
Ebbene, le statistiche di Forbes affermano che fino al 90% delle organizzazioni mondiali utilizza l’analisi dei Big Data per creare i propri rapporti sugli investimenti.
Con la crescente popolarità dei Big Data, c’è di conseguenza un aumento delle opportunità di lavoro Hadoop più di prima.
Pertanto, per aiutarti a ottenere quel ruolo di esperto di Hadoop, puoi utilizzare queste domande e risposte del colloquio che abbiamo raccolto per te in questo articolo per aiutarti a superare il colloquio.
Forse conoscere fatti come la fascia salariale che rende redditizi i ruoli di Hadoop e Big Data ti motiverà a superare quel colloquio, giusto? 🤔
- Secondo Indeed.com, uno sviluppatore di Big Data Hadoop con sede negli Stati Uniti guadagna uno stipendio medio di $ 144.000.
- Secondo itjobswatch.co.uk, lo stipendio medio di uno sviluppatore di Big Data Hadoop è di £ 66.750.
- In India, la fonte di Indeed.com afferma che guadagnerebbero uno stipendio medio di ₹ 16,00,000.
Lucrativo, non credi? Ora, entriamo per conoscere Hadoop.
Sommario:
Cos’è Hadoop?
Hadoop è un framework popolare scritto in Java che utilizza modelli di programmazione per elaborare, archiviare e analizzare grandi set di dati.
Per impostazione predefinita, il suo design consente il ridimensionamento da singoli server a più macchine che offrono elaborazione e archiviazione locali. Inoltre, la sua capacità di rilevare e gestire i guasti a livello di applicazione che si traducono in servizi altamente disponibili rende Hadoop abbastanza affidabile.
Passiamo subito alle domande più frequenti dell’intervista Hadoop e alle loro risposte corrette.
Domande e risposte dell’intervista di Hadoop
Cos’è l’unità di archiviazione in Hadoop?
Risposta: L’unità di archiviazione di Hadoop si chiama Hadoop Distributed File System (HDFS).
In che modo lo storage collegato alla rete è diverso dal file system distribuito Hadoop?
Risposta: HDFS, che è l’archiviazione principale di Hadoop, è un file system distribuito che archivia file di grandi dimensioni utilizzando hardware di base. D’altra parte, il NAS è un server di archiviazione dei dati del computer a livello di file che fornisce a gruppi di client eterogenei l’accesso ai dati.
Mentre l’archiviazione dei dati nel NAS avviene su hardware dedicato, HDFS distribuisce i blocchi di dati su tutte le macchine all’interno del cluster Hadoop.
Il NAS utilizza dispositivi di archiviazione di fascia alta, il che è piuttosto costoso, mentre l’hardware di base utilizzato in HDFS è conveniente.
Il NAS archivia separatamente i dati dai calcoli rendendolo quindi inadatto per MapReduce. Al contrario, il design di HDFS gli consente di funzionare con il framework MapReduce. I calcoli si spostano nei dati nel framework MapReduce anziché i dati nei calcoli.
Spiegare MapReduce in Hadoop e Shuffling
Risposta: MapReduce fa riferimento a due attività distinte eseguite dai programmi Hadoop per consentire un’ampia scalabilità su centinaia o migliaia di server all’interno di un cluster Hadoop. Lo shuffling, d’altra parte, trasferisce l’output della mappa dai Mapper al necessario Reducer in MapReduce.
Dai uno sguardo all’architettura di Apache Pig
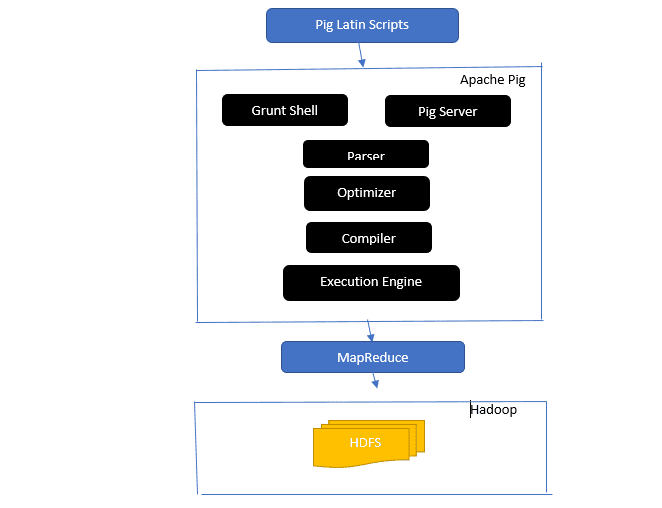 L’architettura Apache Pig
L’architettura Apache Pig
Risposta: l’architettura Apache Pig dispone di un interprete Pig Latin che elabora e analizza set di dati di grandi dimensioni utilizzando gli script Pig Latin.
Apache pig è costituito anche da set di set di dati su cui vengono eseguite operazioni sui dati come join, load, filter, sort e group.
Il linguaggio Pig Latin utilizza meccanismi di esecuzione come shell Grant, UDF e incorporati per scrivere script Pig che eseguono le attività richieste.
Pig semplifica il lavoro dei programmatori convertendo questi script scritti in serie di lavori Map-Reduce.
I componenti dell’architettura Apache Pig includono:
- Parser: gestisce gli script Pig controllando la sintassi dello script ed eseguendo il controllo del tipo. L’output del parser rappresenta le dichiarazioni e gli operatori logici di Pig Latin ed è chiamato DAG (grafico aciclico diretto).
- Ottimizzatore: l’ottimizzatore implementa ottimizzazioni logiche come la proiezione e il pushdown sul DAG.
- Compilatore: compila il piano logico ottimizzato dall’ottimizzatore in una serie di lavori MapReduce.
- Execution Engine: è qui che si verifica l’esecuzione finale dei lavori MapReduce nell’output desiderato.
- Modalità di esecuzione: le modalità di esecuzione in Apache pig includono principalmente local e Map Reduce.
Risposta: il servizio Metastore in Local Metastore viene eseguito nella stessa JVM di Hive ma si connette a un database in esecuzione in un processo separato sullo stesso computer o su un computer remoto. D’altra parte, Metastore nel Metastore remoto viene eseguito nella sua JVM separata dalla JVM del servizio Hive.
Quali sono le Cinque V dei Big Data?
Risposta: Queste cinque V rappresentano le principali caratteristiche dei Big Data. Loro includono:
- Valore: i big data cercano di fornire vantaggi significativi dall’elevato ritorno sull’investimento (ROI) a un’organizzazione che utilizza i big data nelle sue operazioni sui dati. I big data apportano questo valore dalla scoperta di insight e dal riconoscimento di modelli, che si traducono in relazioni con i clienti più solide e operazioni più efficaci, tra gli altri vantaggi.
- Varietà: rappresenta l’eterogeneità del tipo di tipi di dati raccolti. I vari formati includono CSV, video, audio, ecc.
- Volume: definisce la quantità significativa e la dimensione dei dati gestiti e analizzati da un’organizzazione. Questi dati rappresentano una crescita esponenziale.
- Velocità: questa è la velocità esponenziale per la crescita dei dati.
- Veridicità: la veridicità si riferisce al modo in cui i dati disponibili “incerti” o “imprecisi” sono dovuti a dati incompleti o incoerenti.
Spiega i diversi tipi di dati del maiale latino.
Risposta: I tipi di dati in Pig Latin includono tipi di dati atomici e tipi di dati complessi.
I tipi di dati atomici sono i tipi di dati di base utilizzati in ogni altra lingua. Includono quanto segue:
- Int: questo tipo di dati definisce un intero con segno a 32 bit. Esempio: 13
- Long: Long definisce un numero intero a 64 bit. Esempio: 10L
- Float: definisce una virgola mobile a 32 bit con segno. Esempio: 2,5 F
- Double: definisce una virgola mobile a 64 bit con segno. Esempio: 23.4
- Booleano: definisce un valore booleano. Include: vero/falso
- Datetime: definisce un valore data-ora. Esempio: 1980-01-01T00:00.00.000+00:00
I tipi di dati complessi includono:
- Map-Map si riferisce a un insieme di coppie chiave-valore. Esempio: [‘color’#’yellow’, ‘number’#3]
- Bag: è una raccolta di un insieme di tuple e utilizza il simbolo ‘{}’. Esempio: {(Henry, 32), (Kiti, 47)}
- Tupla: una tupla definisce un insieme ordinato di campi. Esempio: (Età, 33)
Cosa sono Apache Oozie e Apache ZooKeeper?
Risposta: Apache Oozie è uno scheduler Hadoop incaricato di pianificare e associare insieme i job Hadoop come un unico lavoro logico.
Apache Zookeeper, invece, si coordina con vari servizi in un ambiente distribuito. Fa risparmiare tempo agli sviluppatori esponendo semplicemente servizi semplici come sincronizzazione, raggruppamento, manutenzione della configurazione e denominazione. Apache Zookeeper fornisce anche supporto standard per l’accodamento e l’elezione del leader.
Qual è il ruolo di Combiner, RecordReader e Partitioner in un’operazione MapReduce?
Risposta: Il combinatore funziona come un mini riduttore. Riceve e lavora sui dati dalle attività della mappa e quindi passa l’output dei dati alla fase di riduzione.
Il RecordHeader comunica con l’InputSplit e converte i dati in coppie chiave-valore affinché il mapper possa leggerli adeguatamente.
Il partizionatore è responsabile di decidere il numero di attività ridotte necessarie per riepilogare i dati e confermare come gli output del combinatore vengono inviati al riduttore. Partitioner controlla anche il partizionamento delle chiavi degli output della mappa intermedia.
Menzione di diverse distribuzioni specifiche del fornitore di Hadoop.
Risposta: I vari fornitori che estendono le funzionalità di Hadoop includono:
- Piattaforma aperta IBM.
- Distribuzione Cloudera CDH Hadoop
- Distribuzione MapR Hadoop
- Amazon Elastic MapReduce
- Piattaforma dati Hortonworks (HDP)
- Suite fondamentale per i Big Data
- Datastax Enterprise Analytics
- HDInsight di Microsoft Azure: distribuzione Hadoop basata su cloud.
Perché HDFS è tollerante ai guasti?
Risposta: HDFS replica i dati su diversi DataNode, rendendolo tollerante ai guasti. L’archiviazione dei dati in nodi diversi consente il recupero da altri nodi quando una modalità si arresta in modo anomalo.
Differenza tra una federazione e l’alta disponibilità.
Risposta: la federazione HDFS offre tolleranza ai guasti che consente un flusso continuo di dati in un nodo quando un altro si arresta in modo anomalo. D’altra parte, l’alta disponibilità richiederà due macchine separate che configurano separatamente il NameNode attivo e il NameNode secondario sulla prima e sulla seconda macchina.
La federazione può avere un numero illimitato di NameNode non correlati, mentre in Alta disponibilità sono disponibili solo due NameNode correlati, attivo e in standby, che funzionano in modo continuo.
I NameNode nella federazione condividono un pool di metadati, con ciascun NameNode che ha il proprio pool dedicato. In High Availability, tuttavia, i NameNode attivi vengono eseguiti uno alla volta mentre i NameNode in standby rimangono inattivi e aggiornano i propri metadati solo occasionalmente.
Come trovare lo stato dei blocchi e l’integrità del file system?
Risposta: si utilizza il comando hdfs fsck / sia a livello di utente root sia in una singola directory per verificare lo stato di integrità del file system HDFS.
Comando HDFS fsck in uso:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
La descrizione del comando:
- -files: Stampa i file che stai controllando.
- –locations: stampa le posizioni di tutti i blocchi durante il controllo.
Comando per verificare lo stato dei blocchi:
hdfs fsck <path> -files -blocks
: inizia i controlli dal percorso passato qui. - – blocchi: stampa i blocchi del file durante il controllo
Quando usi i comandi rmadmin-refreshNodes e dfsadmin-refreshNodes?
Risposta: Questi due comandi sono utili per aggiornare le informazioni sul nodo durante la messa in servizio o quando la messa in servizio del nodo è stata completata.
Il comando dfsadmin-refreshNodes esegue il client HDFS e aggiorna la configurazione del nodo di NameNode. Il comando rmadmin-refreshNodes, dall’altro, esegue le attività amministrative di ResourceManager.
Che cos’è un punto di controllo?
Risposta: Checkpoint è un’operazione che unisce le ultime modifiche del file system con l’immagine FSImage più recente in modo che i file di registro delle modifiche rimangano abbastanza piccoli da velocizzare il processo di avvio di un NameNode. Il punto di controllo si verifica nel NameNode secondario.
Perché utilizziamo HDFS per applicazioni con set di dati di grandi dimensioni?
Risposta: HDFS fornisce un’architettura DataNode e NameNode che implementa un file system distribuito.
Queste due architetture forniscono un accesso ad alte prestazioni ai dati su cluster altamente scalabili di Hadoop. Il suo NameNode memorizza i metadati del file system nella RAM, il che si traduce nella quantità di memoria che limita il numero di file del file system HDFS.
Cosa fa il comando ‘jps’?
Risposta: il comando JPS (Java Virtual Machine Process Status) controlla se specifici daemon Hadoop, inclusi NodeManager, DataNode, NameNode e ResourceManager, sono in esecuzione o meno. Questo comando deve essere eseguito dalla radice per controllare i nodi operativi nell’Host.
Che cos’è l'”esecuzione speculativa” in Hadoop?
Risposta: questo è un processo in cui il nodo master in Hadoop, invece di correggere le attività lente rilevate, avvia un’istanza diversa della stessa attività come attività di backup (attività speculativa) su un altro nodo. L’esecuzione speculativa consente di risparmiare molto tempo, soprattutto in un ambiente con carichi di lavoro intensivi.
Nomina le tre modalità in cui Hadoop può funzionare.
Risposta: I tre nodi primari su cui viene eseguito Hadoop includono:
- Il nodo autonomo è la modalità predefinita che esegue i servizi Hadoop utilizzando il file system locale e un singolo processo Java.
- Il nodo pseudo-distribuito esegue tutti i servizi Hadoop utilizzando una singola distribuzione Hadoop ode.
- Il nodo completamente distribuito esegue i servizi Hadoop master e slave utilizzando nodi separati.
Cos’è un UDF?
Risposta: UDF (Funzioni definite dall’utente) consente di codificare le funzioni personalizzate che è possibile utilizzare per elaborare i valori delle colonne durante una query Impala.
Cos’è DistCP?
Risposta: DistCp o Distributed Copy, in breve, è uno strumento utile per la copia di dati all’interno o all’interno di cluster di grandi dimensioni. Utilizzando MapReduce, DistCp implementa in modo efficace la copia distribuita di una grande quantità di dati, oltre ad altre attività come la gestione degli errori, il ripristino e la creazione di report.
Risposta: Hive metastore è un servizio che memorizza i metadati Apache Hive per le tabelle Hive in un database relazionale come MySQL. Fornisce l’API del servizio metastore che consente l’accesso centesimo ai metadati.
Definisci RDD.
Risposta: RDD, che sta per Resilient Distributed Datasets, è la struttura dei dati di Spark e una raccolta distribuita immutabile dei tuoi elementi di dati che calcola sui diversi nodi del cluster.
In che modo le librerie native possono essere incluse nei lavori YARN?
Risposta: puoi implementarlo usando -Djava.library. path sul comando o impostando LD+LIBRARY_PATH nel file .bashrc utilizzando il seguente formato:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Spiegare ‘WAL’ in HBase.
Risposta: Il Write Ahead Log (WAL) è un protocollo di ripristino che registra le modifiche ai dati di MemStore in HBase nell’archiviazione basata su file. WAL recupera questi dati se il RegionalServer si arresta in modo anomalo o prima di svuotare il MemStore.
YARN è un sostituto di Hadoop MapReduce?
Risposta: No, YARN non è un sostituto di Hadoop MapReduce. Invece, una potente tecnologia chiamata Hadoop 2.0 o MapReduce 2 supporta MapReduce.
Qual è la differenza tra ORDER BY e SORT BY in HIVE?
Risposta: sebbene entrambi i comandi recuperino i dati in modo ordinato in Hive, i risultati derivanti dall’utilizzo di SORT BY possono essere ordinati solo parzialmente.
Inoltre, SORT BY richiede un riduttore per ordinare le righe. Questi riduttori richiesti per l’output finale possono anche essere multipli. In questo caso, l’output finale può essere parzialmente ordinato.
D’altra parte, ORDER BY richiede solo un riduttore per un ordine totale in uscita. Puoi anche utilizzare la parola chiave LIMIT che riduce il tempo totale di ordinamento.
Qual è la differenza tra Spark e Hadoop?
Risposta: Sebbene sia Hadoop che Spark siano framework di elaborazione distribuita, la loro differenza fondamentale è la loro elaborazione. Laddove Hadoop è efficiente per l’elaborazione in batch, Spark è efficiente per l’elaborazione dei dati in tempo reale.
Inoltre, Hadoop legge e scrive principalmente file su HDFS, mentre Spark utilizza il concetto di set di dati distribuiti resilienti per elaborare i dati nella RAM.
In base alla loro latenza, Hadoop è un framework di elaborazione ad alta latenza senza una modalità interattiva per elaborare i dati, mentre Spark è un framework di elaborazione a bassa latenza che elabora i dati in modo interattivo.
Confronta Sqoop e Flume.
Risposta: Sqoop e Flume sono strumenti Hadoop che raccolgono dati raccolti da varie fonti e li caricano in HDFS.
- Sqoop (SQL-to-Hadoop) estrae dati strutturati da database, inclusi Teradata, MySQL, Oracle, ecc., mentre Flume è utile per estrarre dati non strutturati da fonti di database e caricarli in HDFS.
- In termini di eventi guidati, Flume è guidato dagli eventi, mentre Sqoop non è guidato dagli eventi.
- Sqoop utilizza un’architettura basata su connettori in cui i connettori sanno come connettersi a un’origine dati diversa. Flume utilizza un’architettura basata su agenti, con il codice scritto che è l’agente incaricato di recuperare i dati.
- A causa della natura distribuita di Flume, può facilmente raccogliere e aggregare i dati. Sqoop è utile per il trasferimento di dati in parallelo, che comporta l’output in più file.
Spiega il BloomMapFile.
Risposta: BloomMapFile è una classe che estende la classe MapFile e utilizza filtri bloom dinamici che forniscono un rapido test di appartenenza per le chiavi.
Elenca la differenza tra HiveQL e PigLatin.
Risposta: mentre HiveQL è un linguaggio dichiarativo simile a SQL, PigLatin è un linguaggio di flusso di dati procedurale di alto livello.
Cos’è la pulizia dei dati?
Risposta: la pulizia dei dati è un processo cruciale per eliminare o correggere errori di dati identificati che includono dati errati, incompleti, corrotti, duplicati e formattati in modo errato all’interno di un set di dati.
Questo processo mira a migliorare la qualità dei dati e fornire informazioni più accurate, coerenti e affidabili necessarie per un processo decisionale efficiente all’interno di un’organizzazione.
Conclusione💃
Con l’attuale aumento delle opportunità di lavoro di Big Data e Hadoop, potresti voler migliorare le tue possibilità di entrare. Le domande e le risposte dell’intervista Hadoop di questo articolo ti aiuteranno a superare l’imminente intervista.
Successivamente, puoi controllare buone risorse per imparare Big Data e Hadoop.
Buona fortuna! 👍