

Quando diciamo elaborazione “serverless”, molti presumono che non ci sia un server in questo modello per facilitare l’esecuzione del codice e altre attività di sviluppo. È un chiaro malinteso.
Quindi, dopo questo mito sfatato, potresti pensare quale sia la logica dietro il nome “serverless”.
Lascia che ti dia un suggerimento: invece di “nessun server”, è COME i server sono gestiti e implementati è ciò che comporta “Serverless”.
Sembra confuso?
Bene, impareremo tutto sul serverless e altri termini ad esso correlati per chiarire i tuoi dubbi. Per cominciare, il serverless sta diventando famoso mentre parliamo. In effetti, è probabile che il mercato serverless raggiunga 7,7 miliardi di dollari entro il 2021 da $ 1,9 miliardi nel 2016.
Quindi, discutiamo di serverless e proviamo a capire il motivo della sua popolarità.
Sommario:
Che cos’è l’elaborazione senza server?
L’elaborazione senza server o senza server è un modello di esecuzione basato su cloud in cui i fornitori di servizi cloud forniscono risorse della macchina su richiesta e gestiscono i server da soli invece che da clienti o sviluppatori. È un modo che combina servizi, strategie e pratiche per aiutare gli sviluppatori a creare app basate su cloud, consentendo loro di concentrarsi sul proprio codice piuttosto che sulla gestione del server.
Dall’allocazione delle risorse, pianificazione della capacità, gestione, configurazioni e ridimensionamento a patch, aggiornamenti, programmazione e manutenzione, il provider di servizi cloud (come AWS o Google Cloud Platform) si assume tutta la responsabilità della gestione delle attività comuni dell’infrastruttura. Di conseguenza, gli sviluppatori possono concentrare i loro sforzi e il loro tempo sulla logica aziendale per i loro processi e applicazioni.
Questa architettura di elaborazione senza server non conserva mai le risorse di elaborazione nella memoria volatile; invece, l’elaborazione avviene in brevi parti. Supponiamo che tu non stia utilizzando un’applicazione, ad essa non verranno allocate risorse. Pertanto, stai pagando per quale risorsa consumi effettivamente sulle app.
L’obiettivo principale alla base della creazione del modello serverless è semplificare il processo di distribuzione del codice in produzione. Molte volte funziona anche con stili tradizionali come i microservizi. Una volta implementato il serverless, le applicazioni che alimenta iniziano a rispondere alle richieste rapidamente e aumentano o diminuiscono automaticamente in base alle esigenze.
L’elaborazione serverless utilizza un modello basato sugli eventi per determinare i requisiti di scalabilità. Pertanto, gli sviluppatori non devono più anticipare l’utilizzo di un’applicazione per decidere quanti server o larghezza di banda richiedono. Puoi richiedere più server e larghezza di banda in base alle tue crescenti esigenze senza prenotazione preventiva o ridimensionare in qualsiasi momento senza problemi.
Come si è evoluto il serverless?
Il sistema tradizionale presentava problemi associati alla scalabilità e all’agilità nel processo di sviluppo e distribuzione delle app. Con l’aumento della domanda di app di alta qualità con un rapido time-to-market, è emersa la necessità di un sistema migliore in grado di offrire maggiore scalabilità e agilità. Ha portato all’evoluzione del cloud computing e dei modelli serverless.
Il modello Serverless si è evoluto in varie fasi, dal monolitico ai microservizi fino all’architettura serverless o Function-as-a-Service (FaaS).
- L’architettura monolitica è un approccio unificato tradizionale per lo sviluppo del software. È un modello strettamente accoppiato in cui ogni componente e i suoi sottocomponenti compilano o eseguono codice. Se un servizio è difettoso, l’intero server delle applicazioni ei servizi in esecuzione su di esso possono andare in tilt.
- L’architettura dei microservizi è una raccolta di servizi più piccoli all’interno di una singola applicazione di grandi dimensioni distribuita in modo indipendente per eseguire una funzione specifica. Consente la distribuzione rapida di app su larga scala, fornendo agli sviluppatori flessibilità utilizzando Infrastructure-as-a-Service (IaaS) e Platform as a Service (PaaS). Tuttavia, la scelta tra PaaS e IaaS è impegnativa in questo modello.
- L’architettura serverless si è evoluta con il cloud computing e offre maggiore scalabilità e agilità aziendale. Invece di IaaS e PaaS, utilizza FaaS e Backend-as-a-Service (BaaS). Qui, le app vengono distribuite secondo necessità, insieme alle relative risorse. Non devi gestire il server e puoi smettere di pagare se l’esecuzione del codice termina.
Attributi dell’elaborazione senza server
Alcuni degli attributi dell’elaborazione senza server sono i seguenti:
- La maggior parte delle applicazioni che utilizzano serverless comprendono singole funzioni e piccole unità di codice.
- Esegue il codice solo su richiesta, generalmente in un contenitore software senza stato, e si ridimensiona senza problemi in base alla domanda.
- Non è necessaria alcuna gestione del server da parte dei clienti.
- Presenta l’esecuzione basata su eventi in cui l’ambiente informatico viene creato una volta attivata una funzione o ricevuto un evento per eseguire la richiesta.
- Scalabilità flessibile in modo da poter scalare facilmente verso l’alto o verso il basso. Una volta eseguito un codice, l’infrastruttura smette di funzionare e il costo viene risparmiato. Analogamente, quando la funzione continua a essere eseguita, è possibile eseguire il ridimensionamento all’infinito in base alle esigenze.
- Puoi utilizzare i servizi cloud gestiti per gestire attività complesse come l’archiviazione di file, l’accodamento, i database e altro ancora.
Come funziona senza server?
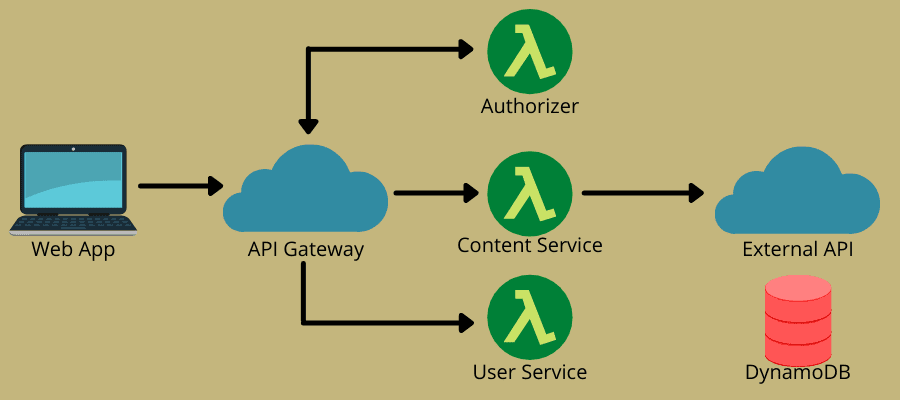
L’architettura serverless combina due idee principali: Function-as-a-Service (FaaS) e Backend-as-a-Service (BaaS). Si basa maggiormente su FaaS, che consente ai servizi cloud di eseguire il codice senza la necessità di istanze con provisioning completo. FaaS è costituito da funzioni stateless, guidate da eventi, scalabili e lato server che i servizi cloud gestiscono completamente.
Il modello consente ai team DevOps di scrivere codice incentrato sulla loro logica di business. Successivamente, definiscono un evento che può attivare la funzione, come le richieste HTTP, per l’esecuzione. Di conseguenza, il provider cloud esegue la funzione e invia i risultati alle app che gli utenti possono visualizzare.
In questo modo, il modello serverless offre convenienza e convenienza con funzionalità di scalabilità automatica, on-demand e pay-as-you-go. Pertanto, molte aziende e team DevOps stanno diventando serverless in questi giorni.
Chi utilizza Serverless e perché?
Serverless è tra le tecnologie più emergenti nello sviluppo software. Potrebbe eliminare le esigenze di gestione dell’infrastruttura e di provisioning in futuro.
È utile per:
- Le organizzazioni che desiderano maggiore scalabilità e flessibilità con una migliore testabilità delle app possono passare al serverless.
- Sviluppatori che desiderano ridurre il time-to-market creando app agili e ad alte prestazioni
- Aziende che non hanno bisogno che i loro server siano sempre in funzione. Possono chiamare funzioni basate su moduli utilizzando le applicazioni, quando richiesto, per risparmiare sui costi.
- Organizzazioni che desiderano creare app basate su cloud efficienti e semplificare la migrazione al cloud
- Lo sviluppatore alla ricerca di modi per ridurre la latenza può offrire agli utenti l’accesso ad alcune funzioni o app.
- Un’azienda che non dispone di risorse sufficienti per gestire la manutenzione e la complessità dell’infrastruttura IT può optare per l’elaborazione serverless per risolvere automaticamente i problemi e non necessita di manutenzione da parte loro.
Alcuni utenti importanti del modello serverless sono Slack, Coca-Cola, NetFlix, ecc.
Grazie ai suoi attributi unici, il modello serverless è adatto a molti casi d’uso, come:
- Applicazioni Web: puoi creare applicazioni Web rapide e scalabili utilizzando questo modello che risponde rapidamente alle richieste degli utenti. È ideale per la creazione di app stateless che possono essere avviate all’istante e app in grado di soddisfare picchi imprevedibili e poco frequenti nelle richieste degli utenti.
- Back-end API: nelle piattaforme serverless, qualsiasi funzione può essere facilmente trasformata in endpoint HTTP pronti per l’uso da parte dei client. Queste funzioni o azioni sono note come azioni web quando abilitate sul web. E una volta che questi sono abilitati, l’assemblaggio delle funzioni in un’API completa diventa facile. Puoi anche utilizzare un gateway API decente per offrire maggiore sicurezza, supporto del dominio, limitazione della velocità e supporto OAuth.
- Microservizi: Serverless è ampiamente utilizzato nel modello di microservizi che si concentra sulla creazione di piccoli servizi in grado di eseguire una singola funzione e comunicare tra loro tramite API.
Sebbene sia possibile creare microservizi utilizzando contenitori software e PaaS, il serverless è più efficiente. Facilita righe di codice più piccole che eseguono una cosa e offrono provisioning rapido, scalabilità automatica e prezzi flessibili che non addebitano costi ai clienti quando le risorse non sono in uso. - Elaborazione dei dati: Serverless è ottimo per lavorare con dati contenenti video, audio, immagini e testo strutturato. È anche favorevole per varie attività come la convalida dei dati, la trasformazione, l’arricchimento, la pulizia, la normalizzazione dell’audio e l’elaborazione di PDF. Puoi sfruttarlo per l’elaborazione delle immagini che include nitidezza, rotazione, generazione di miniature, riduzione del rumore. Altri usi del serverless nell’elaborazione dei dati possono essere la transcodifica video e il riconoscimento ottico dei caratteri (OCR).
- Elaborazione di flussi/batch: puoi creare potenti app di streaming e pipeline di dati utilizzando FaaS e un database con Apache Kafka. Il modello serverless si adatta a diverse acquisizioni di flussi, inclusi i dati per i registri delle app, i sensori IoT, la logica aziendale e il mercato finanziario.
- Calcolo parallelo: Serverless è eccellente per le attività relative al calcolo parallelo, in cui ogni attività viene eseguita in parallelo per eseguire un’attività specifica. Può includere la ricerca dei dati, l’elaborazione, le operazioni sulle mappe, il web scraping, l’elaborazione del genoma, l’ottimizzazione degli iperparametri, ecc.
- Altri usi: il serverless viene utilizzato anche per varie applicazioni, come la gestione delle relazioni con i clienti (CRM), la finanza, i chatbot, la business intelligence e l’analisi, solo per citarne alcuni.
Nota: Serverless potrebbe non essere l’ideale per alcuni casi. Ad esempio, app di grandi dimensioni con carichi di lavoro prevedibili e quasi costanti potrebbero trarre maggiori vantaggi da un’architettura di sistema tradizionale. Possono scegliere server dedicati, gestiti o autogestiti. Inoltre, se la tua organizzazione dispone di configurazioni tradizionali complete con sistemi e applicazioni legacy, potrebbe essere costoso e impegnativo passare a un’architettura completamente nuova e diversa.
Vantaggi e svantaggi dell’elaborazione senza server
Ogni moneta ha due facce, così come l’architettura serverless. Presenta anche alcuni vantaggi e svantaggi basati su diversi parametri. Quindi, prima di andare avanti, è importante conoscere entrambe le parti per decidere se sarebbe meglio per la tua organizzazione o meno.
Vantaggi 👍
Ecco alcuni dei vantaggi dell’architettura serverless:
Costo efficiente
Serverless può offrire una maggiore efficienza in termini di costi rispetto all’acquisto o al noleggio di server in cui si pagano le risorse anche se non le si utilizza.
Serverless utilizza un modello pay-as-you-go in cui pagherai solo per le risorse che consumi. Il provider serverless ti addebiterà solo la memoria allocata e il tempo per eseguire il codice senza incorrere in costi per i tempi di inattività.
Di conseguenza, risparmierai sui costi operativi per attività come l’installazione, le licenze, la manutenzione, l’applicazione di patch, il supporto, ecc. Senza hardware del server, risparmi sui costi di manodopera.
Scalabilità
I sistemi serverless offrono un elevato livello di scalabilità in quanto è possibile aumentare o diminuire le dimensioni quando lo si desidera in base alle richieste. Per questo motivo sono detti anche “elastici”.
Qui, gli sviluppatori non hanno bisogno di tempo dedicato per impostare i sistemi o le policy di scalabilità automatica o per ottimizzarli. Il fornitore di servizi cloud che hai scelto è responsabile della gestione di tutto ciò. Inoltre, gli sviluppatori di piccoli team possono anche eseguire il proprio codice da soli senza richiedere ingegneri di supporto o infrastruttura.
Latenza ridotta
Poiché le app non sono ospitate su un singolo server di origine, puoi eseguire il codice da qualsiasi luogo. Se il provider cloud che hai scelto lo supporta, puoi eseguire le funzioni dell’app su un server vicino agli utenti finali. Pertanto, subisce una minore latenza a causa della ridotta distanza tra le richieste dell’utente e il server.
Produttività
Il modello serverless aiuta a migliorare la produttività dei tuoi sviluppatori in quanto non devono gestire la gestione del server. Inoltre, non devono pensare direttamente alla gestione delle richieste HTTP o al multithreading nel loro codice.
Di conseguenza, semplifica lo sviluppo back-end, tutto grazie a FaaS, in cui il codice esposto è costituito da funzioni guidate da eventi. Tutti questi risparmiano il tempo che possono dedicare al miglioramento del codice e dell’applicazione.
Distribuzione dell’app più rapida
Con serverless, gli sviluppatori non eseguono la configurazione back-end o caricano il codice sul server per distribuire una versione dell’app. Possono anche caricare rapidamente il codice in bit per rilasciare nuovi prodotti.
Hanno anche la flessibilità di distribuire il codice contemporaneamente o di funzionare uno dopo l’altro poiché non è un’architettura monolitica. Inoltre, puoi correggere, aggiornare, aggiungere funzionalità o correggere rapidamente gli errori da un’app.
Altri vantaggi includono il green computing grazie al ridotto consumo energetico con server on-demand, la creazione di un’app che diventa più semplice con integrazioni integrate, un time-to-market più rapido e altro ancora.
Svantaggi 👎
Ora, diamo un’occhiata agli svantaggi dell’elaborazione senza server:
Prestazione
A volte, il codice serverless utilizzato meno frequentemente può presentare una maggiore latenza di risposta rispetto a quelli in esecuzione continua su server dedicati, contenitori software o macchine virtuali (VM). È perché potrebbe essere necessario più tempo per ricominciare e creare ulteriore latenza.
Difficile da eseguire il debug e testare
Devi sapere come si comporta il tuo codice una volta distribuito. Per questo, è necessario testarlo, il che è impegnativo in un ambiente senza server. Inoltre, poiché gli sviluppatori non hanno visibilità su ogni processo di back-end e le app sono suddivise in funzioni più piccole, il debug diventa complicato.
Problemi di sicurezza
Stanno crescendo nuovi e avanzati problemi di sicurezza informatica. Tuttavia, non è possibile conoscere o misurare completamente la sicurezza del fornitore di servizi cloud. Quindi, quando gestiscono l’intero back-end con dati sensibili archiviati nelle applicazioni, è rischioso.
Non adatto a processi applicativi di lunga durata
Serverless è conveniente, ma non per tutti i tipi di applicazioni. Se si dispone di un’applicazione con processi a esecuzione prolungata, il costo della sua esecuzione in base al tempo e alle risorse allocate può essere molto elevato. In questo momento, potresti voler andare avanti con un server di hosting dedicato.
Altri svantaggi del serverless sono la difficoltà nel passare da un fornitore all’altro e i problemi di privacy.
Terminologie importanti nell’architettura serverless
Serverless non è mai completo senza parlare di alcune terminologie chiave ad esso correlate. FaaS e BaaS sono due delle idee più importanti che hanno portato all’evoluzione del serverless che conosciamo oggi. E per costruire un sistema serverless, hai bisogno di un database, un sistema di archiviazione, uno stack tecnologico, un framework e così via. Quindi, discutiamo un po’ di loro.
Funzione come servizio (FaaS)
FaaS è un’idea centrale in serverless e funziona come il suo sottoinsieme. Questo modello di esecuzione del codice basato su eventi (app in esecuzione in risposta a una richiesta) consente di scrivere logica distribuita in contenitori software, eseguita su richiesta e gestita da una piattaforma cloud.
Se lo confronti con BaaS, FaaS offre un maggiore controllo agli sviluppatori nella creazione di app personalizzate invece di dipendere da librerie contenenti codice prefabbricato.
I contenitori software in cui viene distribuito il codice sono senza stato per semplificare l’integrazione dei dati e il codice viene eseguito per un tempo più breve. Inoltre, gli sviluppatori possono richiamare applicazioni serverless tramite API utilizzando FaaS che i fornitori di servizi cloud gestiscono tramite un gateway API.
Back-end come servizio (BaaS)
BaaS è simile a FaaS perché entrambi necessitano di un fornitore di servizi di terze parti. In questo modello, un fornitore di servizi cloud fornisce servizi di back-end come l’archiviazione dei dati per aiutare gli sviluppatori a concentrarsi sulla scrittura del codice di front-end. Tuttavia, le applicazioni BaaS potrebbero non essere guidate da eventi o eseguite sull’edge come con le app serverless.
Un buon esempio per BaaS è AWS Lambda. Gli sviluppatori utilizzano codice serverless in contenitori con Lambda che fornisce linee guida da seguire durante l’invio del codice. Automatizza inoltre i processi di inserimento del codice nei contenitori software e offre un servizio gestito.
Pila senza server
Come con altre tecnologie software, anche l’architettura serverless viene fornita con uno stack tecnologico. Riunisce vari componenti essenziali per creare un sistema o un’applicazione serverless.
Lo stack senza server include:
- Un linguaggio di programmazione: il linguaggio di programmazione in cui gli sviluppatori scriveranno il codice. A seconda del fornitore, puoi scegliere tra Java, JavaScript, Python, C#, Go, Node.js, F#, ecc.
- Un framework serverless: un framework fornisce lo scheletro o la struttura al codice. Ci sono molti framework Serverless per iniziare. Consente la creazione, il confezionamento e la compilazione del codice e infine l’implementazione nel cloud. I framework serverless accelerano il processo di codifica e semplificano la scalabilità con tempi di configurazione ridotti. Esempi di framework server sono Apex, AWS Serverless Application Model, ecc.
- Database serverless: vengono utilizzati per archiviare i dati a cui il codice richiede l’accesso. Sono inoltre necessari per interagire con le funzioni per i trigger. Questi database si comportano come funzioni senza server ma memorizzano i dati a tempo indeterminato. Esempi di database serverless sono DynamoDB, Azure Cosmos DB, Aurora Serverless e Cloud Firestore.
- Una serie di trigger: aiutano ad avviare l’esecuzione del codice come le richieste HTTP
- Contenitori software: potenziano il modello serverless e offrono microservizi containerizzati senza complessità. Funzionano anche come repository per il tuo codice e facilitano gli sviluppatori durante la scrittura del codice per più piattaforme come desktop o iOS.
- Gateway API: funzionano come proxy per le azioni web. Offrono routing HTTP, limiti di velocità, visualizzazione dell’utilizzo dell’API e registri di risposta, ID client, ecc.
Come implementare il modello serverless e ottimizzarlo?
Il passaggio al serverless comporterà cambiamenti significativi in termini di applicazioni, tecnologia, costi, sicurezza e vantaggi.
Supponiamo che tu sia una start-up o una piccola impresa. In tal caso, accelererà il tuo time-to-market e ti aiuterà a inviare rapidamente gli aggiornamenti con test semplificati, debug, raccolta di feedback, lavoro sui problemi e altro ancora per offrire un’applicazione raffinata agli utenti.
Se sei un’organizzazione più grande, sperimenterai vantaggi come una maggiore scalabilità per soddisfare le esigenze degli utenti, ma richiederà un investimento di costi significativo.
Pertanto, è meglio valutare i pro ei contro del serverless in modo specifico per il tipo e le esigenze della tua attività e quindi procedere. E se sei serio, inizia con:
- Comprendere le tue esigenze e identificare uno stack tecnologico serverless adatto
- Scegli un fornitore serverless come Google Cloud Functions, Azure Functions, AWS Lambda, ecc.
- Potenzia il tuo team con potenti strumenti per monitorare le prestazioni e le funzioni del sistema. Fai attenzione al numero totale di richieste, limitazioni, conteggi di errori, percentuali di successo, durata delle richieste e latenza.
Fornitori senza server

Ci sono molti fornitori serverless o fornitori di servizi cloud sul mercato tra cui scegliere. Alcuni dei migliori sono:
- AWS Lambda: è perfetto per le organizzazioni che già sfruttano i servizi AWS. Si integra con un’ampia gamma di servizi per l’archiviazione, lo streaming e i database.
- Funzioni di Microsoft Azure: se usi Visual Studio Code, fallo. Funziona senza problemi con DevOps e Azure Pipelines per CI/CD. Supporta anche le funzioni permanenti per le funzioni stateful e offre il monitoraggio integrato.
- Funzioni Google Cloud: se utilizzi i servizi Google, va bene. Supporta le app JS, Go e Python, consente l’attivazione delle funzioni dall’Assistente Google o GCP e offre il ridimensionamento integrato.
- IBM Cloud Functions: se vuoi optare per un modello serverless basato su Apache OpenWhisk, IBM Cloud Functions fa per te. Include un eccellente monitoraggio delle prestazioni, l’attivazione di eventi da un’API REST o servizi cloud IBM e si integra con API Gateway di IBM per gestire gli endpoint.
- Knative: se stai eseguendo servizi su Kubernetes, fallo. È supportato da Google, Red Hat, IBM, ecc.
- Worker Cloudflare: va bene per le app che richiedono un’elevata reattività, in particolare le app JavaScript. Supporta Workers KV per l’archiviazione dei dati e WebAssembly per aiutarti a compilare e fornire più lingue. Inoltre, la sua elevata rete di distribuzione con 193 data center migliora la latenza e la reattività.
Conclusione: il futuro del serverless
L’elaborazione serverless si sta evolvendo con la crescente domanda di applicazioni altamente scalabili. Fornisce inoltre molti vantaggi offerti dal cloud computing, come maggiore praticità, efficienza dei costi, maggiore produttività e altro ancora.
Secondo un Sondaggio O’Reillyil 40% degli intervistati lavora in aziende che hanno adottato l’architettura serverless.
Sebbene il serverless abbia ancora alcune preoccupazioni, come la latenza dovuta a avvii a freddo, test, debug e così via, i fornitori di servizi cloud ci stanno lavorando. Presto potrebbe emergere una forma più raffinata di serverless con maggiori vantaggi e problemi risolti. Pertanto, si prevede che la popolarità e l’utilizzo del modello senza server aumenteranno in futuro.
Potrebbe interessarti anche: 7 modi in cui il serverless computing è una tecnologia in ascesa