
Sommario:
Punti chiave
- La concorrenza e il parallelismo sono principi fondamentali dell’esecuzione delle attività nell’informatica, ciascuno con le sue caratteristiche distinte.
- La concorrenza consente un utilizzo efficiente delle risorse e una migliore reattività delle applicazioni, mentre il parallelismo è fondamentale per prestazioni e scalabilità ottimali.
- Python fornisce opzioni per gestire la concorrenza, come il threading e la programmazione asincrona con asyncio, nonché il parallelismo utilizzando il modulo multiprocessing.
Concorrenza e parallelismo sono due tecniche che consentono di eseguire più programmi contemporaneamente. Python ha più opzioni per gestire le attività contemporaneamente e in parallelo, il che può creare confusione.
Esplora gli strumenti e le librerie disponibili per implementare correttamente la concorrenza e il parallelismo in Python e come differiscono.
Comprendere la concorrenza e il parallelismo
Concorrenza e parallelismo si riferiscono a due principi fondamentali dell’esecuzione delle attività nell’informatica. Ognuno ha le sue caratteristiche distinte.

L’importanza della concorrenza e del parallelismo
La necessità di concorrenza e parallelismo nell’informatica non può essere sopravvalutata. Ecco perché queste tecniche sono importanti:
Concorrenza in Python
Puoi ottenere la concorrenza in Python utilizzando il threading e la programmazione asincrona con la libreria asyncio.
Discussione in Python
Il threading è un meccanismo di concorrenza Python che consente di creare e gestire attività all’interno di un singolo processo. I thread sono adatti per determinati tipi di attività, in particolare quelle legate a I/O e che possono trarre vantaggio dall’esecuzione simultanea.
Il modulo di threading di Python fornisce un’interfaccia di alto livello per la creazione e la gestione dei thread. Sebbene il GIL (Global Interpreter Lock) limiti i thread in termini di vero parallelismo, possono comunque raggiungere la concorrenza interlacciando le attività in modo efficiente.
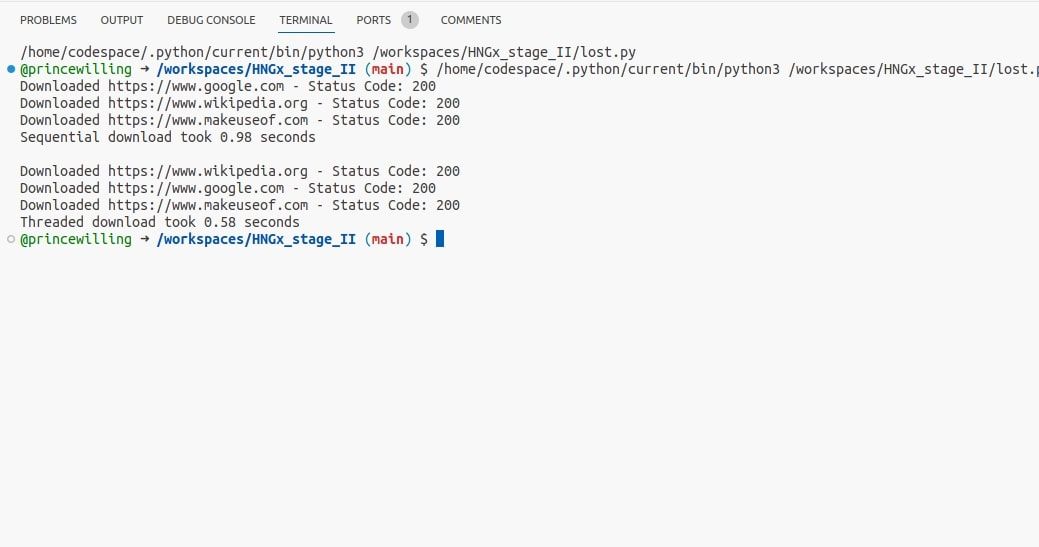
Il codice seguente mostra un esempio di implementazione della concorrenza utilizzando i thread. Utilizza la libreria di richieste Python per inviare una richiesta HTTP, un’attività comune di blocco I/O. Utilizza anche il modulo temporale per calcolare il tempo di esecuzione.
import requests
import time
import threadingurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()for url in urls:
download_url(url)end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Eseguendo questo programma, dovresti vedere quanto sono più veloci le richieste in thread rispetto alle richieste sequenziali. Anche se la differenza è solo di una frazione di secondo, si ha una chiara sensazione del miglioramento delle prestazioni quando si utilizzano i thread per attività legate all’I/O.
Programmazione asincrona con Asyncio
asincio fornisce un ciclo di eventi che gestisce attività asincrone chiamate coroutine. Le coroutine sono funzioni che puoi mettere in pausa e riprendere, rendendole ideali per attività legate all’I/O. La libreria è particolarmente utile per scenari in cui le attività implicano l’attesa di risorse esterne, come le richieste di rete.
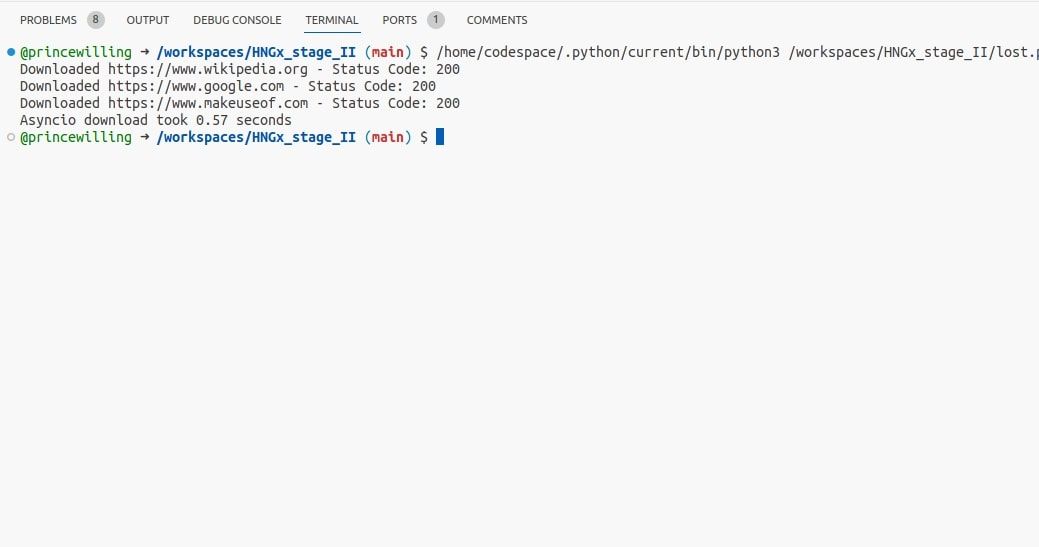
Puoi modificare il precedente esempio di invio della richiesta per lavorare con asyncio:
import asyncio
import aiohttp
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)start_time = time.time()
asyncio.run(main())end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
Utilizzando il codice, è possibile scaricare pagine Web contemporaneamente utilizzando asyncio e sfruttare le operazioni di I/O asincrone. Questo può essere più efficiente del threading per le attività legate a I/O.
Parallelismo in Python
Puoi implementare il parallelismo usando Il modulo multiprocessore di Pythonche consente di sfruttare appieno i processori multicore.
Multiprocessing in Python
Il modulo multiprocessing di Python fornisce un modo per ottenere il parallelismo creando processi separati, ciascuno con il proprio interprete Python e spazio di memoria. Ciò bypassa efficacemente il Global Interpreter Lock (GIL), rendendolo adatto per attività legate alla CPU.
import requests
import multiprocessing
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
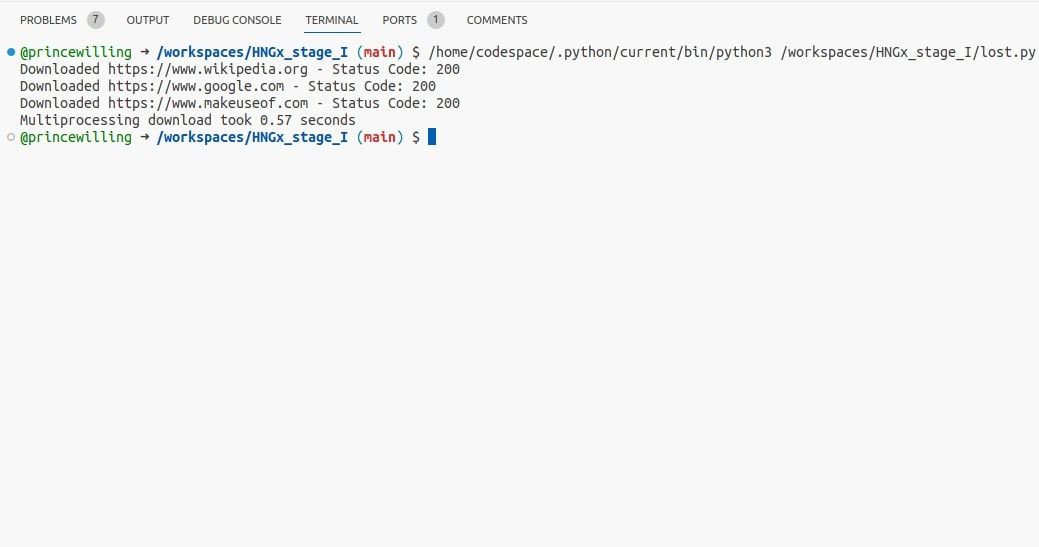
In questo esempio, il multiprocessing genera più processi, consentendo l’esecuzione in parallelo della funzione download_url.
Quando utilizzare la concorrenza o il parallelismo
La scelta tra concorrenza e parallelismo dipende dalla natura delle attività e dalle risorse hardware disponibili.
È possibile utilizzare la concorrenza quando si gestiscono attività legate all’I/O, ad esempio la lettura e la scrittura su file o l’esecuzione di richieste di rete, e quando i vincoli di memoria rappresentano un problema.
Utilizzare il multiprocessing quando si hanno attività legate alla CPU che possono trarre vantaggio dal vero parallelismo e quando si dispone di un solido isolamento tra le attività, in cui l’errore di un’attività non dovrebbe influire sugli altri.
Sfrutta la concorrenza e il parallelismo
Il parallelismo e la concorrenza sono modi efficaci per migliorare la reattività e le prestazioni del codice Python. È importante comprendere le differenze tra questi concetti e selezionare la strategia più efficace.
Python offre gli strumenti e i moduli necessari per rendere il tuo codice più efficace attraverso la concorrenza o il parallelismo, indipendentemente dal fatto che tu stia lavorando con processi legati alla CPU o legati all’I/O.