
L’acquisizione dei dati è una parte cruciale di un processo incentrato sui dati, poiché garantisce che le organizzazioni ricevano le informazioni giuste al momento giusto per comprendere le prestazioni aziendali e migliorarle.
Le organizzazioni moderne generano ogni giorno enormi quantità di dati di grande valore per le loro attività.
Eseguendo l’analisi aziendale, le organizzazioni possono ottenere informazioni più approfondite, che le aiutano a prendere decisioni informate e basate sui dati.
Questi dati svolgono anche un ruolo chiave nella comprensione dei clienti, nella previsione del mercato, nella pianificazione, nella previsione delle tendenze e nell’ottenimento di altri vantaggi.
Tuttavia, per eseguire determinate attività, è fondamentale estrarre e analizzare i dati e accedervi facilmente da una posizione centralizzata.
È qui che entra in gioco l’acquisizione dei dati.
Questa tecnica estrae i dati da diverse fonti, consentendoti di scoprire informazioni nascoste al loro interno e di utilizzarli ulteriormente per far crescere la tua attività.
In questo articolo parlerò dell’inserimento dei dati e dei relativi tipi, del processo passo passo, dell’architettura, dei casi d’uso, dei vantaggi, delle best practice e delle sfide.
Eccoci qui!
Sommario:
Cos’è l’inserimento dei dati?
L’inserimento dei dati è il processo di raccolta dei dati da una o più origini e di importazione in un data warehouse per un utilizzo immediato. È uno dei passaggi più essenziali nel flusso di lavoro di analisi dei dati.

I dati possono essere acquisiti in batch o trasmessi in streaming in tempo reale. Quando i dati vengono spostati nel sito di destinazione, vengono archiviati correttamente e quindi utilizzati per l’analisi.
Le origini dati potrebbero essere data lake, database, dispositivi IoT, applicazioni SaaS, database locali e altre piattaforme che potrebbero contenere dati rilevanti ed essenziali.
L’inserimento dei dati è un processo semplice che prende i dati da un’origine, li pulisce e li inoltra a una destinazione dove un’azienda può utilizzare, accedere e analizzare i dati.
L’acquisizione dei dati consente alle organizzazioni di prendere decisioni basate sui dati a partire dalla crescente complessità e dal volume di dati che producono ogni giorno.
Quando un’organizzazione raccoglie dati, questi rimangono nel loro stato originale e grezzo, lo stesso dell’origine. Sarà necessario eseguire un’operazione di trasformazione quando è necessario trasformare o analizzare i dati in un formato leggibile compatibile con diverse applicazioni.
L’obiettivo principale dell’acquisizione dei dati è spostare un ampio insieme di dati da un luogo a un altro in modo efficiente con l’aiuto dell’automazione del software. Si limita ad acquisire i dati, non a trasformarli. Per molte organizzazioni, funziona come uno strumento fondamentale che consente loro di gestire il front-end dei dati.
Esistono diversi modi per inserire i dati nel data mart. In base alle tue esigenze particolari e ai requisiti di progettazione, puoi scegliere il metodo di importazione più adatto alle tue esigenze.
Come funziona l’acquisizione dei dati?
L’inserimento dei dati raccoglie dati da più origini in cui i dati sono stati originariamente archiviati o generati. Carica o trasferisce i dati alla destinazione o all’area di staging. La pipeline di inserimento dati applica trasformazioni leggere ovunque sia necessario per filtrare o ottimizzare i dati prima di inviarli a una coda di messaggi, a un archivio dati o a una destinazione.
L’acquisizione dei dati esegue anche trasformazioni complesse, tra cui ordinamenti, unioni e aggregazioni per applicazioni specifiche, reporting e sistemi di analisi con pipeline supplementari.
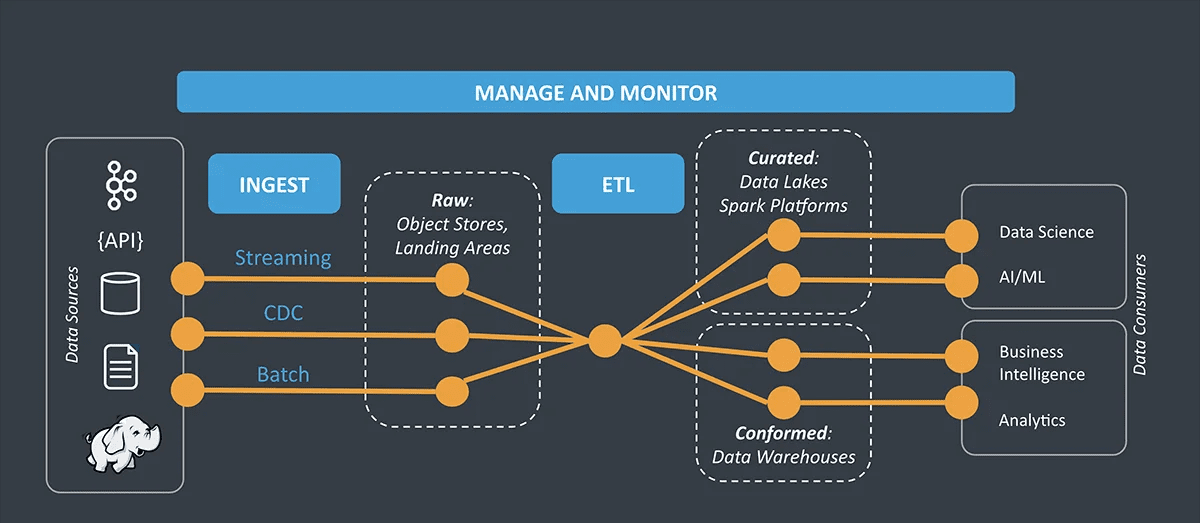
Per comprendere il processo passo passo di acquisizione dei dati, è necessario immergersi nella sua architettura.
 Fonte: StreamSet
Fonte: StreamSet
Architettura dell’inserimento dei dati
L’architettura dell’acquisizione dei dati indica il flusso dei dati nei seguenti livelli:
- Livello di raccolta dati: raccoglie dati da diverse fonti e li archivia nel tuo data warehouse. Questo livello definisce il modo in cui i dati vengono trasferiti o analizzati ad altri livelli dell’architettura di acquisizione. Inoltre, aiuta a scomporre i dati per l’elaborazione analitica.
- Livello di elaborazione dati: questo livello raccoglie i dati dal livello precedente per elaborare il trasferimento dei dati archiviati. Definisce la destinazione a cui si desidera inviare i dati e li raggruppa di conseguenza.
- Livello di archiviazione dei dati: i dati, una volta raggruppati, vengono archiviati in una posizione efficiente per ulteriori trasferimenti.
- Livello di query dei dati: questo è il livello analitico dell’architettura di inserimento dei dati. Qui, i dati vengono interrogati in modo che il livello possa estrarre informazioni preziose.
- Livello di visualizzazione dei dati: la visualizzazione dei dati è il livello finale che si occupa della presentazione dei dati. Visualizza i dati in un formato comprensibile e visivo per consentire alla tua organizzazione di ottenere approfondimenti in tempo reale.
Vantaggi dell’inserimento dei dati

Parliamo di alcuni dei vantaggi dell’inserimento dei dati:
- Disponibilità: quando un’organizzazione implementa un processo di acquisizione dei dati, i dati possono essere accessibili e disponibili facilmente per l’organizzazione. Poiché i dati vengono raccolti da diverse fonti e trasferiti in un luogo di archiviazione, chiunque abbia un’autorizzazione valida può accedere facilmente ai dati per l’analisi.
- Uniformità: una buona pratica di inserimento dei dati migliora la qualità dei dati trasformando più tipi di dati in un tipo di dati unificato. In questo modo è più semplice manipolare e comprendere i dati per analisi future.
- Produttività migliorata: l’acquisizione dei dati ti consente di utilizzare i dati per diventare più produttivo. Ciò aiuta gli ingegneri dei dati a diventare più flessibili e consente loro di sviluppare la capacità di scalare.
- Processo decisionale migliorato: il processo di inserimento dei dati consente alle organizzazioni di prendere decisioni migliori e più informate utilizzando dati in tempo reale. Inoltre, puoi ricavare analisi utili per prendere decisioni tattiche e monitorare KPI e potenziali obiettivi.
- Esperienza utente migliorata: le organizzazioni utilizzano i dati recenti per servire i propri preziosi clienti. L’analisi basata sui dati consente loro di creare strumenti e applicazioni efficienti per i clienti.
Tipi di acquisizione dei dati
Esistono tre tipi di acquisizione dati: elaborazione batch, acquisizione dati in tempo reale e acquisizione dati basata su Lambda. La scelta di sceglierne uno dipende in gran parte dal tipo di attività, dall’infrastruttura IT, dal budget, dalla tempistica e dagli obiettivi da raggiungere. Inoltre, le aziende scelgono il modello e gli strumenti in base alle origini dati che utilizzano.
Approfondiamo ciascuno di essi in modo più dettagliato.
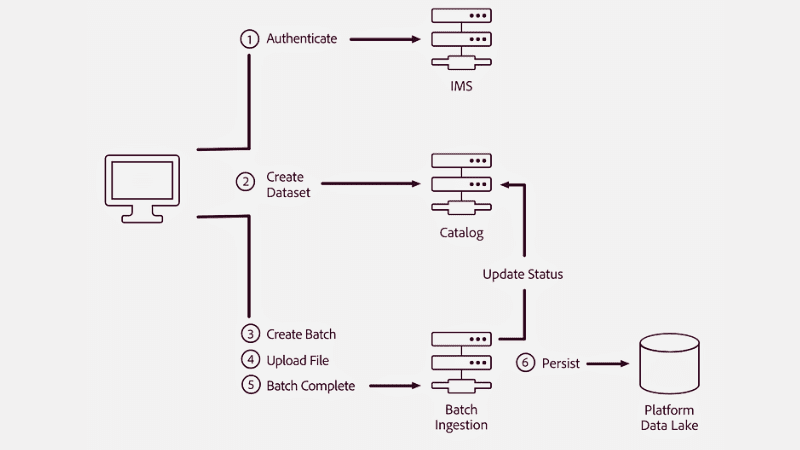
#1. Elaborazione in lotti
 Fonte: Adobe Experience League
Fonte: Adobe Experience League
È il metodo di ingestione più comune. Qui, il livello di acquisizione raccoglie e raggruppa i dati provenienti da diverse fonti in modo incrementale. Quindi trasferisce i dati in gruppi a un’applicazione, un sistema o una posizione in cui è richiesto.
Il trasferimento dei dati si basa sull’attivazione di condizioni politiche tramite eventi trigger, ordinamenti analogici o programmi esistenti per garantire il trasferimento dei dati. L’elaborazione batch è utile per le organizzazioni che necessitano di raccogliere dati specifici ogni giorno con attività che richiedono fogli di presenza, generazione di report, ecc.
Questo approccio è meno costoso e in molti casi è considerato un approccio legacy.
#2. Ingestione di dati in tempo reale
L’inserimento di dati in tempo reale è noto anche come elaborazione del flusso. Implica la raccolta e il trasferimento di dati da una determinata fonte in tempo reale alla destinazione. Qui non c’è alcun raggruppamento; invece, scoprirai che i dati vengono originati, caricati ed elaborati non appena il livello di acquisizione trova nuovi dati.
Per implementare l’acquisizione di dati in tempo reale, esiste una soluzione comune denominata Change Data Structure (CDC). Tuttavia, questo tipo di inserimento dati è più costoso dell’inserimento batch. Questo perché è necessario monitorare costantemente le fonti per riconoscere nuovi dati e garantire che si riflettano correttamente nella piattaforma target.
Se riduci la parte dei costi, questo metodo è molto utile per le aziende che desiderano eseguire analisi con dati sempre aggiornati per prendere decisioni operative.
Ad esempio, se desideri prendere decisioni di trading sul mercato azionario, l’acquisizione di dati in tempo reale è la soluzione migliore. Questo metodo è utile anche per monitorare la tua infrastruttura.
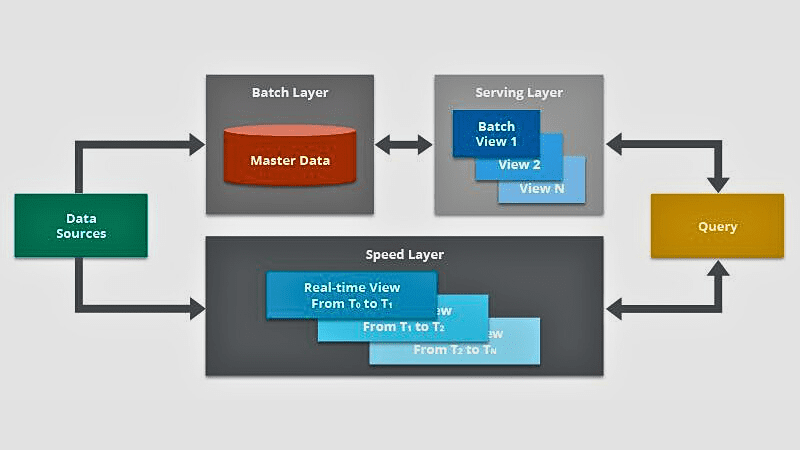
#3. Inserimento dati basato su Lambda
 Fonte: Hazelcast
Fonte: Hazelcast
Questo metodo è la combinazione di due tipi di acquisizione dati, ovvero elaborazione batch e acquisizione in tempo reale.
L’elaborazione batch viene utilizzata per raccogliere dati in batch, mentre l’inserimento di dati in tempo reale viene utilizzato per fornire una prospettiva diversa ai dati sensibili al fattore tempo. L’acquisizione di dati basata su Lambda divide i dati raccolti in gruppi e li acquisisce in incrementi più piccoli, rendendolo efficace per diverse applicazioni che necessitano di flussi di dati.
Casi d’uso di immissione di dati
Le organizzazioni di tutto il mondo utilizzano i processi di acquisizione dei dati come parte essenziale delle pipeline di dati nelle loro operazioni.
- Internet of Things (IoT): l’inserimento dei dati viene utilizzato in diversi sistemi IoT per raccogliere e trasformare i dati da un’ampia gamma di dispositivi connessi.
- Analisi dei Big Data: l’analisi dei Big Data è un requisito comune per ogni organizzazione. L’acquisizione di grandi volumi di dati da numerose fonti è quindi necessaria nell’analisi dei big data, dove i dati vengono elaborati con sistemi distribuiti come Spark o Hadoop.
- Rilevamento delle frodi: le organizzazioni utilizzano il processo di inserimento dei dati per rilevare le frodi importando e trasformando dati da diverse fonti. Ciò include il comportamento dei clienti, i feed di dati di terze parti e le transazioni.
- E-commerce: le aziende di e-commerce utilizzano il processo di inserimento dati per ricevere dati da diverse fonti, come transazioni dei clienti, cataloghi di prodotti, analisi di siti Web e altro ancora. Questo li aiuta a crescere con i dati giusti in tempo reale.
- Personalizzazione: il processo di inserimento dei dati può essere utilizzato per fornire esperienze o consigli personalizzati agli utenti estraendo dati da diverse fonti, come interazioni con i clienti, dati sui social media, analisi dei siti Web, ecc.
- Gestione della catena di fornitura: per gestire la catena di fornitura, un’organizzazione necessita di dati provenienti da fonti quali inventario, logistica e dati dei fornitori. L’acquisizione dei dati acquisisce questi dati da più fonti e li elabora per la gestione efficace della catena di fornitura.
- Analisi del sentiment e dei social media: l’acquisizione di dati in tempo reale aiuta le aziende a monitorare i feed dei social media, identificare le tendenze emergenti e analizzare in modo efficace il sentiment del marchio raccogliendo dati da varie fonti. Ciò porta a migliori relazioni con i clienti, allo sviluppo di strategie di cattura del mercato e a strategie di marketing efficaci.
Sfide

È possibile che si verifichino alcune sfide con il processo di importazione dei dati:
- Scalabilità: potresti riscontrare difficoltà nel ridimensionare un set di dati di grandi dimensioni durante l’acquisizione di dati da origini diverse. La quantità di dati elaborati richiede il ridimensionamento verticale o orizzontale dell’infrastruttura per gestire il carico maggiore, pertanto si verificano complicazioni.
- Qualità dei dati: la qualità dei dati rappresenta una sfida importante nel processo di acquisizione dei dati. Durante l’estrazione dei dati, non puoi sempre garantire che i dati che ricevi siano di alta qualità.
- Ecosistema diversificato: esistono molte origini e tipologie di dati, il che rende difficile per i tuoi team sviluppare un modello di acquisizione insonorizzato. Alcuni strumenti e funzionalità supportano solo le tecnologie di base, consentendo alle organizzazioni di utilizzare diversi strumenti che richiedono diversi set di competenze.
- Costo: il costo di acquisizione è direttamente proporzionale ai volumi di dati. Man mano che il tuo business in termini di valori dei dati cresce, aumentano anche i costi di acquisizione complessivi. Per acquisire tutti i dati, avrai bisogno di più server e sistemi di archiviazione, con un conseguente aumento dei costi di acquisizione.
- Sicurezza: poiché i dati vengono archiviati in numerosi punti della pipeline durante l’acquisizione, sono soggetti a esposizione dei dati e rischi per la sicurezza. Ciò rende vulnerabile il processo di acquisizione dei dati e ciò porterà a violazioni della sicurezza. Pertanto, le organizzazioni trovano difficile mantenere gli standard e le normative di conformità durante il processo.
- Integrazione dei dati: troverai qualche difficoltà nell’integrare i dati provenienti da fonti di terze parti con la pipeline di acquisizione. Ecco perché è necessario uno strumento completo che consenta di integrare i dati.
- Inaffidabilità: se in qualche modo si acquisiscono dati in modo errato, potrebbero essere soggetti a una connettività inaffidabile. Ciò si traduce in interruzione della comunicazione e perdita di dati.
Migliori pratiche
Parliamo di alcune pratiche di integrazione dei dati che puoi seguire per migliorare le prestazioni della tua azienda.
Inserimento automatizzato dei dati
L’inserimento automatizzato dei dati può risolvere molte sfide legate all’inserimento manuale. Riconosce la difficoltà e l’inevitabilità di trasformare i dati grezzi in informazioni utili, soprattutto quando i dati derivano da diverse fonti disparate.
Le organizzazioni possono utilizzare strumenti di inserimento dati per automatizzare i processi ricorrenti di raccolta dati per analisi e report migliori, riducendo l’errore umano.
Creare SLA sui dati
Gli SLA sui dati richiedono:
- Di cosa ha bisogno un’azienda
- Quali aspettative deve avere un’azienda riguardo ai dati
- Quando i dati possono soddisfare le aspettative
- Chi ne viene colpito
- Come si dovrebbe sapere quando lo SLA viene rispettato e quale sarà la risposta quando viene violato?
Pertanto, l’approccio di inserimento dei dati ti aiuta a ottenere tutti i dati necessari per creare SLA sui dati in modo efficace.
Larghezza di banda della rete
La pipeline di inserimento dati può essere creata in modo da poter gestire la larghezza di banda della rete in modo efficace.
Il traffico non è sempre costante, a volte aumenta o diminuisce in base ai parametri fisici e sociali. La larghezza di banda della rete dipende anche dalla quantità di dati da acquisire in un momento specifico.
Sistemi e tecnologie eterogenei

Un’organizzazione deve verificare se il modello di pipeline di immissione dei dati è compatibile con strumenti e applicazioni di terze parti, nonché con vari sistemi operativi.
Supporto per dati inaffidabili
La pipeline di inserimento dati riceve dati da diverse origini e varie strutture come file audio, file di registro, immagini e molto altro.
Strutture diverse necessitano di velocità diverse, consentendo a una rete inaffidabile di rendere inaffidabile l’intero gasdotto. Le organizzazioni devono progettare una pipeline di acquisizione dati che supporti tutti i formati senza essere inaffidabile.
Alta precisione
Il processo di acquisizione dei dati è direttamente proporzionale ai dati verificabili. Richiede un processo ben progettato in modo che possa modificare le funzioni intermediarie in base ai requisiti.
Flusso di dati
Le aziende necessitano di processi di acquisizione dati con elaborazione batch e in tempo reale per migliorare i propri servizi e ottenere la massima efficienza.
Disaccoppiamento dei database

Alcune organizzazioni, soprattutto quelle di grandi dimensioni, integrano direttamente il proprio database di analisi o business intelligence con il database operativo. Disaccoppiare i database analitici e operativi aiuta le organizzazioni a sovrapporre i problemi l’uno all’altro.
Conclusione
L’acquisizione dei dati fornisce informazioni immediate che ti consentono di comprendere le attuali tendenze del mercato, mantenere una bassa latenza e misurare le esperienze dei clienti. La pipeline di immissione dei dati è composta da vari livelli che partono dall’estrazione e raccolta dei dati fino alla loro visualizzazione e analisi.
Con l’acquisizione dei dati, le organizzazioni possono facilmente migliorare l’efficienza operativa, eseguire un rilevamento più rapido delle frodi, ottenere analisi in tempo reale e avviare una manutenzione proattiva. Le aziende possono anche utilizzare l’acquisizione di dati in tempo reale per ottenere informazioni aggiornate e utilizzarle per un vantaggio competitivo e un processo decisionale informato.
Puoi anche leggere informazioni sull’orchestrazione dei dati in termini semplici.