

L’informatica è al suo apice in questi giorni e continua a crescere. Negli ultimi 3 decenni, le macchine si sono evolute e migliorate di molto, soprattutto in termini di potenza di elaborazione e multitasking.
Riesci persino a immaginare quanto potrebbe essere folle l’aumento delle prestazioni se le attività fossero condivise tra più macchine ed eseguite in parallelo? Questo si chiama calcolo distribuito. È come il lavoro di squadra per i computer.
Tuttavia, potresti chiederti perché stiamo discutendo di questa cosa del calcolo distribuito. Perché il calcolo distribuito e Amazon EMR (Elastic MapReduce) sono altamente correlati. In altre parole, EMR di AWS utilizza i principi del calcolo distribuito per elaborare e analizzare grandi quantità di dati nel cloud.
Con Amazon EMR, ora puoi analizzare ed elaborare big data utilizzando un framework di elaborazione distribuito di tua scelta su istanze S3.
Sommario:
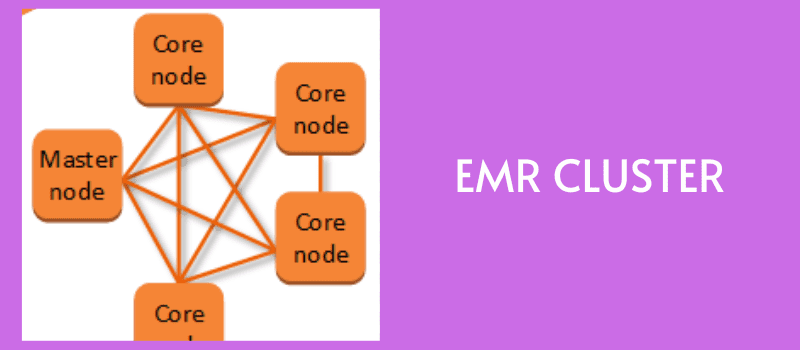
Come funziona Amazon EMR?
Fonte: www.aws.amazon.com
In primo luogo, inserisci i dati in qualsiasi archivio dati come Amazon S3, DynamoDB o altre piattaforme di archiviazione AWS, poiché si integrano tutti bene con l’EMR.
Ora, avrai bisogno di un framework di big data per elaborare e analizzare questi dati. Con vari framework per big data tra cui scegliere, come Apache Spark, Hadoop, Hive e Presto, puoi scegliere quello che si adatta alle tue esigenze e caricarlo nell’archivio dati scelto.
Viene creato un cluster EMR di istanze EC2 per elaborare e analizzare parallelamente i dati. Puoi configurare il numero di nodi e altri dettagli per creare il cluster.
Il tuo storage primario distribuisce i dati e i framework a questi nodi, dove i blocchi di dati vengono elaborati individualmente e i risultati vengono combinati.
Una volta che i risultati sono disponibili, puoi terminare il cluster per rilasciare tutte le risorse allocate.
Vantaggi di Amazon EMR
Le aziende, piccole o grandi, prendono sempre in considerazione l’adozione di soluzioni convenienti. Allora perché non un conveniente Amazon EMR? Quando può semplificare l’esecuzione di vari framework di big data su AWS, fornendo un modo conveniente per elaborare e analizzare i tuoi dati risparmiando denaro.
✅ Elasticità: puoi indovinare la sua natura tramite il termine “Elastic MapReduce”. Il termine dice: in base ai requisiti, Amazon EMR consente di ridimensionare facilmente i cluster manualmente o automaticamente. Ad esempio, potresti aver bisogno di 200 istanze per elaborare le tue richieste ora e questo potrebbe passare a 600 istanze dopo un’ora o due. Pertanto, Amazon EMR è il migliore quando hai solo bisogno di scalabilità per adattarsi ai rapidi cambiamenti della domanda.
✅ Archivi dati: che si tratti di Amazon S3, file system distribuito Hadoop, Amazon DynamoDB o altri archivi dati AWS, Amazon EMR si integra perfettamente con esso.
✅ Strumenti di elaborazione dei dati: Amazon EMR supporta vari framework di big data, tra cui Apache Spark, Hive, Hadoop e Presto. Inoltre, puoi eseguire algoritmi e strumenti di deep learning e machine learning su questo framework.
✅ Conveniente: a differenza di altri prodotti commerciali, Amazon EMR ti consente di pagare solo per le risorse che utilizzi su base oraria. Inoltre, puoi scegliere tra diversi modelli di prezzo in linea con il tuo budget.
✅ Personalizzazione del cluster: il framework ti consente di personalizzare ogni istanza del tuo cluster. Inoltre, puoi accoppiare un framework per big data con un tipo di cluster perfetto. Ad esempio, le istanze basate su Apache Spark e Graviton2 sono una combinazione letale per prestazioni ottimizzate nell’EMR.
✅ Controlli di accesso: puoi sfruttare gli strumenti AWS Identity and Access Management (IAM) per controllare le autorizzazioni nell’EMR. Ad esempio, puoi consentire a utenti specifici di modificare il cluster mentre altri possono solo visualizzare il cluster.
✅ Integrazione: l’integrazione di EMR con tutti gli altri servizi AWS è semplice. Con questo, puoi ottenere la potenza dei server virtuali, sicurezza solida, capacità estendibile e capacità di analisi nell’EMR.
Casi d’uso di Amazon EMR
#1. Apprendimento automatico

Analizza i dati utilizzando il machine learning e il deep learning in Amazon EMR. Ad esempio, l’esecuzione di vari algoritmi sui dati relativi alla salute per tenere traccia di più parametri di salute, come l’indice di massa corporea, la frequenza cardiaca, la pressione sanguigna, la percentuale di grasso, ecc., è fondamentale per sviluppare un fitness tracker. Tutto questo può essere fatto su istanze EMR in modo più rapido ed efficiente.
#2. Eseguire grandi trasformazioni
I rivenditori di solito estraggono una grande quantità di dati digitali per analizzare il comportamento dei clienti e migliorare il business. Sulla stessa linea, Amazon EMR sarà efficiente nell’estrazione di big data e nell’esecuzione di grandi trasformazioni utilizzando Spark.
#3. Estrazione dei dati

Vuoi affrontare un set di dati che richiede molto tempo per l’elaborazione? Amazon EMR è esclusivo per il data mining e l’analisi predittiva di set di dati complessi, in particolare nei casi di dati non strutturati. Inoltre, la sua architettura a cluster è ottima per l’elaborazione parallela.
#4. Finalità della ricerca
Porta a termine la tua ricerca con questo framework conveniente ed efficiente chiamato Amazon EMR. A causa della sua scalabilità, raramente si riscontrano problemi di prestazioni durante l’esecuzione di set di dati di grandi dimensioni su EMR. Quindi, questo framework è altamente adattato nei laboratori di analisi e ricerca sui big data.
#5. Streaming in tempo reale
Un altro grande vantaggio di Amazon EMR è il supporto per lo streaming in tempo reale. Crea pipeline di dati in streaming in tempo reale scalabili per giochi online, streaming video, monitoraggio del traffico e trading azionario utilizzando Apache Kafka e Apache Flink su Amazon EMR.
In che modo l’EMR è diverso da Amazon Glue e Redshift?
AWS EMR rispetto alla colla
I due potenti servizi AWS, Amazon EMR e Amazon Glue, hanno ottenuto un’osservazione leale nel trattare i tuoi dati.
Estrarre dati da varie fonti, trasformarli e caricarli nei data warehouse è rapido ed efficiente con Amazon Glue, mentre Amazon EMR ti aiuta a elaborare le tue applicazioni di big data utilizzando Hadoop, Spark, Hive, ecc.,
Fondamentalmente, AWS Glue ti consente di raccogliere e preparare i dati per l’analisi e Amazon EMR ti consente di elaborarli.
EMR contro spostamento verso il rosso
Immagina di navigare costantemente tra i tuoi dati e di interrogarli con facilità. SQL è qualcosa che usi spesso per fare questo. Sulla stessa linea, Redshift offre servizi di elaborazione analitica online ottimizzati per interrogare facilmente grandi volumi di dati utilizzando SQL.
Durante l’archiviazione dei dati, avrai accesso a fornitori di storage di terze parti altamente scalabili, sicuri e disponibili che Amazon EMR utilizza come S3 e DynamoDB. Al contrario, Redshift ha il proprio livello dati, che consente di archiviare i dati in formato colonnare.
Approcci di ottimizzazione dei costi di Amazon EMR

#1. Vieni con dati formattati
Più grandi sono i dati, più tempo ci vuole per elaborarli. Inoltre, fornire i dati grezzi direttamente al cluster lo rende ancora più complesso, richiedendo più tempo per trovare la parte che si intende elaborare.
Pertanto, i dati formattati vengono forniti con metadati su colonne, tipo di dati, dimensioni e altro, utilizzando i quali è possibile risparmiare tempo nelle ricerche e nelle aggregazioni.
Inoltre, riduci le dimensioni dei dati sfruttando le tecniche di compressione dei dati, poiché è relativamente più semplice elaborare set di dati più piccoli.
#2. Utilizza servizi di archiviazione convenienti
L’utilizzo di servizi di storage primari a costi contenuti riduce le maggiori spese EMR. Amazon s3 è un servizio di archiviazione semplice ed economico per il salvataggio dei dati di input e output. Il suo modello pay-as-you-go addebita solo lo spazio di archiviazione effettivamente utilizzato.
#3. Dimensionamento dell’istanza corretta
L’utilizzo di istanze appropriate con le giuste dimensioni può ridurre significativamente il budget speso per EMR. Le istanze EC2 vengono in genere addebitate al secondo e il prezzo varia in base alle loro dimensioni, ma sia che utilizzi un cluster grande 0,7 volte o un cluster grande 0,36 volte, il costo di gestione è lo stesso. Pertanto, l’utilizzo efficiente di macchine più grandi è conveniente rispetto all’utilizzo di più macchine piccole.
#4. Istanze Spot
Le istanze Spot sono un’ottima opzione per acquistare risorse EC2 inutilizzate a prezzi scontati. Rispetto alle istanze on demand, queste sono più economiche ma non sono permanenti in quanto possono essere reclamate quando la domanda aumenta. Quindi, questi sono flessibili per la tolleranza agli errori ma non adatti a lavori di lunga durata.
#5. Ridimensionamento automatico
La sua funzione di ridimensionamento automatico è tutto ciò di cui hai bisogno per evitare cluster sovradimensionati o sottodimensionati. Ciò ti consente di scegliere il numero e il tipo corretti di istanze nel tuo cluster in base al carico di lavoro, ottimizzando i costi.
Parole finali
Non c’è fine al cloud e alla tecnologia dei big data, lasciandoti infiniti strumenti e framework da apprendere e implementare. Una di queste singole piattaforme per sfruttare sia i big data che il cloud è Amazon EMR, in quanto semplifica l’esecuzione di framework di big data per elaborare e analizzare dati di grandi dimensioni.
Per aiutarti a iniziare con l’EMR, questo articolo mostra che cos’è, come ne trae vantaggio, come funziona, i suoi casi d’uso e gli approcci convenienti.
Successivamente, controlla tutto ciò che devi sapere su AWS Athena.