

Su Linux, awk è una dinamo per la manipolazione del testo da riga di comando, nonché un potente linguaggio di scripting. Ecco un’introduzione ad alcune delle sue caratteristiche più interessanti.
Come awk ha preso il suo nome
Il comando awk è stato nominato utilizzando le iniziali delle tre persone che hanno scritto la versione originale nel 1977: Alfred Aho, Peter Weinberger, e Brian Kernighan. Questi tre uomini provenivano dal leggendario AT&T Bell Laboratories Pantheon Unix. Con il contributo di molti altri da allora, awk ha continuato ad evolversi.
È un linguaggio di scripting completo, nonché un kit completo di strumenti per la manipolazione del testo per la riga di comando. Se questo articolo stuzzica l’appetito, puoi farlo controlla ogni dettaglio su awk e sulla sua funzionalità.
Regole, modelli e azioni
awk funziona su programmi che contengono regole composte da modelli e azioni. L’azione viene eseguita sul testo che corrisponde al modello. I modelli sono racchiusi tra parentesi graffe ({}). Insieme, uno schema e un’azione formano una regola. L’intero programma awk è racchiuso tra virgolette singole (‘).
Diamo un’occhiata al tipo più semplice di programma awk. Non ha uno schema, quindi corrisponde a ogni riga di testo inserita. Ciò significa che l’azione viene eseguita su ogni riga. Bene usalo sull’output da il comando who.
Ecco l’output standard di who:
who

Forse non abbiamo bisogno di tutte queste informazioni, ma, piuttosto, vogliamo solo vedere i nomi sugli account. Possiamo convogliare l’output di who in awk, quindi dire ad awk di stampare solo il primo campo.
Per impostazione predefinita, awk considera un campo come una stringa di caratteri racchiusa tra spazi bianchi, l’inizio di una riga o la fine di una riga. I campi sono identificati da un segno di dollaro ($) e da un numero. Quindi, $ 1 rappresenta il primo campo, che useremo con l’azione print per stampare il primo campo.
Digitiamo quanto segue:
who | awk '{print $1}'
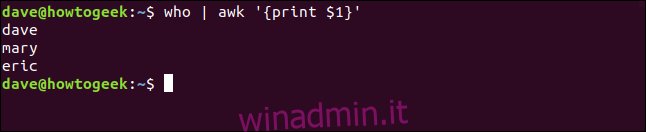
awk stampa il primo campo e scarta il resto della riga.
Possiamo stampare tutti i campi che vogliamo. Se aggiungiamo una virgola come separatore, awk stampa uno spazio tra ogni campo.
Digitiamo quanto segue per stampare anche l’ora in cui la persona ha effettuato l’accesso (campo quattro):
who | awk '{print $1,$4}'
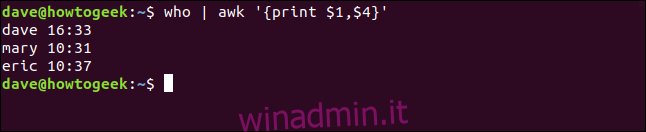
Ci sono un paio di identificatori di campo speciali. Questi rappresentano l’intera riga di testo e l’ultimo campo nella riga di testo:
$ 0: rappresenta l’intera riga di testo.
$ 1: rappresenta il primo campo.
$ 2: rappresenta il secondo campo.
$ 7: rappresenta il settimo campo.
$ 45: rappresenta il 45 ° campo.
$ NF: sta per “numero di campi” e rappresenta l’ultimo campo.
Digiteremo quanto segue per visualizzare un piccolo file di testo che contiene una breve citazione attribuita a Dennis Ritchie:
cat dennis_ritchie.txt

Vogliamo che awk stampi il primo, il secondo e l’ultimo campo della citazione. Nota che sebbene sia avvolto nella finestra del terminale, è solo una singola riga di testo.
Digitiamo il seguente comando:
awk '{print $1,$2,$NF}' dennis_ritchie.txt

Non conosciamo quella “semplicità”. è il diciottesimo campo nella riga di testo e non ci interessa. Quello che sappiamo è che è l’ultimo campo e possiamo usare $ NF per ottenerne il valore. Il periodo è considerato solo un altro personaggio nel