
Sei pronto per apprendere l’ingegneria delle funzionalità per l’apprendimento automatico e la scienza dei dati? Sei nel posto giusto!
L’ingegneria delle funzionalità è una competenza fondamentale per estrarre informazioni preziose dai dati e in questa guida rapida la suddividerò in parti semplici e digeribili. Quindi, tuffiamoci subito e iniziamo il tuo viaggio verso la padronanza dell’estrazione delle funzionalità!
Sommario:
Cos’è l’ingegneria delle caratteristiche?

Quando crei un modello di machine learning correlato a un problema aziendale o sperimentale, fornisci i dati di apprendimento in colonne e righe. Nel dominio della scienza dei dati e dello sviluppo ML, le colonne sono note come attributi o variabili.
I dati granulari o le righe sotto queste colonne sono noti come osservazioni o istanze. Le colonne o gli attributi sono le caratteristiche di un set di dati grezzi.
Queste funzionalità grezze non sono sufficienti o ottimali per addestrare un modello ML. Per ridurre il rumore dei metadati raccolti e massimizzare i segnali univoci provenienti dalle funzionalità, è necessario trasformare o convertire le colonne di metadati in funzionalità funzionali attraverso l’ingegneria delle funzionalità.
Esempio 1: modellazione finanziaria
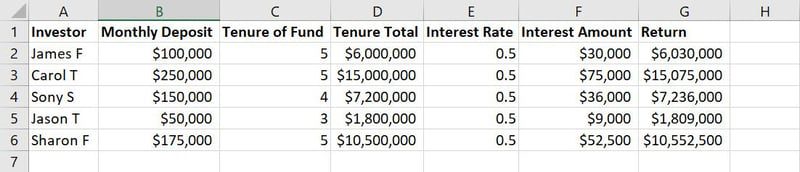 Dati grezzi per l’addestramento del modello ML
Dati grezzi per l’addestramento del modello ML
Ad esempio, nell’immagine sopra di un set di dati di esempio, le colonne da A a G sono caratteristiche. I valori o le stringhe di testo in ciascuna colonna lungo le righe, come nomi, importo del deposito, anni di deposito, tassi di interesse, ecc., sono osservazioni.
Nella modellazione ML è necessario eliminare, aggiungere, combinare o trasformare i dati per creare funzionalità significative e ridurre le dimensioni del database di training del modello complessivo. Questa è ingegneria delle funzionalità.
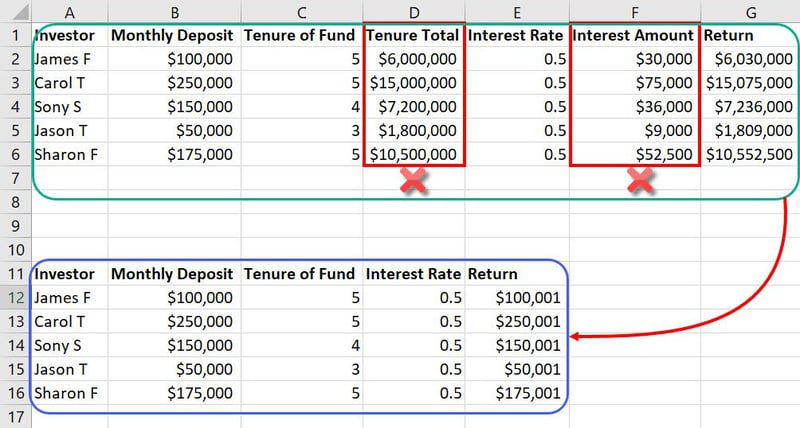 Esempio di ingegneria delle funzionalità
Esempio di ingegneria delle funzionalità
Nello stesso set di dati menzionato in precedenza, funzionalità come Totale possesso e Importo interessi sono input non necessari. Questi occuperanno semplicemente più spazio e confonderanno il modello ML. Pertanto, puoi ridurre due funzionalità da un totale di sette funzionalità.
Poiché i database nei modelli ML contengono migliaia di colonne e milioni di righe, la riduzione di due funzionalità ha un notevole impatto sul progetto.
Esempio 2: Creatore di playlist musicali AI
A volte, puoi creare una funzionalità completamente nuova da più funzionalità esistenti. Supponiamo che tu stia creando un modello AI che creerà automaticamente una playlist di musica e brani in base all’evento, al gusto, alla modalità, ecc.
Ora hai raccolto dati su brani e musica da varie fonti e hai creato il seguente database:
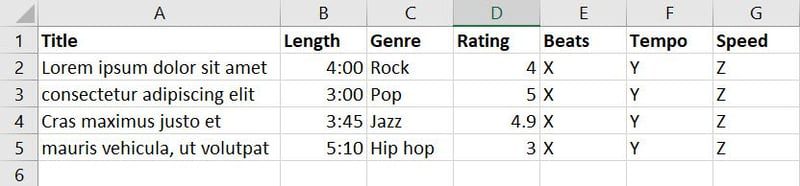
Ci sono sette funzionalità nel database di cui sopra. Tuttavia, poiché il tuo obiettivo è addestrare il modello ML per decidere quale brano o musica è adatto a quale evento, puoi unire funzionalità come Genere, Valutazione, Battute, Tempo e Velocità in una nuova funzionalità chiamata Applicabilità.
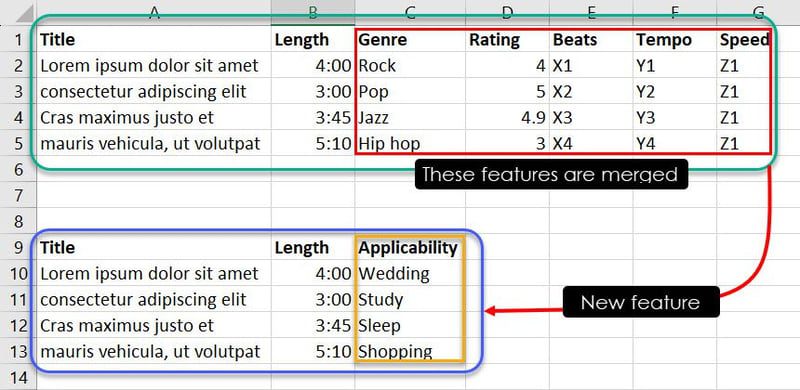
Ora, attraverso l’esperienza o l’identificazione di modelli, puoi combinare determinate istanze di funzionalità per determinare quale canzone è adatta a quale evento. Ad esempio, osservazioni come Jazz, 4.9, X3, Y3 e Z1 dicono al modello ML che la canzone Cras maximus justo et dovrebbe essere nella playlist dell’utente se sta cercando una canzone per dormire.
Tipi di funzionalità nell’apprendimento automatico
Caratteristiche categoriche
Si tratta di attributi di dati che rappresentano categorie o etichette distinte. È necessario utilizzare questo tipo per contrassegnare i set di dati qualitativi.
#1. Caratteristiche categoriche ordinali
Le caratteristiche ordinali hanno categorie con un ordine significativo. Ad esempio, i livelli di istruzione come High School, Bachelor, Master, ecc., hanno una chiara distinzione negli standard, ma non ci sono differenze quantitative.
#2. Caratteristiche categoriche nominali
Le caratteristiche nominali sono categorie senza alcun ordine intrinseco. Gli esempi potrebbero essere colori, paesi o tipi di animali. Inoltre, ci sono solo differenze qualitative.
Funzionalità della matrice
Questo tipo di funzionalità rappresenta i dati organizzati in matrici o elenchi. I data scientist e gli sviluppatori di ML utilizzano spesso le funzionalità di array per gestire sequenze o incorporare dati categorici.
#1. Incorporamento di funzionalità di array
Gli array di incorporamento convertono i dati categorici in vettori densi. È comunemente usato nei sistemi di elaborazione e raccomandazione del linguaggio naturale.
#2. Elenca le funzionalità dell’array
Gli array di elenchi memorizzano sequenze di dati, come elenchi di elementi in un ordine o cronologia di azioni.
Caratteristiche numeriche
Queste funzionalità di training ML vengono utilizzate per eseguire operazioni matematiche poiché rappresentano dati quantitativi.
#1. Caratteristiche numeriche degli intervalli
Le funzionalità di intervallo hanno intervalli coerenti tra i valori ma nessun vero punto zero, ad esempio i dati di monitoraggio della temperatura. Qui zero significa temperatura di congelamento, ma l’attributo è ancora lì.
#2. Caratteristiche numeriche del rapporto
Le caratteristiche del rapporto hanno intervalli coerenti tra i valori e un vero punto zero. Gli esempi includono età, altezza e reddito.
Importanza dell’ingegneria delle caratteristiche nel machine learning e nella scienza dei dati
Successivamente, esploreremo il processo passo passo di ingegneria delle funzionalità.
Processo di progettazione delle funzionalità passo dopo passo

Successivamente discuteremo dei metodi di ingegneria delle funzionalità.
Metodi di ingegneria delle caratteristiche
#1. Analisi delle componenti principali (PCA)
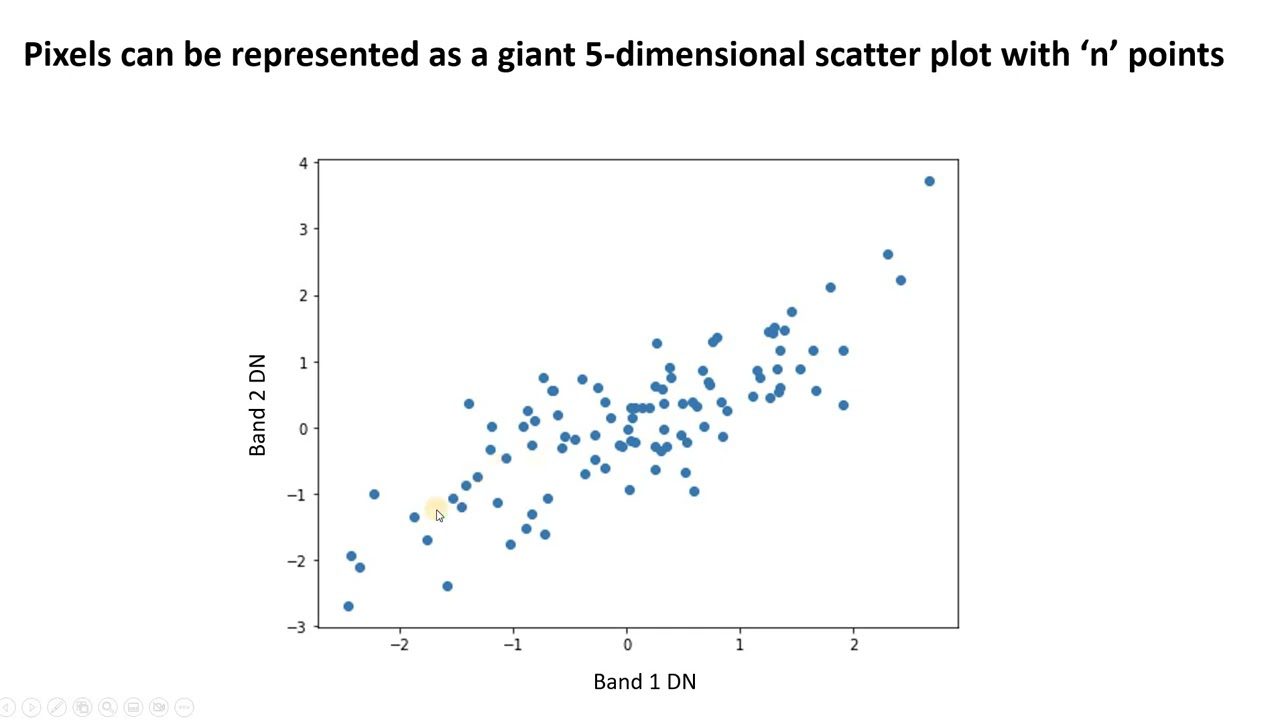
PCA semplifica i dati complessi trovando nuove funzionalità non correlate. Questi sono chiamati componenti principali. Puoi usarlo per ridurre la dimensionalità e migliorare le prestazioni del modello.
#2. Caratteristiche polinomiali
Creare funzionalità polinomiali significa aggiungere poteri alle funzionalità esistenti per acquisire relazioni complesse nei dati. Aiuta il tuo modello a comprendere modelli non lineari.
#3. Gestione dei valori anomali
I valori anomali sono punti dati insoliti che possono influire sulle prestazioni dei modelli. È necessario identificare e gestire i valori anomali per evitare risultati distorti.
#4. Trasformazione registro
La trasformazione logaritmica può aiutarti a normalizzare i dati con una distribuzione distorta. Riduce l’impatto dei valori estremi per rendere i dati più adatti alla modellazione.
#5. Incorporamento del vicino stocastico distribuito t (t-SNE)
t-SNE è utile per visualizzare dati ad alta dimensione. Riduce la dimensionalità e rende i cluster più evidenti preservando la struttura dei dati.
In questo metodo di estrazione delle feature, i punti dati vengono rappresentati come punti in uno spazio a dimensione inferiore. Quindi, si posizionano i punti dati simili nello spazio originale ad alta dimensione e si modellano per essere vicini l’uno all’altro nella rappresentazione a dimensione inferiore.
Si differenzia dagli altri metodi di riduzione della dimensionalità preservando la struttura e le distanze tra i punti dati.
#6. Codifica One-Hot
La codifica one-hot trasforma le variabili categoriali in formato binario (0 o 1). Quindi, ottieni nuove colonne binarie per ogni categoria. La codifica one-hot rende i dati categorici adatti agli algoritmi ML.
#7. Conteggio della codifica
La codifica del conteggio sostituisce i valori categoriali con il numero di volte in cui compaiono nel set di dati. Può acquisire informazioni preziose da variabili categoriali.
In questo metodo di progettazione delle caratteristiche, si utilizza la frequenza o il conteggio di ciascuna categoria come una nuova caratteristica numerica invece di utilizzare le etichette di categoria originali.
#8. Standardizzazione delle funzionalità

Le caratteristiche di valori più grandi spesso dominano le caratteristiche di valori piccoli. Pertanto, il modello ML può facilmente essere distorto. La standardizzazione previene tali cause di pregiudizi in un modello di apprendimento automatico.
Il processo di standardizzazione coinvolge tipicamente le seguenti due tecniche comuni:
- Standardizzazione del punteggio Z: questo metodo trasforma ciascuna caratteristica in modo che abbia una media (media) di 0 e una deviazione standard di 1. Qui, sottrai la media della caratteristica da ciascun punto dati e dividi il risultato per la deviazione standard.
- Ridimensionamento Min-Max: il ridimensionamento Min-Max trasforma i dati in un intervallo specifico, in genere compreso tra 0 e 1. Puoi ottenere questo risultato sottraendo il valore minimo della caratteristica da ciascun punto dati e dividendo per l’intervallo.
#9. Normalizzazione
Attraverso la normalizzazione, le caratteristiche numeriche vengono ridimensionate in un intervallo comune, solitamente compreso tra 0 e 1. Mantiene le differenze relative tra i valori e garantisce che tutte le caratteristiche siano su un piano di parità.

#1. Strumenti di funzionalità
Strumenti di funzionalità è un framework Python open source che crea automaticamente funzionalità da set di dati temporali e relazionali. Può essere utilizzato con gli strumenti già utilizzati per sviluppare pipeline ML.
La soluzione utilizza la Deep Feature Synthesis per automatizzare la progettazione delle funzionalità. Ha una libreria di funzioni di basso livello per la creazione di funzionalità. Featuretools dispone anche di un’API, ideale anche per una gestione precisa del tempo.
#2. CatBoost
Se stai cercando una libreria open source che combini più alberi decisionali per creare un potente modello predittivo, scegli CatBoost. Questa soluzione offre risultati accurati con parametri predefiniti, quindi non è necessario dedicare ore alla messa a punto dei parametri.
CatBoost ti consente anche di utilizzare fattori non numerici per migliorare i risultati dell’allenamento. Con esso, puoi anche aspettarti di ottenere risultati più accurati e previsioni rapide.
#3. Motore di funzionalità
Motore di funzionalità è una libreria Python con più trasformatori e funzionalità selezionate che puoi utilizzare per i modelli ML. I trasformatori che include possono essere utilizzati per la trasformazione di variabili, la creazione di variabili, funzionalità di data e ora, preelaborazione, codifica categoriale, limitazione o rimozione di valori anomali e imputazione di dati mancanti. È in grado di riconoscere automaticamente le variabili numeriche, categoriali e data/ora.
Caratteristica Risorse per l’apprendimento dell’ingegneria
Corsi online e lezioni virtuali

#1. Ingegneria delle funzionalità per l’apprendimento automatico in Python: Datacamp
Questo campo dati corso sull’ingegneria delle funzionalità per l’apprendimento automatico in Python ti consente di creare nuove funzionalità che migliorano le prestazioni del tuo modello di Machine Learning. Ti insegnerà a eseguire l’ingegneria delle funzionalità e l’ottimizzazione dei dati per sviluppare sofisticate applicazioni ML.
#2. Ingegneria delle funzionalità per l’apprendimento automatico: Udemy
Dal Corso di Feature Engineering per l’apprendimento automaticoimparerai argomenti tra cui imputazione, codifica delle variabili, estrazione di caratteristiche, discretizzazione, funzionalità data/ora, valori anomali, ecc. I partecipanti impareranno anche a lavorare con variabili distorte e a gestire categorie poco frequenti, invisibili e rare.
#3. Ingegneria delle funzionalità: Pluralsight
Questo Visione plurale il percorso di apprendimento prevede un totale di sei corsi. Questi corsi ti aiuteranno ad apprendere l’importanza dell’ingegneria delle funzionalità nel flusso di lavoro ML, i modi per applicarne le tecniche e l’estrazione delle funzionalità da testo e immagini.
#4. Selezione delle funzionalità per l’apprendimento automatico: Udemy
Con l’aiuto di questo Udemy Durante il corso, i partecipanti possono apprendere metodi di mescolamento delle funzionalità, filtri, wrapper e incorporati, eliminazione ricorsiva delle funzionalità e ricerca esaustiva. Vengono inoltre discusse le tecniche di selezione delle funzionalità, comprese quelle con Python, Lasso e alberi decisionali. Questo corso contiene 5,5 ore di video on-demand e 22 articoli.
#5. Ingegneria delle funzionalità per l’apprendimento automatico: ottimo apprendimento
Questo corso da Ottimo apprendimento ti introdurrà all’ingegneria delle funzionalità mentre ti insegnerà il sovracampionamento e il sottocampionamento. Inoltre, ti consentirà di eseguire esercizi pratici sulla messa a punto del modello.
#6. Ingegneria delle caratteristiche: Coursera
Aderire al Coursera corso per utilizzare BigQuery ML, Keras e TensorFlow per eseguire l’ingegneria delle funzionalità. Questo corso di livello intermedio copre anche le pratiche avanzate di ingegneria delle funzionalità.
Libri digitali o con copertina rigida

#1. Ingegneria delle funzionalità per l’apprendimento automatico
Questo libro ti insegna come trasformare le funzionalità in formati per modelli di apprendimento automatico.
Ti insegna anche i principi ingegneristici e l’applicazione pratica attraverso l’esercizio.
#2. Ingegneria e selezione delle funzionalità
Leggendo questo libro imparerai i metodi per sviluppare modelli predittivi in diverse fasi.
Da esso è possibile apprendere le tecniche per trovare le migliori rappresentazioni dei predittori per la modellazione.
#3. La progettazione delle funzionalità diventa semplice
Il libro è una guida per migliorare il potere di previsione degli algoritmi ML.
Ti insegna a progettare e creare funzionalità efficienti per applicazioni basate su ML offrendo approfondimenti sui dati.
#4. Caratteristica Bookcamp di ingegneria
Questo libro tratta casi di studio pratici per insegnarti tecniche di ingegneria delle funzionalità per risultati ML migliori e gestione dei dati aggiornata.
La lettura di questo ti garantirà di poter fornire risultati migliori senza dedicare molto tempo alla messa a punto dei parametri ML.
#5. L’arte dell’ingegneria delle caratteristiche
La risorsa funziona come un elemento essenziale per qualsiasi data scientist o ingegnere di machine learning.
Il libro utilizza un approccio interdisciplinare per discutere grafici, testi, serie temporali, immagini e casi di studio.
Conclusione
Quindi, ecco come è possibile eseguire l’ingegneria delle funzionalità. Ora che conosci la definizione, il processo graduale, i metodi e le risorse di apprendimento, puoi implementarli nei tuoi progetti ML e vedere il successo!
Successivamente, consulta l’articolo sull’apprendimento per rinforzo.