
Data Lakehouse è un’architettura di gestione dei dati nuova ed emergente che combina le parti migliori di un data Lake e di un data warehouse. Utilizzando una Data Lakehouse, hai la possibilità di archiviare diversi tipi di dati in un’unica piattaforma ed eseguire query e analisi conformi ad ACID.
Quindi, perché utilizzare una Data Lakehouse? Essendo un ingegnere informatico senior, posso capire quanto sia difficile quando è necessario gestire e mantenere due sistemi separati e far fluire grandi volumi di dati dall’uno all’altro.
Se desideri utilizzare i tuoi dati per eseguire analisi aziendali e generare report, devi archiviare i dati strutturati in un data warehouse. D’altra parte, per archiviare tutti i dati provenienti da diverse fonti dati e nel formato originale, è necessario un data Lake. Avere un’unica casa sul lago elimina la necessità di mantenere sistemi diversi poiché offre il meglio di entrambi i mondi.
Sommario:
Importanza di Data Lakehouse

Per far crescere la tua organizzazione e il tuo business, devi essere in grado di archiviare e analizzare i dati indipendentemente dal formato o dalla struttura. I data Lakehouse sono importanti per la moderna gestione dei dati perché risolvono i limiti sia dei data Lake che dei data warehouse.
I tuoi data Lake possono spesso trasformarsi in paludi di dati, dove i dati vengono scaricati senza alcuna struttura o governance. Ciò rende difficile trovare e utilizzare i dati e può anche portare a problemi di qualità dei dati. D’altronde avere un data warehouse spesso porta ad essere troppo rigidi. Diventa anche costoso.
Una Data Lakehouse ha una propria serie di caratteristiche. Diamo un’occhiata a loro.
Caratteristiche di una Data Lakehouse
Prima di approfondire l’architettura della Data Lakehouse, vediamo le caratteristiche o le caratteristiche più importanti di una Data Lakehouse.
Architettura dei dati Lakehouse
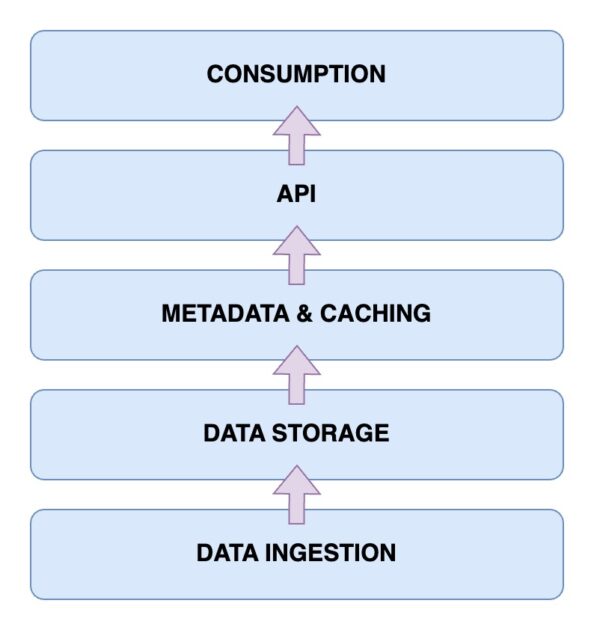
Ora è il momento di dare un’occhiata all’architettura di una Data Lakehouse. Comprendere l’architettura della Data Lakehouse è fondamentale per comprenderne il funzionamento. L’architettura Data Lakehouse è composta principalmente da cinque componenti principali. Osserviamoli uno per uno.
Livello di inserimento dati
Questo è il livello in cui vengono acquisiti tutti i diversi dati nei vari formati. Potrebbero trattarsi di modifiche ai dati nel database primario, dati provenienti da vari sensori IoT o dati utente in tempo reale che fluiscono attraverso flussi di dati.
Livello di archiviazione dei dati
Una volta che i dati sono stati acquisiti dalle varie fonti, è il momento di archiviarli nei formati corretti. È qui che entra in gioco il livello di storage. I dati possono essere archiviati su vari supporti come AWS S3. In effetti, questo è il tuo data Lake.
Metadati e livello di memorizzazione nella cache
Ora che hai predisposto il livello di archiviazione dei dati, hai bisogno di un livello di gestione dei metadati e dei dati. Ciò fornisce una visualizzazione unificata di tutti i dati presenti nel data Lake. Questo è anche il livello che aggiunge le transazioni ACID al data Lake esistente per trasformarlo in una Data Lakehouse.
Livello API
Puoi accedere ai dati indicizzati dal livello dei metadati utilizzando il livello API. Questi possono essere sotto forma di driver di database che consentono di eseguire le query tramite codice. Oppure questi potrebbero essere esposti sotto forma di endpoint a cui è possibile accedere da qualsiasi client.
Livello di consumo dati
Questo livello comprende gli strumenti di analisi e business intelligence, che sono i principali utenti dei dati provenienti dalla Data Lakehouse. Puoi eseguire qui i tuoi programmi di machine learning per ottenere informazioni preziose dai dati che hai archiviato e indicizzato.
Quindi ora hai un quadro chiaro dell’architettura della casa sul lago. Ma come se ne costruisce uno?
Passaggi per costruire una Data Lakehouse
Diamo un’occhiata a come puoi costruire la tua casa sul lago dei dati. Che tu disponga di un data Lake o di un magazzino esistente o che tu stia costruendo una casa sul lago da zero, i passaggi rimangono simili.
Successivamente, esaminiamo come eseguire la migrazione a una Data Lakehouse se disponi di una soluzione di gestione dei dati esistente.
Passaggi per la migrazione a Data Lakehouse
Quando esegui la migrazione del carico di lavoro dei dati a una soluzione Data Lakehouse, è necessario tenere presenti alcuni passaggi. Avere un piano d’azione ti consente di evitare problemi dell’ultimo minuto.
Passaggio 1: analizzare i dati
Il passaggio iniziale e uno dei più cruciali per qualsiasi migrazione di successo è l’analisi dei dati. Con un’analisi adeguata, puoi definire l’ambito della tua migrazione. Inoltre, ti consente di identificare tutte le dipendenze aggiuntive che potresti avere. Ora hai una panoramica più ampia del tuo ambiente e di ciò di cui stai per eseguire la migrazione. Ciò ti consente di stabilire meglio le priorità delle tue attività.
Passaggio 2: preparare i dati per le migrazioni
Il passaggio successivo per una migrazione di successo è la preparazione dei dati. Ciò include i dati di cui eseguirai la migrazione, nonché i framework di dati di supporto di cui avrai bisogno. Invece di aspettare ciecamente che tutti i tuoi dati siano disponibili nella tua casa sul lago, sapere di quali set di dati e colonne hai effettivamente bisogno può farti risparmiare tempo e risorse preziose.
Passaggio 3: convertire i dati nel formato richiesto
Puoi sfruttare la conversione automatica. In effetti, dovresti preferire il più possibile gli strumenti di conversione automatica. Le conversioni dei dati durante la migrazione a Data Lakehouse possono essere complicate. Fortunatamente, la maggior parte degli strumenti include codice SQL facilmente leggibile o soluzioni low-code. Strumenti come Alchimista aiutami con questo.
Passaggio 4: convalidare i dati dopo la migrazione
Una volta completata la migrazione, è il momento di convalidare i dati. Qui, dovresti provare ad automatizzare il processo di convalida il più possibile. Altrimenti, la migrazione manuale diventa noiosa e ti rallenta. Dovrebbe essere utilizzato solo come ultima risorsa. È importante verificare che i processi aziendali e i processi relativi ai dati rimangano inalterati dopo la migrazione.
Caratteristiche principali di Data Lakehouse
🔷 Gestione completa dei dati: ottieni funzionalità di gestione dei dati che ti aiutano a ottenere il massimo dai tuoi dati. Questi includono la pulizia dei dati, il processo ETL o Extract-Transform-Load e l’applicazione dello schema. Pertanto, puoi facilmente disinfettare e preparare i tuoi dati per ulteriori analisi e strumenti di BI (Business Intelligence).
🔷 Formati di archiviazione aperti – Il formato di archiviazione in cui vengono salvati i tuoi dati è aperto e standardizzato. Ciò significa che i dati che raccogli da diverse origini dati vengono tutti archiviati in modo simile e puoi lavorarci fin dall’inizio. Supporta formati come AVRO, ORC o Parquet. Inoltre, supportano anche i formati di dati tabulari.
🔷 Separazione dello spazio di archiviazione: puoi disaccoppiare lo spazio di archiviazione dalle risorse di elaborazione. Ciò si ottiene utilizzando cluster separati per entrambi. Pertanto, puoi aumentare separatamente lo spazio di archiviazione secondo necessità senza dover apportare modifiche inutilmente alle risorse di elaborazione.
🔷 Supporto per lo streaming di dati: prendere decisioni basate sui dati spesso comporta il consumo di flussi di dati in tempo reale. Rispetto a un data warehouse standard, una data Lakehouse offre il supporto dell’acquisizione di dati in tempo reale.
🔷 Governance dei dati: supporta una governance forte. Inoltre, ottieni anche funzionalità di controllo. Questi sono particolarmente importanti per mantenere l’integrità dei dati.
🔷 Costi dei dati ridotti: il costo operativo della gestione di una data Lakehouse è comparativamente inferiore a quello di un data warehouse. Puoi ottenere l’archiviazione di oggetti nel cloud per le tue crescenti esigenze di dati a un prezzo inferiore. Inoltre, ottieni un’architettura ibrida. In questo modo è possibile eliminare la necessità di mantenere più sistemi di archiviazione dei dati.
Data Lake, Data Warehouse e Data Lakehouse
FunzionalitàData LakeData WarehouseData LakehouseArchiviazione datiArchivia dati grezzi o non strutturatiArchivia dati elaborati e strutturatiArchivia sia dati grezzi che strutturatiSchema datiNon ha uno schema fissoHa uno schema fissoUtilizza schema open source per le integrazioniTrasformazione dei datiI dati non vengono trasformatiÈ richiesto un ETL completoETL viene eseguito secondo necessitàConformità ACIDNessuna conformità ACIDACID -ConformeACID-CompliantPrestazioni delle queryIn genere più lento poiché i dati non sono strutturatiMolto veloce grazie ai dati strutturatiVeloce grazie ai dati semistrutturatiCostoL’archiviazione è convenienteCosti di archiviazione e query più elevatiCosti di archiviazione e query bilanciatiGovernance dei datiRichiede un’attenta governanceRichiede una governance forte necessariaSupporta misure di governanceAnalisi in tempo realeAnalisi in tempo reale limitataReal-limitato- analisi del tempoSupporta analisi in tempo realeCasi d’usoArchiviazione di dati, esplorazione, ML e AIRReporting e analisi tramite BISia machine learning che analisi
Conclusione
Combinando perfettamente i punti di forza dei data Lake e dei data warehouse, una Data Lake House affronta le sfide importanti che potresti incontrare nella gestione e nell’analisi dei tuoi dati.
Ora conosci le caratteristiche e l’architettura di una casa sul lago. L’importanza di una Data Lakehouse è evidente nella sua capacità di lavorare con dati strutturati e non strutturati, offrendo una piattaforma unificata per archiviazione, query e analisi. Inoltre, ottieni anche la conformità ACID.
Con i passaggi menzionati in questo articolo sulla creazione e la migrazione a una Data Lakehouse, puoi sfruttare i vantaggi di una piattaforma di gestione dei dati unificata ed economicamente vantaggiosa. Rimani aggiornato sul moderno panorama della gestione dei dati e promuovi il processo decisionale, l’analisi e la crescita aziendale basati sui dati.
Successivamente, consulta il nostro articolo dettagliato sulla replica dei dati.