
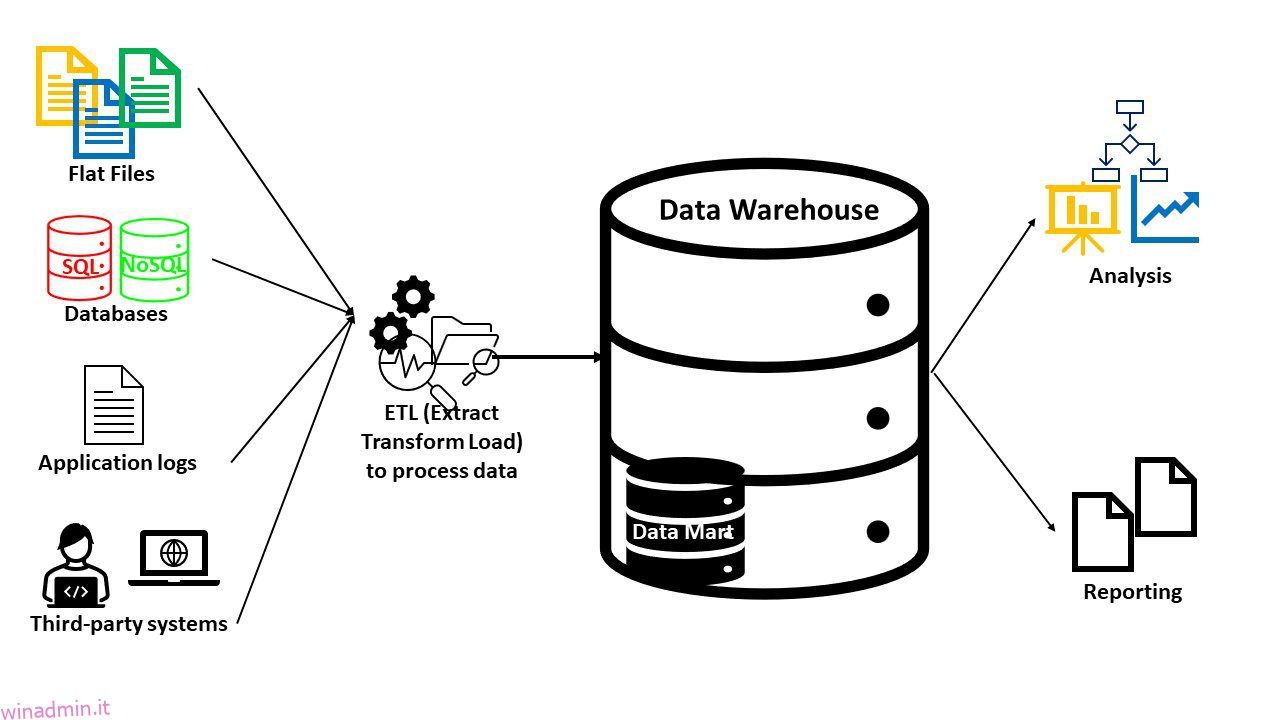
Le aziende di oggi sono incentrate sui dati. Le aziende stanno trovando modi per estrarre e analizzare in modo efficiente i dati da varie fonti e migliorare i ricavi e i profitti aziendali.
Ma qual è il posto più sicuro per archiviare e integrare i dati provenienti da più fonti e sfruttarli al meglio?
Sia i data lake che i data warehouse sono metodi popolari per gestire grandi quantità di big data. Le differenze tra loro risiedono nel modo in cui le organizzazioni acquisiscono, archiviano e utilizzano i dati. Continua a leggere per saperne di più.
Sommario:
Che cos’è un Data Lake?
Un data lake si riferisce a un repository di archiviazione centrale in cui i dati acquisiti da più origini, in qualsiasi formato (strutturato o non strutturato), vengono archiviati come ricevuti. È come un pool di dati grezzi, il cui scopo è ancora sconosciuto. Le aziende di solito archiviano dati che potrebbero essere potenzialmente utili per analisi future in un data lake.
Caratteristiche principali di un data lake:
- Contiene un mix di dati utili e non utili e quindi richiede molto spazio di archiviazione.
- Archivia i dati in tempo reale e batch, ad esempio puoi archiviare dati in tempo reale da dispositivi IoT, social media o applicazioni cloud e dati batch da database o file di dati.
- Ha un’architettura piatta.
- Poiché i dati non vengono elaborati fino a quando non sono necessari per l’analisi, devono essere governati e mantenuti correttamente; in caso contrario, può trasformarsi in paludi di dati.
Quindi, come possiamo recuperare rapidamente i dati da un repository di archiviazione così vasto e apparentemente disordinato? Bene, un data lake utilizza tag e identificatori di metadati per questo scopo!
Che cos’è un Data Warehouse?
Un repository più organizzato e strutturato: un data warehouse contiene dati pronti per l’analisi. I dati strutturati, semistrutturati o non strutturati provenienti da più origini vengono acquisiti, integrati, puliti, ordinati, trasformati e resi idonei all’uso.
Il data warehouse contiene grandi quantità di dati passati e attuali. Di solito, i dati vengono elaborati per un problema aziendale specifico (analisi). Tali informazioni vengono richieste dai sistemi di Business Intelligence (BI) per analisi, reportistica e approfondimenti.
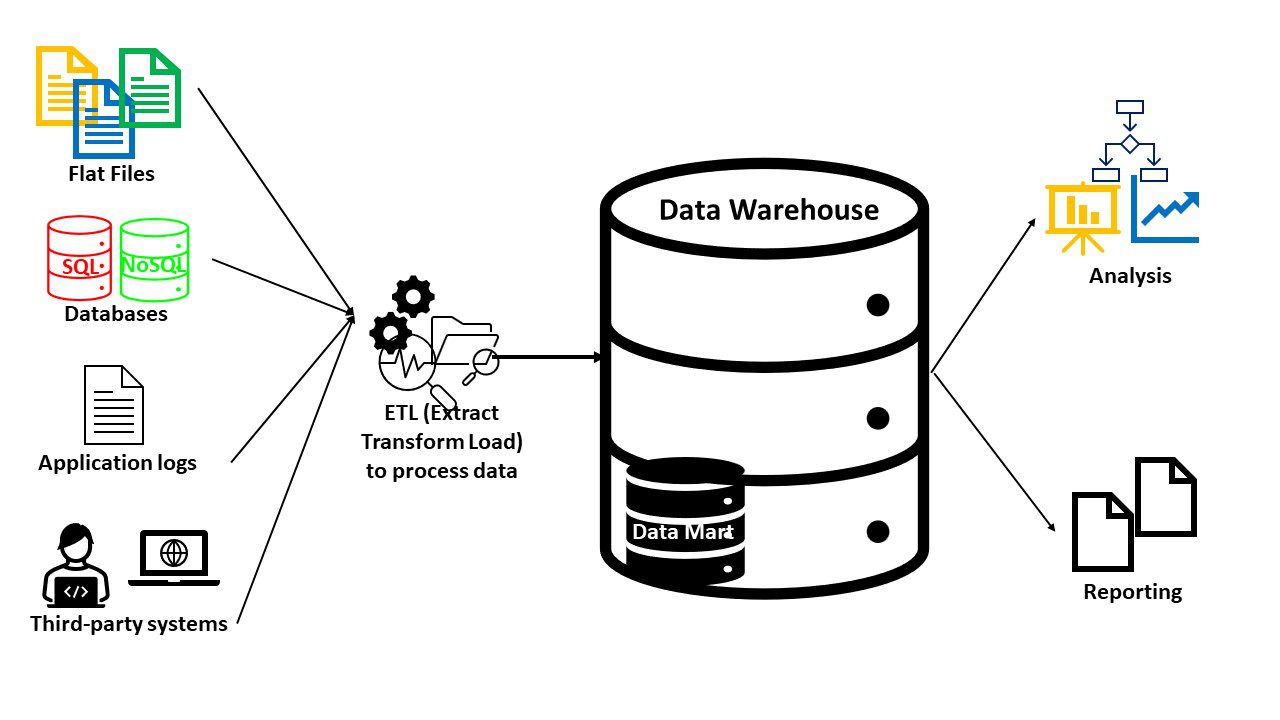
I data warehouse sono generalmente costituiti da:
- Un database (SQL o NoSQL) per archiviare e gestire i dati
- Strumenti di trasformazione e analisi dei dati per la preparazione dei dati
- Strumenti di BI per data mining, analisi statistica, reportistica e visualizzazione
Poiché i data warehouse servono a uno scopo specifico, avrai sempre dati rilevanti. Puoi anche utilizzare strumenti aggiuntivi nei data warehouse per soddisfare funzionalità avanzate come l’intelligenza artificiale e le funzionalità spaziali o grafiche. I data warehouse creati per un dominio specifico sono chiamati data mart.
Differenze chiave tra Data Lake e Data Warehouse
Per ribadire quanto letto sopra, il data lake contiene dati grezzi il cui scopo non è stato definito. Al contrario, un data warehouse contiene dati che sono pronti per l’analisi e sono già nella loro forma migliore.
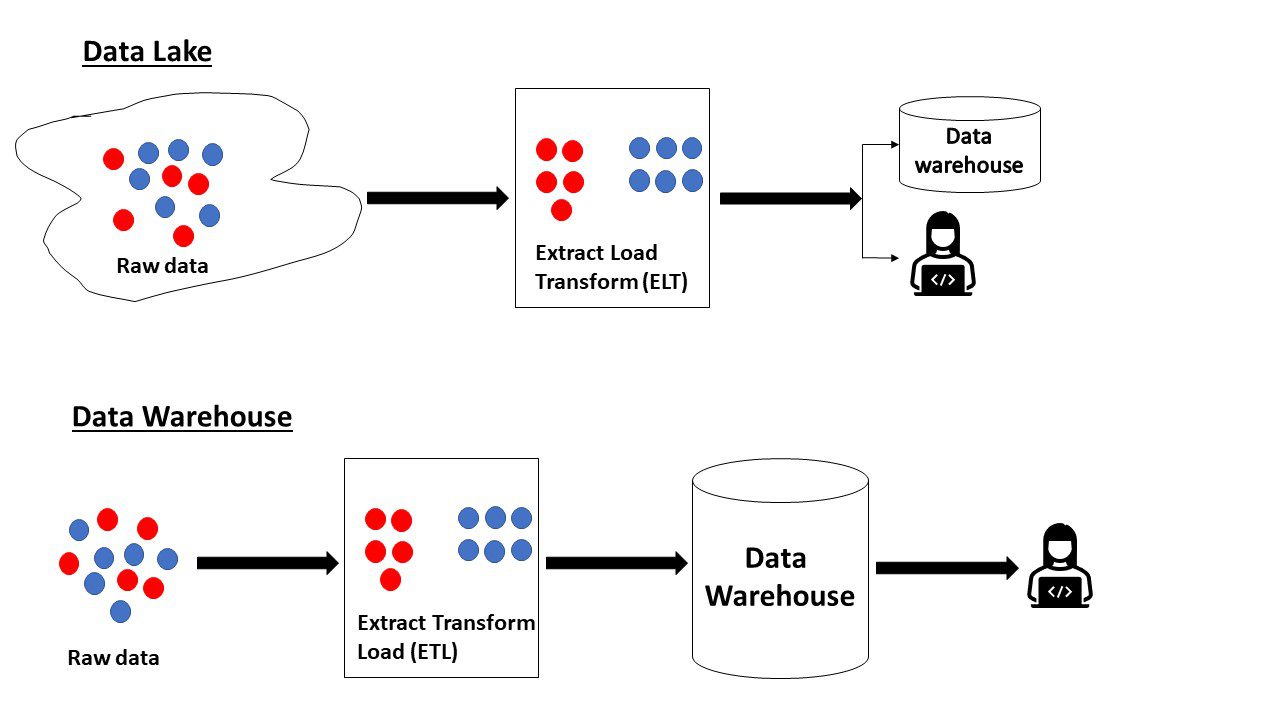 Data Lake vs Data warehouse
Data Lake vs Data warehouse
Alcune differenze tra un data lake e un data warehouse sono:
Data LakeData WarehouseI dati grezzi o elaborati in qualsiasi formato vengono acquisiti da più originiI dati vengono ottenuti da più origini per l’analisi e il reporting. È strutturatoLo schema viene creato al volo come richiesto (schema-on-read)Schema predefinito durante la scrittura nel magazzino (Schema-on-write)Nuovi dati possono essere aggiunti facilmenteI dati sono pronti dopo l’elaborazione, quindi ogni nuova modifica richiede più tempo e sforzo.I dati devono essere aggiornati e governati per essere rilevantiI dati sono già nella loro forma migliore, quindi non richiedono una manutenzione specificaSono costituiti da enormi volumi di big data (petabyte)I dati sono generalmente inferiori a quelli nel data lake (terabyte). Il data warehouse può contenere dati operativi di un’intera organizzazione, dati analitici o dati rilevanti per un particolare dominio Utilizzato dai data scientist per vari scopi come analisi di streaming, intelligenza artificiale, analisi predittiva e molti casi d’uso. Utilizzato da analisti aziendali per l’elaborazione delle transazioni ( OLTP), analisi operative (OLAP), report, creazione di visualizzazioni I dati possono essere archiviati e archiviati per un periodo prolungato per essere analizzati in qualsiasi momento. I dati devono essere eliminati frequentemente per ospitare i dati più recenti L’archiviazione è poco costosa. L’archiviazione e l’elaborazione sono costose e richiedono tempo -consumo, quindi dovrebbe essere pianificato con giudizio. I data scientist possono sviluppare nuovi problemi e soluzioni guardando i dati. La portata dei dati è limitata a un problema aziendale specifico. Poiché i dati non sono organizzati in un modo particolare, sia relazionali che non i database relazionali possono essere utilizzati per archiviare i dati. I data warehouse utilizzano in genere database relazionali perché i dati devono essere in una parti formato colare.
Casi d’uso per Data Lake e Data Warehouse
È facile pensare a un data lake come una scelta più conveniente perché è più scalabile, flessibile e tascabile. Tuttavia, un data warehouse potrebbe essere un’ottima idea quando hai bisogno di dati più pertinenti e strutturati per analisi specifiche.
Alcuni casi d’uso per data lake sono i seguenti:
# 1. Catena di fornitura e gestione
L’enorme quantità di big data nei data lake aiuta l’analisi predittiva per il trasporto e la logistica. Utilizzando i dati storici e attuali, le aziende possono pianificare le loro operazioni quotidiane senza intoppi, ispezionare i movimenti dell’inventario in tempo reale e ottimizzare i costi.
#2. Assistenza sanitaria
Il data lake contiene tutte le informazioni passate e attuali dei pazienti. Ciò è utile nella ricerca, nella ricerca di modelli, nella fornitura di un trattamento migliore e tempestivo per le malattie, nell’automazione della diagnostica e nell’ottenimento dei dettagli più aggiornati sulla salute di un paziente.
#3. Streaming di dati e IoT
I data lake possono ricevere continuamente i dati in streaming inviati alle pipeline di analisi per il reporting continuo e il rilevamento di attività e movimenti insoliti. Ciò è possibile grazie alla capacità del data lake di raccogliere dati (quasi) in tempo reale.
Alcuni casi d’uso per il data warehouse sono:
# 1. Finanza
Le informazioni finanziarie di un’azienda possono essere più adatte per un data warehouse. I dipendenti possono accedere facilmente a informazioni organizzate e strutturate sotto forma di grafici e report per gestire i processi finanziari, gestire i rischi e prendere decisioni strategiche.
#2. Marketing e segmentazione della clientela
Il data warehouse crea un’unica fonte di “verità” o dati corretti sui clienti raccolti da più fonti. Le aziende possono analizzare questi dati per comprendere i comportamenti dei clienti, offrire sconti personalizzati, segmentare i clienti in base alle loro preferenze e generare più lead.
#3. Dashboard e report aziendali
Molte aziende utilizzano data warehouse CRM ed ERP per estrarre dati su clienti esterni e interni. I dati sono sempre rilevanti e possono essere considerati affidabili per la creazione di qualsiasi tipo di report e visualizzazione.
#4. Migrazione di dati da sistemi legacy
Utilizzando le funzionalità ETL dei data warehouse, le aziende possono trasformare facilmente i dati dei sistemi legacy in un formato più utilizzabile che i nuovi sistemi possono analizzare. Ciò aiuterà le organizzazioni a ottenere informazioni dettagliate sulle tendenze storiche e a prendere decisioni aziendali accurate.
Esempi di strumenti di Data Lake
Alcuni dei principali fornitori di data lake sono:
- Microsoft Azure – Azure può archiviare e analizzare petabyte di dati. Azure semplifica il debug e l’ottimizzazione dei programmi Big Data.
- Google Cloud – Google cloud offre l’importazione, l’archiviazione e l’analisi a costi contenuti di enormi volumi di big data di qualsiasi tipo. Si integra inoltre con strumenti di analisi come Apache Spark, BigQuery e altri acceleratori di analisi.
- Atlante MongoDB – Atlas data lake è un data lake store completamente gestito. Fornisce modi convenienti per archiviare dati su larga scala e può eseguire query ad alte prestazioni che utilizzano meno potenza di elaborazione, risparmiando così tempo e costi.
- Amazon S3 – Il cloud AWS fornisce gli strumenti necessari per creare un data lake flessibile, sicuro ed economico. Dispone di una console interattiva per gestire gli utenti del data lake e controllare l’accesso agli utenti.
Esempi di strumenti di Data Warehouse
Alcuni dei principali fornitori di soluzioni di data warehouse sono:
- LINFA – Il data warehouse SAP consente agli utenti di accedere semanticamente a dati avanzati da più origini. Le aziende possono condividere in modo sicuro informazioni e modelli, accelerare il processo decisionale e combinare in modo sicuro dati esterni e interni.
- ClicData – Il data warehouse intelligente e integrato di ClicData garantisce l’integrità dei dati, la qualità e la facilità di reporting. ClicData offre sia sistemi di pianificazione che API in tempo reale in modo da poter ottenere dati aggiornati in ogni momento.
- Amazon Redshift – Uno dei data warehouse più utilizzati, Redshift utilizza SQL per analizzare tutti i tipi di dati presenti in vari database, laghi o altri warehouse. Offre un ottimo equilibrio tra costi e prestazioni.
- Magazzino IBM Db2 – IBM fornisce soluzioni di data warehousing interne, cloud e integrate. Integra inoltre strumenti di machine learning e intelligenza artificiale per un’analisi più approfondita dei dati e condivide un motore SQL comune per semplificare le query.
- Data warehouse Oracle Cloud – Oracle utilizza un database in memoria e offre funzionalità grafiche, di apprendimento automatico e spaziali per approfondire i dati per un’analisi dei dati più rapida ma più ricca.
Parole finali
Sia i data lake che i data warehouse hanno i loro vantaggi e casi d’uso ideali. Mentre i data lake sono più scalabili e flessibili, i data warehouse hanno sempre informazioni affidabili e strutturate. L’implementazione del data lake è relativamente nuova, mentre il data warehouse è un concetto consolidato utilizzato da molte organizzazioni per gestire in modo efficiente i propri dati interni ed esterni.