output o nelle coppie chiave-valore in questa fase. Qui, la chiave può fare riferimento all’id di un indirizzo mentre il valore può essere il valore effettivo di quell’indirizzo.
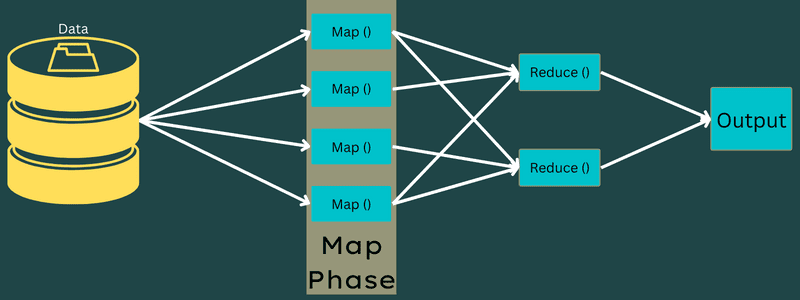
Ci sono solo una ma due attività in questa fase: suddivisioni e mappatura. Divisioni indica le sottoparti o le parti del lavoro divise dal lavoro principale. Questi sono anche chiamati suddivisioni di input. Quindi, una divisione di input può essere chiamata un blocco di input consumato da una mappa.
Successivamente, viene eseguita l’attività di mappatura. È considerata la prima fase durante l’esecuzione di un programma di riduzione della mappa. Qui, i dati contenuti in ogni suddivisione verranno passati a una funzione di mappa per elaborare e generare l’output.
La funzione – Map() viene eseguita nel repository di memoria sulle coppie chiave-valore di input, generando una coppia chiave-valore intermedia. Questa nuova coppia chiave-valore funzionerà come input da inviare alla funzione Reduce() o Reducer.
Ridurre
Le coppie chiave-valore intermedie ottenute nella fase di mappatura funzionano come input per la funzione Riduci o Riduttore. Simile alla fase di mappatura, sono coinvolte due attività: mescolare e ridurre.
Quindi, le coppie chiave-valore ottenute vengono ordinate e mescolate per essere inviate al riduttore. Successivamente, il riduttore raggruppa o aggrega i dati in base alla sua coppia chiave-valore in base all’algoritmo del riduttore che lo sviluppatore ha scritto.
Qui, i valori della fase di mescolamento vengono combinati per restituire un valore di uscita. Questa fase riassume l’intero set di dati.
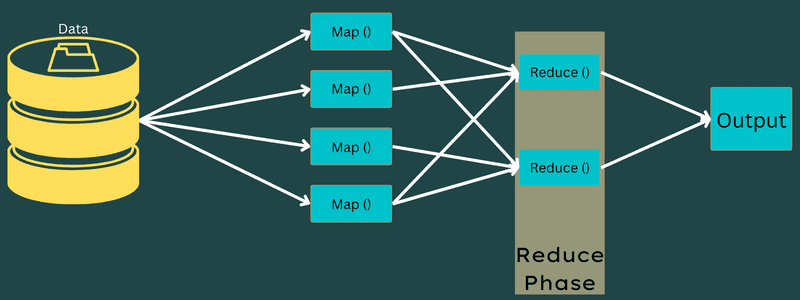
Ora, il processo completo di esecuzione delle attività Mappa e Riduci è controllato da alcune entità. Questi sono:
- Job Tracker: in parole semplici, un job tracker agisce come un master che è responsabile dell’esecuzione completa di un lavoro inviato. Il job tracker gestisce tutti i lavori e le risorse in un cluster. Inoltre, il job tracker pianifica ogni mappa aggiunta al task tracker che viene eseguita su un nodo dati specifico.
- Più task tracker: in parole semplici, più task tracker funzionano come slave eseguendo l’attività seguendo le istruzioni del Job Tracker. Un task tracker viene distribuito su ogni nodo separatamente nel cluster che esegue le attività Mappa e Riduci.
Funziona perché un lavoro sarà suddiviso in più attività che verranno eseguite su nodi di dati diversi da un cluster. Il Job Tracker è responsabile del coordinamento dell’attività pianificando le attività ed eseguendole su più nodi di dati. Successivamente, il Task Tracker presente su ciascun nodo di dati esegue parti del lavoro e si occupa di ogni attività.
Inoltre, i Task Tracker inviano rapporti sullo stato di avanzamento al job tracker. Inoltre, il Task Tracker invia periodicamente un segnale di “heartbeat” al Job Tracker e lo informa dello stato del sistema. In caso di errore, un job tracker è in grado di riprogrammare il lavoro su un altro task tracker.
Fase di output: quando raggiungi questa fase, avrai le coppie chiave-valore finali generate dal riduttore. È possibile utilizzare un formattatore di output per tradurre le coppie chiave-valore e scriverle in un file con l’aiuto di uno scrittore di record.
Perché usare MapReduce?
Ecco alcuni dei vantaggi di MapReduce, spiegando i motivi per cui è necessario utilizzarlo nelle applicazioni Big Data:
Elaborazione parallela
È possibile dividere un lavoro in diversi nodi in cui ogni nodo gestisce contemporaneamente una parte di questo lavoro in MapReduce. Quindi, dividere compiti più grandi in compiti più piccoli diminuisce la complessità. Inoltre, poiché attività diverse vengono eseguite in parallelo su macchine diverse anziché su una singola macchina, l’elaborazione dei dati richiede molto meno tempo.
Località dati
In MapReduce, puoi spostare l’unità di elaborazione sui dati, non viceversa.
Con modalità tradizionali, i dati sono stati portati all’unità di elaborazione per l’elaborazione. Tuttavia, con la rapida crescita dei dati, questo processo ha iniziato a porre molte sfide. Alcuni di essi erano più costosi, più dispendiosi in termini di tempo, oneri per il nodo master, guasti frequenti e prestazioni di rete ridotte.
Ma MapReduce aiuta a superare questi problemi seguendo un approccio inverso, portando un’unità di elaborazione ai dati. In questo modo, i dati vengono distribuiti tra diversi nodi in cui ogni nodo può elaborare una parte dei dati archiviati.
Di conseguenza, offre convenienza e riduce i tempi di elaborazione poiché ogni nodo lavora in parallelo con la sua parte di dati corrispondente. Inoltre, poiché ogni nodo elabora una parte di questi dati, nessun nodo verrà sovraccaricato.
Sicurezza

Il modello MapReduce offre una maggiore sicurezza. Aiuta a proteggere la tua applicazione da dati non autorizzati migliorando la sicurezza del cluster.
Scalabilità e flessibilità
MapReduce è un framework altamente scalabile. Ti consente di eseguire applicazioni da più macchine, utilizzando dati con migliaia di terabyte. Offre inoltre la flessibilità di elaborare dati che possono essere strutturati, semistrutturati o non strutturati e di qualsiasi formato o dimensione.
Semplicità
Puoi scrivere programmi MapReduce in qualsiasi linguaggio di programmazione come Java, R, Perl, Python e altri. Pertanto, è facile per chiunque imparare e scrivere programmi assicurandosi che i propri requisiti di elaborazione dei dati siano soddisfatti.
Casi d’uso di MapReduce
- Indicizzazione full-text: MapReduce viene utilizzato per eseguire l’indicizzazione full-text. Il suo Mapper può mappare ogni parola o frase in un singolo documento. E il riduttore viene utilizzato per scrivere tutti gli elementi mappati in un indice.
- Calcolo del Pagerank: Google utilizza MapReduce per il calcolo del Pagerank.
- Analisi del registro: MapReduce può analizzare i file di registro. Può suddividere un file di registro di grandi dimensioni in varie parti o dividerlo mentre il mappatore cerca le pagine Web a cui si accede.
Una coppia chiave-valore verrà inviata al riduttore se una pagina Web viene individuata nel registro. Qui, la pagina web sarà la chiave e l’indice “1” è il valore. Dopo aver distribuito una coppia chiave-valore al riduttore, varie pagine web verranno aggregate. L’output finale è il numero complessivo di hit per ciascuna pagina web.

- Reverse Web-Link Graph: il framework trova utilizzo anche nel Reverse Web-Link Graph. Qui, Map() restituisce l’URL di destinazione e l’origine e riceve l’input dall’origine o dalla pagina Web.
Successivamente, Reduce() aggrega l’elenco di ciascun URL di origine associato all’URL di destinazione. Infine, emette le sorgenti e la destinazione.
- Conteggio parole: MapReduce viene utilizzato per contare quante volte una parola appare in un determinato documento.
- Riscaldamento globale: organizzazioni, governi e aziende possono utilizzare MapReduce per risolvere i problemi del riscaldamento globale.
Ad esempio, potresti voler conoscere l’aumento del livello di temperatura dell’oceano a causa del riscaldamento globale. Per questo, puoi raccogliere migliaia di dati in tutto il mondo. I dati possono essere alta temperatura, bassa temperatura, latitudine, longitudine, data, ora, ecc. Ciò richiederà diverse mappe e ridurrà le attività per calcolare l’output utilizzando MapReduce.
- Sperimentazione farmacologica: tradizionalmente, data scientist e matematici hanno lavorato insieme per formulare un nuovo farmaco in grado di combattere una malattia. Con la diffusione di algoritmi e MapReduce, i dipartimenti IT delle organizzazioni possono facilmente affrontare problemi che sono stati gestiti solo da Supercomputer, Ph.D. scienziati, ecc. Ora puoi controllare l’efficacia di un farmaco per un gruppo di pazienti.
- Altre applicazioni: MapReduce può elaborare anche dati su larga scala che altrimenti non rientrerebbero in un database relazionale. Utilizza anche strumenti di data science e consente di eseguirli su set di dati diversi e distribuiti, cosa che in precedenza era possibile solo su un singolo computer.
Come risultato della robustezza e semplicità di MapReduce, trova applicazioni in campo militare, commerciale, scientifico, ecc.
Conclusione
MapReduce può rivelarsi una svolta tecnologica. Non è solo un processo più rapido e semplice, ma anche economico e che richiede meno tempo. Dati i suoi vantaggi e il crescente utilizzo, è probabile che assista a una maggiore adozione in tutti i settori e le organizzazioni.
Puoi anche esplorare alcune delle migliori risorse per imparare Big Data e Hadoop.