

Il 1 ° settembre 2020, NVIDIA ha rivelato la sua nuova gamma di GPU da gioco: la serie RTX 3000, basata sulla loro architettura Ampere. Discuteremo delle novità, del software basato sull’intelligenza artificiale che lo accompagna e di tutti i dettagli che rendono questa generazione davvero fantastica.
Sommario:
Scopri le GPU della serie RTX 3000

L’annuncio principale di NVIDIA sono state le sue nuove splendenti GPU, tutte basate su un processo di produzione personalizzato a 8 nm, e tutte che hanno portato a importanti accelerazioni sia nelle prestazioni di rasterizzazione che di ray-tracing.
Nella fascia bassa della scaletta, c’è il RTX 3070, che arriva a $ 499. È un po ‘costoso per la scheda più economica svelata da NVIDIA all’annuncio iniziale, ma è un vero affare una volta che si apprende che batte l’attuale RTX 2080 Ti, una scheda di punta che viene regolarmente venduta al dettaglio per oltre $ 1400. Tuttavia, dopo l’annuncio di NVIDIA, i prezzi di vendita di terze parti sono diminuiti, con un gran numero di loro venduti dal panico su eBay per meno di $ 600.
Non ci sono benchmark solidi al momento dell’annuncio, quindi non è chiaro se la scheda sia davvero oggettivamente “migliore” di una 2080 Ti, o se NVIDIA stia stravolgendo un po ‘il marketing. I benchmark eseguiti erano a 4K e probabilmente avevano RTX, il che potrebbe far sembrare il divario più ampio di quanto non sarà nei giochi puramente rasterizzati, poiché la serie 3000 basata su Ampere funzionerà oltre il doppio con il ray tracing rispetto a Turing. Ma, con il ray tracing che ora è qualcosa che non danneggia molto le prestazioni, ed essendo supportato nell’ultima generazione di console, è un importante punto di forza farlo funzionare alla stessa velocità dell’ammiraglia di ultima generazione per quasi un terzo del prezzo.
Inoltre, non è chiaro se il prezzo rimarrà tale. I progetti di terze parti aggiungono regolarmente almeno $ 50 al prezzo e, vista la forte domanda, non sarà sorprendente vederlo venduto per $ 600 nell’ottobre 2020.
Appena sopra c’è il file RTX 3080 a $ 699, che dovrebbe essere il doppio più veloce dell’RTX 2080, e arrivare circa il 25-30% più veloce del 3080.
Quindi, all’estremità superiore, la nuova ammiraglia è la RTX 3090, che è comicamente enorme. NVIDIA lo sa bene e lo chiama “BFGPU”, che secondo la società sta per “Big Ferocious GPU”.

NVIDIA non ha mostrato alcuna metrica delle prestazioni dirette, ma la società ha mostrato di eseguire giochi 8K a 60 FPS, il che è davvero impressionante. Certo, NVIDIA sta quasi certamente utilizzando DLSS per raggiungere questo traguardo, ma i giochi 8K sono giochi 8K.
Ovviamente, alla fine ci sarà un 3060 e altre varianti di carte più orientate al budget, ma quelle di solito arrivano più tardi.
Per raffreddare effettivamente le cose, NVIDIA aveva bisogno di un design più fresco e rinnovato. Il 3080 è valutato per 320 watt, che è piuttosto alto, quindi NVIDIA ha optato per un design a doppia ventola, ma invece di entrambe le ventole vwinf posizionate sul fondo, NVIDIA ha messo una ventola all’estremità superiore dove di solito va la piastra posteriore. La ventola dirige l’aria verso l’alto verso il dispositivo di raffreddamento della CPU e la parte superiore del case.

A giudicare da quanto le prestazioni possono essere influenzate da un cattivo flusso d’aria in una custodia, questo ha perfettamente senso. Tuttavia, il circuito stampato è molto angusto a causa di ciò, che probabilmente influenzerà i prezzi di vendita di terze parti.
DLSS: un vantaggio software
Il ray tracing non è l’unico vantaggio di queste nuove carte. In realtà, è tutto un po ‘un trucco: le serie RTX 2000 e 3000 non sono molto migliori nel fare il ray tracing effettivo, rispetto alle vecchie generazioni di schede. Il ray tracing di una scena completa in software 3D come Blender di solito richiede pochi secondi o addirittura minuti per fotogramma, quindi forzarlo in meno di 10 millisecondi è fuori questione.
Naturalmente, esiste un hardware dedicato per l’esecuzione dei calcoli dei raggi, chiamato core RT, ma in gran parte, NVIDIA ha optato per un approccio diverso. NVIDIA ha migliorato gli algoritmi di denoising, che consentono alle GPU di eseguire il rendering di un singolo passaggio molto economico che sembra terribile e in qualche modo, attraverso la magia dell’IA, lo trasforma in qualcosa che un giocatore vuole guardare. Se combinato con le tradizionali tecniche basate sulla rasterizzazione, crea un’esperienza piacevole migliorata dagli effetti di raytracing.

Tuttavia, per farlo velocemente, NVIDIA ha aggiunto core di elaborazione specifici per AI chiamati core Tensor. Questi elaborano tutta la matematica richiesta per eseguire modelli di apprendimento automatico e lo fanno molto rapidamente. Sono un totale rivoluzionario per l’IA nello spazio del server cloud, poiché l’IA è ampiamente utilizzata da molte aziende.
Al di là del denoising, l’uso principale dei core Tensor per i giocatori è chiamato DLSS, o deep learning super sampling. Prende un frame di bassa qualità e lo trasforma in una qualità nativa completa. Ciò significa essenzialmente che puoi giocare con framerate di livello 1080p, mentre guardi un’immagine 4K.
Questo aiuta anche con le prestazioni di ray-tracing un po ‘-benchmark di PCMag mostra un RTX 2080 Super Running Control di qualità ultra, con tutte le impostazioni di ray-tracing al massimo. A 4K, fatica con solo 19 FPS, ma con DLSS attivo, ottiene un 54 FPS molto migliore. DLSS è prestazioni gratuite per NVIDIA, rese possibili dai core Tensor su Turing e Ampere. Qualsiasi gioco che lo supporti ed è limitato dalla GPU può vedere notevoli accelerazioni solo dal solo software.
DLSS non è nuovo ed è stato annunciato come funzionalità quando la serie RTX 2000 è stata lanciata due anni fa. A quel tempo, era supportato da pochissimi giochi, poiché richiedeva a NVIDIA di addestrare e mettere a punto un modello di apprendimento automatico per ogni singolo gioco.
Tuttavia, in quel periodo, NVIDIA lo ha completamente riscritto, chiamando la nuova versione DLSS 2.0. È un’API generica, il che significa che qualsiasi sviluppatore può implementarla ed è già stata rilevata dalla maggior parte delle principali versioni. Piuttosto che lavorare su un fotogramma, prende in movimento i dati vettoriali dal fotogramma precedente, in modo simile a TAA. Il risultato è molto più nitido di DLSS 1.0 e, in alcuni casi, sembra addirittura migliore e più nitido della risoluzione nativa, quindi non c’è motivo di non accenderlo.
C’è un problema: quando si cambia completamente le scene, come nei filmati, DLSS 2.0 deve rendere il primo fotogramma con una qualità del 50% in attesa dei dati del vettore di movimento. Ciò può comportare un leggero calo della qualità per pochi millisecondi. Ma il 99% di tutto ciò che guardi verrà renderizzato correttamente e la maggior parte delle persone non lo nota nella pratica.
Ampere Architecture: costruita per l’IA
Ampere è veloce. Seriamente veloce, soprattutto nei calcoli AI. Il core RT è 1,7 volte più veloce di Turing e il nuovo core Tensor è 2,7 volte più veloce di Turing. La combinazione dei due è un vero salto generazionale nelle prestazioni di raytracing.

All’inizio di maggio NVIDIA ha rilasciato la GPU Ampere A100, una GPU per data center progettata per eseguire l’IA. Con esso, hanno dettagliato molto di ciò che rende Ampere molto più veloce. Per i carichi di lavoro di data center e elaborazione ad alte prestazioni, Ampere è in generale circa 1,7 volte più veloce di Turing. Per l’allenamento AI, è fino a 6 volte più veloce.
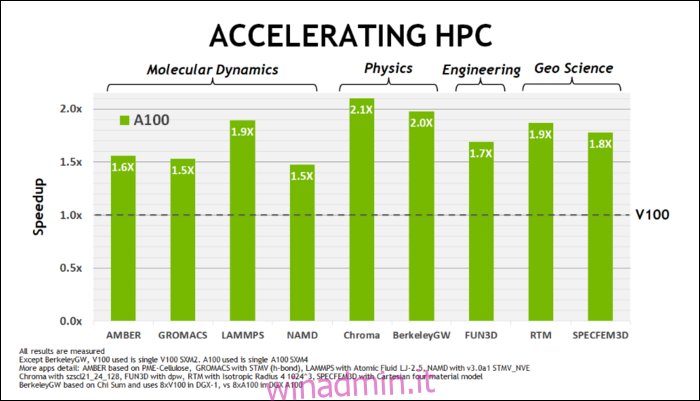
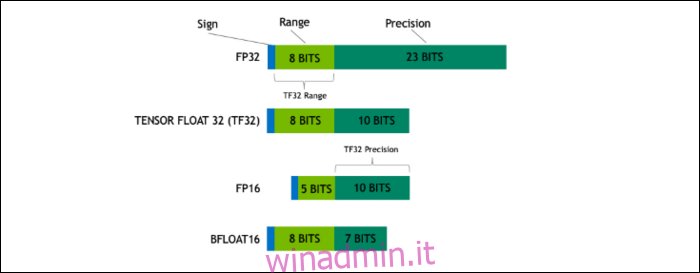
Con Ampere, NVIDIA utilizza un nuovo formato numerico progettato per sostituire lo standard di settore “Floating-Point 32” o FP32, in alcuni carichi di lavoro. Sotto il cofano, ogni numero elaborato dal tuo computer occupa un numero predefinito di bit in memoria, che si tratti di 8 bit, 16 bit, 32, 64 o anche più grandi. I numeri più grandi sono più difficili da elaborare, quindi se puoi usare una dimensione più piccola, avrai meno da scricchiolare.
FP32 memorizza un numero decimale a 32 bit e utilizza 8 bit per l’intervallo del numero (quanto grande o piccolo può essere) e 23 bit per la precisione. L’affermazione di NVIDIA è che questi 23 bit di precisione non sono del tutto necessari per molti carichi di lavoro AI e puoi ottenere risultati simili e prestazioni molto migliori da soli 10 di essi. Ridurre le dimensioni a soli 19 bit, invece di 32, fa una grande differenza in molti calcoli.
Questo nuovo formato si chiama Tensor Float 32, e i Tensor Core dell’A100 sono ottimizzati per gestire il formato di dimensioni strane. Questo è, oltre alla riduzione del dado e all’aumento del numero di core, il modo in cui ottengono l’enorme aumento di velocità 6 volte nell’addestramento AI.
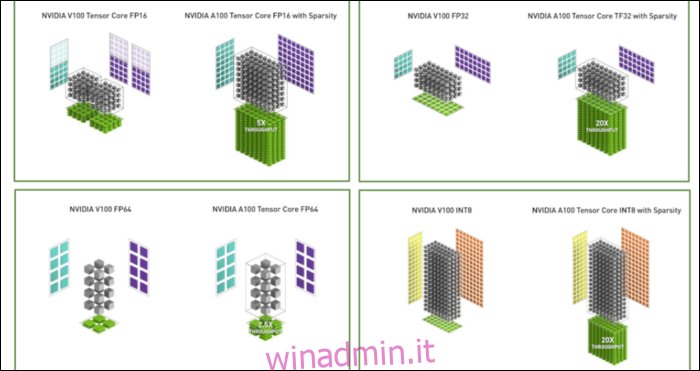
Oltre al nuovo formato numerico, Ampere sta vedendo importanti accelerazioni delle prestazioni in calcoli specifici, come FP32 e FP64. Questi non si traducono direttamente in più FPS per i profani, ma fanno parte di ciò che lo rende quasi tre volte più veloce nelle operazioni di Tensor.
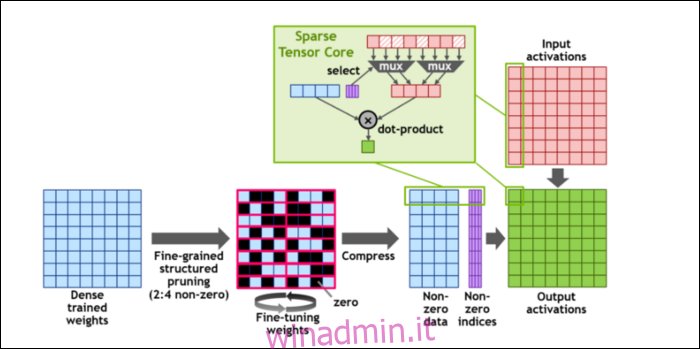
Quindi, per velocizzare ulteriormente i calcoli, hanno introdotto il concetto di scarsità strutturata a grana fine, che è una parola molto stravagante per un concetto piuttosto semplice. Le reti neurali funzionano con grandi elenchi di numeri, chiamati pesi, che influenzano l’output finale. Più numeri da sgranocchiare, più lento sarà.
Tuttavia, non tutti questi numeri sono effettivamente utili. Alcuni di loro sono letteralmente solo zero e possono fondamentalmente essere eliminati, il che porta a enormi accelerazioni quando puoi sgranocchiare più numeri allo stesso tempo. La scarsità essenzialmente comprime i numeri, il che richiede meno sforzi per eseguire i calcoli. Il nuovo “Sparse Tensor Core” è progettato per funzionare su dati compressi.
Nonostante i cambiamenti, NVIDIA afferma che ciò non dovrebbe influire in modo significativo sulla precisione dei modelli addestrati.
Per i calcoli Sparse INT8, uno dei formati numerici più piccoli, le prestazioni massime di una singola GPU A100 sono superiori a 1,25 PetaFLOP, un numero incredibilmente alto. Certo, è solo quando si scrive un tipo specifico di numero, ma è comunque impressionante.