

Google JAX o Just After Execution è un framework sviluppato da Google per velocizzare le attività di machine learning.
Puoi considerarla una libreria per Python, che aiuta nell’esecuzione più rapida delle attività, nell’elaborazione scientifica, nelle trasformazioni delle funzioni, nell’apprendimento profondo, nelle reti neurali e molto altro.
Sommario:
Informazioni su Google JAX
Il pacchetto di calcolo più fondamentale in Python è il pacchetto NumPy che ha tutte le funzioni come aggregazioni, operazioni vettoriali, algebra lineare, array n-dimensionali e manipolazioni di matrici e molte altre funzioni avanzate.
E se potessimo accelerare ulteriormente i calcoli eseguiti utilizzando NumPy, in particolare per enormi set di dati?
Abbiamo qualcosa che potrebbe funzionare ugualmente bene su diversi tipi di processori come GPU o TPU, senza modifiche al codice?
Che ne dici se il sistema potesse eseguire trasformazioni di funzioni componibili automaticamente e in modo più efficiente?
Google JAX è una libreria (o framework, come dice Wikipedia) che fa proprio questo e forse molto di più. È stato creato per ottimizzare le prestazioni ed eseguire in modo efficiente attività di machine learning (ML) e deep learning. Google JAX fornisce le seguenti funzionalità di trasformazione che lo rendono unico rispetto ad altre librerie ML e aiutano nel calcolo scientifico avanzato per il deep learning e le reti neurali:
- Differenziazione automatica
- Vettorizzazione automatica
- Parallelizzazione automatica
- Compilazione just-in-time (JIT).
Le caratteristiche uniche di Google JAX
Tutte le trasformazioni utilizzano XLA (Accelerated Linear Algebra) per prestazioni più elevate e ottimizzazione della memoria. XLA è un motore del compilatore di ottimizzazione specifico del dominio che esegue l’algebra lineare e accelera i modelli TensorFlow. L’utilizzo di XLA sul codice Python non richiede modifiche significative al codice!
Esploriamo in dettaglio ciascuna di queste caratteristiche.
Funzionalità di Google JAX
Google JAX viene fornito con importanti funzioni di trasformazione componibile per migliorare le prestazioni ed eseguire attività di deep learning in modo più efficiente. Ad esempio, la differenziazione automatica per ottenere il gradiente di una funzione e trovare derivate di qualsiasi ordine. Allo stesso modo, parallelizzazione automatica e JIT per eseguire più attività in parallelo. Queste trasformazioni sono fondamentali per applicazioni come la robotica, i giochi e persino la ricerca.
Una funzione di trasformazione componibile è una funzione pura che trasforma un insieme di dati in un’altra forma. Sono chiamate componibili in quanto sono autonome (cioè, queste funzioni non hanno dipendenze con il resto del programma) e sono stateless (cioè, lo stesso input risulterà sempre nello stesso output).
Y(x) = T: (f(x))
Nell’equazione precedente, f(x) è la funzione originale su cui viene applicata una trasformazione. Y(x) è la funzione risultante dopo l’applicazione della trasformazione.
Ad esempio, se hai una funzione denominata ‘total_bill_amt’ e desideri il risultato come una trasformazione di funzione, puoi semplicemente utilizzare la trasformazione che desideri, diciamo gradiente (grad):
grad_total_bill = grad(total_bill_amt)
Trasformando le funzioni numeriche utilizzando funzioni come grad(), possiamo facilmente ottenere i loro derivati di ordine superiore, che possiamo utilizzare ampiamente negli algoritmi di ottimizzazione del deep learning come la discesa del gradiente, rendendo così gli algoritmi più veloci ed efficienti. Allo stesso modo, usando jit(), possiamo compilare programmi Python just-in-time (pigramente).
# 1. Differenziazione automatica
Python utilizza la funzione autograd per differenziare automaticamente NumPy e il codice Python nativo. JAX utilizza una versione modificata di autograd (cioè, grad) e combina XLA (Accelerated Linear Algebra) per eseguire la differenziazione automatica e trovare derivati di qualsiasi ordine per GPU (Graphic Processing Units) e TPU (Tensor Processing Unit).]
Nota rapida su TPU, GPU e CPU: CPU o Central Processing Unit gestiscono tutte le operazioni sul computer. La GPU è un processore aggiuntivo che migliora la potenza di calcolo ed esegue operazioni di fascia alta. TPU è una potente unità sviluppata specificamente per carichi di lavoro complessi e pesanti come l’IA e gli algoritmi di deep learning.
Sulla stessa linea della funzione autograd, che può differenziare attraverso loop, ricorsioni, rami e così via, JAX usa la funzione grad() per gradienti in modalità inversa (backpropagation). Inoltre, possiamo differenziare una funzione in qualsiasi ordine usando grad:
grad(grad(grad(sin θ))) (1.0)
Differenziazione automatica di ordine superiore
Come accennato in precedenza, grad è abbastanza utile per trovare le derivate parziali di una funzione. Possiamo utilizzare una derivata parziale per calcolare la discesa del gradiente di una funzione di costo rispetto ai parametri della rete neurale nel deep learning per ridurre al minimo le perdite.
Calcolo della derivata parziale
Supponiamo che una funzione abbia più variabili, x, yez. Trovare la derivata di una variabile mantenendo costanti le altre variabili è chiamata derivata parziale. Supponiamo di avere una funzione,
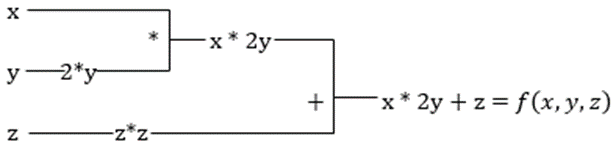
f(x,y,z) = x + 2y + z2
Esempio per mostrare la derivata parziale
La derivata parziale di x sarà ∂f/∂x, che ci dice come una funzione cambia per una variabile quando le altre sono costanti. Se lo eseguiamo manualmente, dobbiamo scrivere un programma per differenziare, applicarlo per ogni variabile e quindi calcolare la discesa del gradiente. Questo diventerebbe un affare complesso e dispendioso in termini di tempo per più variabili.
La differenziazione automatica scompone la funzione in un insieme di operazioni elementari, come +, -, *, / o sin, cos, tan, exp, ecc., quindi applica la regola della catena per calcolare la derivata. Possiamo farlo sia in modalità avanti che indietro.
Non è questo! Tutti questi calcoli avvengono così velocemente (beh, pensa a un milione di calcoli simili a quelli precedenti e al tempo che potrebbe richiedere!). XLA si prende cura della velocità e delle prestazioni.
#2. Algebra lineare accelerata
Prendiamo l’equazione precedente. Senza XLA, il calcolo richiederà tre (o più) kernel, in cui ogni kernel eseguirà un’attività più piccola. Per esempio,
Kernel k1 –> x * 2y (moltiplicazione)
k2 –> x * 2y + z (aggiunta)
k3 –> Riduzione
Se la stessa attività viene eseguita dall’XLA, un singolo kernel si occupa di tutte le operazioni intermedie fondendole. I risultati intermedi delle operazioni elementari vengono trasmessi in streaming invece di archiviarli in memoria, risparmiando così memoria e aumentando la velocità.
#3. Compilazione just-in-time
JAX utilizza internamente il compilatore XLA per aumentare la velocità di esecuzione. XLA può aumentare la velocità di CPU, GPU e TPU. Tutto questo è possibile utilizzando l’esecuzione del codice JIT. Per usarlo, possiamo usare jit tramite import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Un altro modo è decorare jit sulla definizione della funzione:
@jit def my_function(x): …………some lines of code
Questo codice è molto più veloce perché la trasformazione restituirà la versione compilata del codice al chiamante anziché utilizzare l’interprete Python. Ciò è particolarmente utile per input vettoriali, come array e matrici.
Lo stesso vale anche per tutte le funzioni Python esistenti. Ad esempio, le funzioni del pacchetto NumPy. In questo caso, dovremmo importare jax.numpy come jnp anziché NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Una volta eseguita questa operazione, l’oggetto array JAX principale chiamato DeviceArray sostituisce l’array NumPy standard. DeviceArray è pigro: i valori vengono mantenuti nell’acceleratore fino a quando non sono necessari. Ciò significa anche che il programma JAX non attende che i risultati tornino al programma chiamante (Python), a seguito di un invio asincrono.
#4. Vettorizzazione automatica (vmap)
In un tipico mondo di machine learning, abbiamo set di dati con un milione o più punti dati. Molto probabilmente, eseguiremmo alcuni calcoli o manipolazioni su ciascuno o sulla maggior parte di questi punti dati, il che è un compito che richiede molto tempo e memoria! Ad esempio, se vuoi trovare il quadrato di ciascuno dei punti dati nel set di dati, la prima cosa a cui dovresti pensare è creare un ciclo e prendere il quadrato uno per uno – argh!
Se creiamo questi punti come vettori, potremmo fare tutti i quadrati in una volta eseguendo manipolazioni di vettori o matrici sui punti dati con il nostro NumPy preferito. E se il tuo programma potesse farlo automaticamente, puoi chiedere di più? Questo è esattamente ciò che fa JAX! Può vettorizzare automaticamente tutti i tuoi punti dati in modo da poter eseguire facilmente qualsiasi operazione su di essi, rendendo i tuoi algoritmi molto più veloci ed efficienti.
JAX utilizza la funzione vmap per la vettorizzazione automatica. Considera la seguente matrice:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Facendo solo quanto sopra, il metodo quadrato verrà eseguito per ogni punto nell’array. Ma se fai quanto segue:
vmap(jnp.square(x))
Il metodo square verrà eseguito solo una volta perché i punti dati vengono ora vettorizzati automaticamente utilizzando il metodo vmap prima di eseguire la funzione e il looping viene spinto al livello elementare di operazione, risultando in una moltiplicazione di matrice anziché scalare, offrendo così prestazioni migliori .
#5. Programmazione SPMD (pmap)
SPMD – o la programmazione di dati multipli a programma singolo è essenziale nei contesti di deep learning – spesso applicheresti le stesse funzioni a diversi set di dati che risiedono su più GPU o TPU. JAX ha una funzione denominata pump, che consente la programmazione parallela su più GPU o qualsiasi acceleratore. Come JIT, i programmi che utilizzano pmap verranno compilati dall’XLA ed eseguiti simultaneamente su tutti i sistemi. Questa parallelizzazione automatica funziona sia per i calcoli in avanti che per quelli inversi.
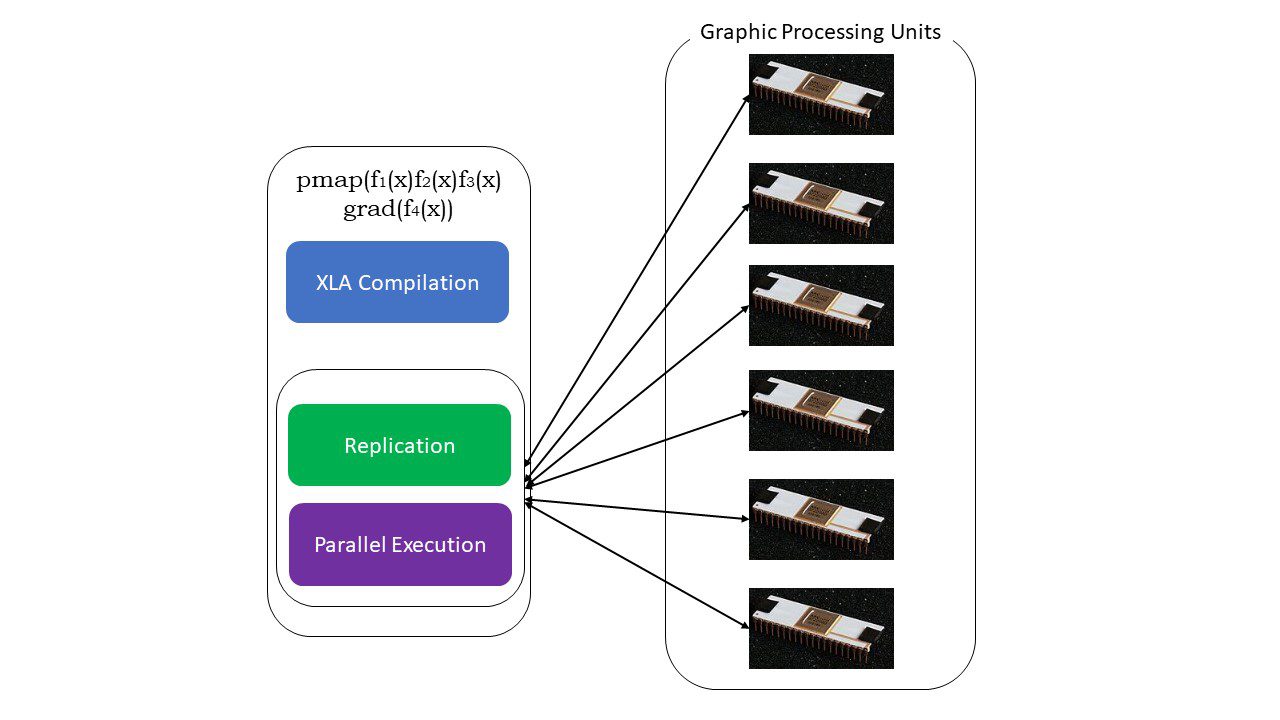 Come funziona pmap
Come funziona pmap
Possiamo anche applicare più trasformazioni in una volta sola in qualsiasi ordine su qualsiasi funzione come:
pmap(vmap(jit(grad (f(x))))))
Molteplici trasformazioni componibili
Limitazioni di Google JAX
Gli sviluppatori di Google JAX hanno pensato bene di velocizzare gli algoritmi di deep learning introducendo tutte queste fantastiche trasformazioni. Le funzioni e i pacchetti di calcolo scientifico sono sulla falsariga di NumPy, quindi non devi preoccuparti della curva di apprendimento. Tuttavia, JAX ha le seguenti limitazioni:
- Google JAX è ancora nelle prime fasi di sviluppo e, sebbene il suo scopo principale sia l’ottimizzazione delle prestazioni, non offre molti vantaggi per l’elaborazione della CPU. NumPy sembra funzionare meglio e l’utilizzo di JAX può solo aumentare il sovraccarico.
- JAX è ancora nella sua ricerca o nelle prime fasi e necessita di una messa a punto più fine per raggiungere gli standard infrastrutturali di framework come TensorFlow, che sono più consolidati e hanno modelli più predefiniti, progetti open source e materiale di apprendimento.
- A partire da ora, JAX non supporta il sistema operativo Windows: avresti bisogno di una macchina virtuale per farlo funzionare.
- JAX funziona solo su funzioni pure, quelle che non hanno effetti collaterali. Per le funzioni con effetti collaterali, JAX potrebbe non essere una buona opzione.
Come installare JAX nel tuo ambiente Python
Se hai installato Python sul tuo sistema e desideri eseguire JAX sulla tua macchina locale (CPU), usa i seguenti comandi:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Se desideri eseguire Google JAX su una GPU o TPU, segui le istruzioni fornite GitHub JAX pagina. Per configurare Python, visita il download ufficiali python pagina.
Conclusione
Google JAX è ottimo per scrivere algoritmi di deep learning, robotica e ricerca efficienti. Nonostante le limitazioni, viene ampiamente utilizzato con altri framework come Haiku, Flax e molti altri. Sarai in grado di apprezzare ciò che JAX fa quando esegui programmi e vedere le differenze di tempo nell’esecuzione del codice con e senza JAX. Puoi iniziare leggendo il documentazione ufficiale di Google JAXche è abbastanza completo.