

Nel mondo odierno guidato dai dati, il metodo tradizionale di raccolta manuale dei dati è obsoleto. Un computer con connessione internet su ogni scrivania ha reso il web un’enorme fonte di dati. Pertanto, il metodo moderno più efficiente e che fa risparmiare tempo per la raccolta dei dati è il web scraping. E quando si tratta di web scraping, Python ha uno strumento chiamato Beautiful Soup. In questo post, ti guiderò attraverso i passaggi di installazione di Beautiful Soup per iniziare con il web scraping.
Prima di installare e lavorare con Beautiful Soup, scopriamo perché dovresti farlo.
Sommario:
Cos’è una bella zuppa?
Supponiamo che tu stia cercando “l’impatto del COVID sulla salute delle persone” e abbia trovato alcune pagine web contenenti dati rilevanti. Ma cosa succede se non ti offrono un’opzione di download con un solo clic per prendere in prestito i loro dati? Ecco che entra in gioco la Bella Zuppa.
Beautiful Soup è tra gli indici delle librerie Python per estrarre i dati da siti mirati. È più comodo recuperare i dati da pagine HTML o XML.
Leonard Richardson ha portato alla luce l’idea di Beautiful Soup per raschiare il web nel 2004. Ma il suo contributo al progetto continua ancora oggi. Aggiorna con orgoglio ogni nuova versione di Beautiful Soup sul suo account Twitter.
Sebbene Beautiful Soup per il web scraping sia stato sviluppato utilizzando Python 3.8, funziona perfettamente anche con Python 3 e Python 2.4.
Spesso i siti Web utilizzano la protezione captcha per salvare i propri dati dagli strumenti di intelligenza artificiale. In questo caso, alcune modifiche all’intestazione “user-agent” in Beautiful Soup o l’utilizzo di API per la risoluzione dei captcha possono imitare un browser affidabile e ingannare lo strumento di rilevamento.
Tuttavia, se non hai tempo per esplorare Beautiful Soup o desideri che lo scraping venga eseguito in modo efficiente e a tuo agio, allora non dovresti perdere il controllo di questa API di web scraping, in cui puoi semplicemente fornire un URL e ottenere i dati in le tue mani.
Se sei già un programmatore, utilizzare Beautiful Soup per lo scraping non sarà scoraggiante a causa della sua sintassi semplice nella navigazione delle pagine Web e nell’estrazione dei dati desiderati in base all’analisi condizionale. Allo stesso tempo, è anche adatto ai principianti.
Sebbene Beautiful Soup non sia per lo scraping avanzato, funziona meglio per raschiare i dati dai file scritti in linguaggi di markup.
La documentazione chiara e dettagliata è un altro punto fondamentale che Beautiful Soup ha insaccato.
Troviamo un modo semplice per ottenere una bella zuppa nella tua macchina.
Come installare Beautiful Soup per il web scraping?
Pip: un semplice gestore di pacchetti Python sviluppato nel 2008 è ora uno strumento standard tra gli sviluppatori per installare qualsiasi libreria o dipendenza Python.
Pip viene fornito di default con l’installazione delle versioni recenti di Python. Pertanto, se sul tuo sistema sono installate versioni recenti di Python, sei a posto.
Apri il prompt dei comandi e digita il seguente comando pip per installare istantaneamente la bellissima Soup.
pip install beautifulsoup4
Vedrai qualcosa di simile al seguente screenshot sul tuo display.
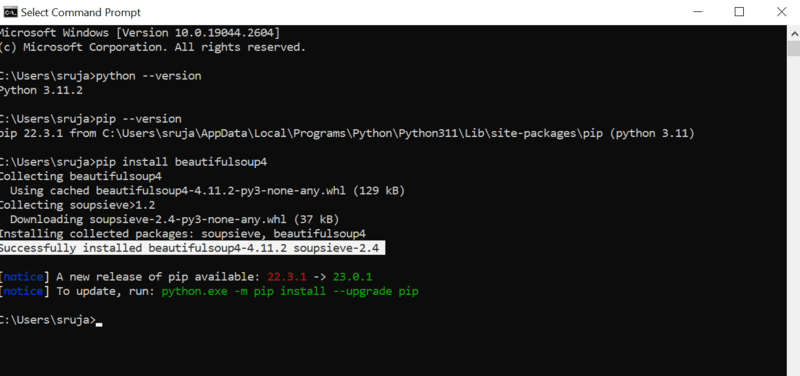
Assicurati di aver aggiornato il programma di installazione PIP all’ultima versione per evitare errori comuni.
Il comando per aggiornare il programma di installazione pip all’ultima versione è:
pip install --upgrade pip
Abbiamo coperto con successo metà del terreno in questo post.
Ora hai installato Beautiful Soup sul tuo computer, quindi esaminiamo come usarlo per il web scraping.
Come importare e lavorare con Beautiful Soup per il web scraping?
Digita il seguente comando nel tuo IDE Python per importare la bella Soup nello script Python corrente.
from bs4 import BeautifulSoup
Ora la bella zuppa è nel tuo file Python da usare per lo scraping.
Diamo un’occhiata a un esempio di codice per imparare come estrarre i dati desiderati con il bellissimo Soup.
Possiamo dire a Beautiful Soup di cercare tag HTML specifici nel sito Web di origine e di raschiare i dati presenti in quei tag.
In questo pezzo userò marketwatch.com, che aggiorna i prezzi delle azioni in tempo reale di varie società. Tiriamo fuori alcuni dati da questo sito Web per familiarizzare con la libreria Beautiful Soup.
Importa il pacchetto “requests” che ci permetterà di ricevere e rispondere alle richieste HTTP e “urllib” per caricare la pagina web dal suo URL.
from urllib.request import urlopen import requests
Salva il link della pagina web in una variabile in modo da potervi accedere facilmente in seguito.
url="https://www.marketwatch.com/investing/stock/amzn"
Il prossimo sarebbe utilizzare il metodo “urlopen” dalla libreria “urllib” per memorizzare la pagina HTML in una variabile. Passa l’URL alla funzione “urlopen” e salva il risultato in una variabile.
page = urlopen(url)
Crea un oggetto Beautiful Soup e analizza la pagina Web desiderata utilizzando “html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Ora l’intero script HTML della pagina web mirata è memorizzato nella variabile ‘soup_obj’.
Prima di procedere, diamo un’occhiata al codice sorgente della pagina mirata per saperne di più sullo script e sui tag HTML.
Fai clic con il pulsante destro del mouse in un punto qualsiasi della pagina web. Quindi troverai un’opzione di ispezione, come mostrato di seguito.
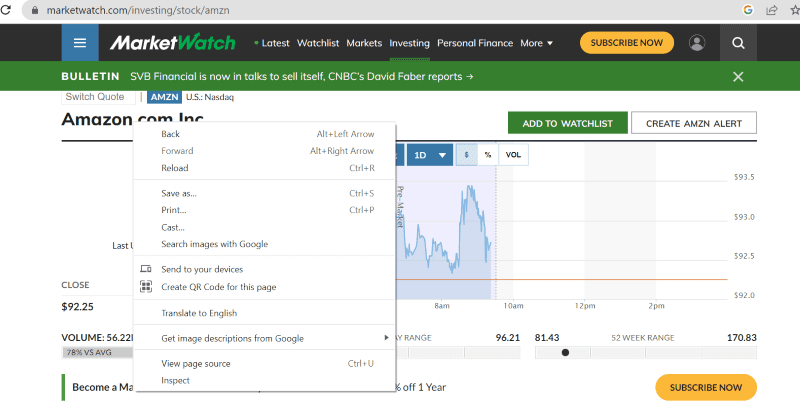
Fare clic su ispeziona per visualizzare il codice sorgente.
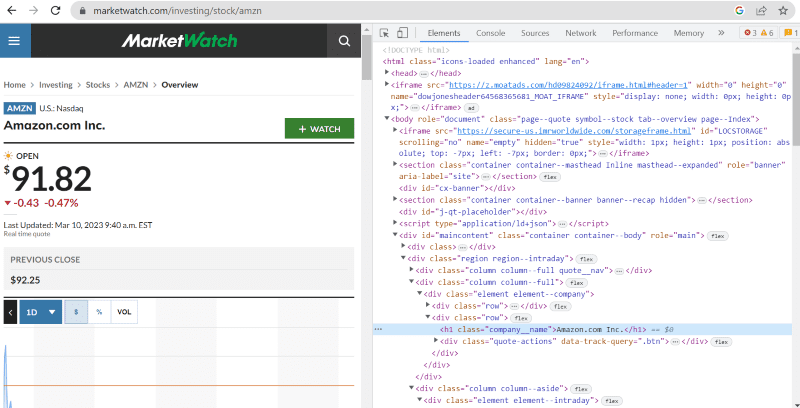
Nel codice sorgente di cui sopra, puoi trovare tag, classi e informazioni più specifiche su ogni elemento visibile sull’interfaccia del sito web.
Il metodo “trova” in beautiful Soup ci consente di cercare i tag HTML richiesti e recuperare i dati. Per fare ciò, diamo il nome della classe e i tag al metodo che estrae dati specifici.
Ad esempio, “Amazon.com Inc.” mostrato sulla pagina web ha il nome della classe: ‘company__name’ contrassegnato sotto ‘h1’. Possiamo inserire queste informazioni nel metodo “find” per estrarre lo snippet HTML pertinente in una variabile.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Produciamo sullo schermo lo script HTML memorizzato nella variabile “name” e il testo richiesto.
print(name) print(name.text)

Puoi assistere ai dati estratti stampati sullo schermo.
Web Scrape del sito web di IMDb
Molti di noi cercano le valutazioni dei film sul sito di IMBb prima di guardare un film. Questa dimostrazione ti fornirà un elenco dei film più votati e ti aiuterà ad abituarti alla bellissima Zuppa per il web scraping.
Passaggio 1: importa le bellissime librerie Soup e richieste.
from bs4 import BeautifulSoup import requests
Passaggio 2: assegniamo l’URL che vogliamo raschiare a una variabile chiamata “url” per un facile accesso nel codice.
Il pacchetto “richieste” viene utilizzato per ottenere la pagina HTML dall’URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Passaggio 3: nel seguente frammento di codice, analizzeremo la pagina HTML dell’URL corrente per creare un oggetto di bella zuppa.
soup_obj = BeautifulSoup(url.text, 'html.parser')
La variabile “soup_obj” ora contiene l’intero script HTML della pagina Web desiderata, come nell’immagine seguente.
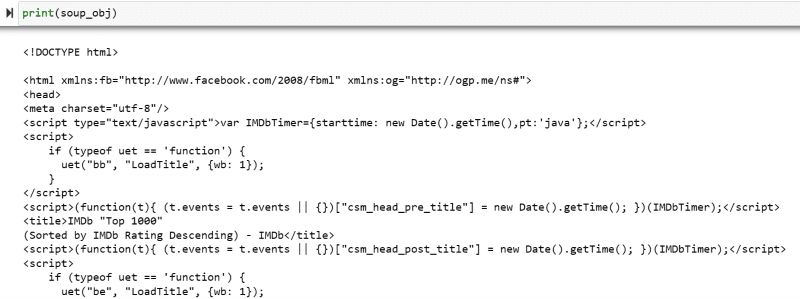
Ispezioniamo il codice sorgente della pagina web per trovare lo script HTML dei dati che vogliamo raschiare.
Passa il cursore sull’elemento della pagina Web che desideri estrarre. Successivamente, fai clic destro su di esso e vai con l’opzione inspect per visualizzare il codice sorgente di quell’elemento specifico. Le seguenti immagini ti guideranno meglio.
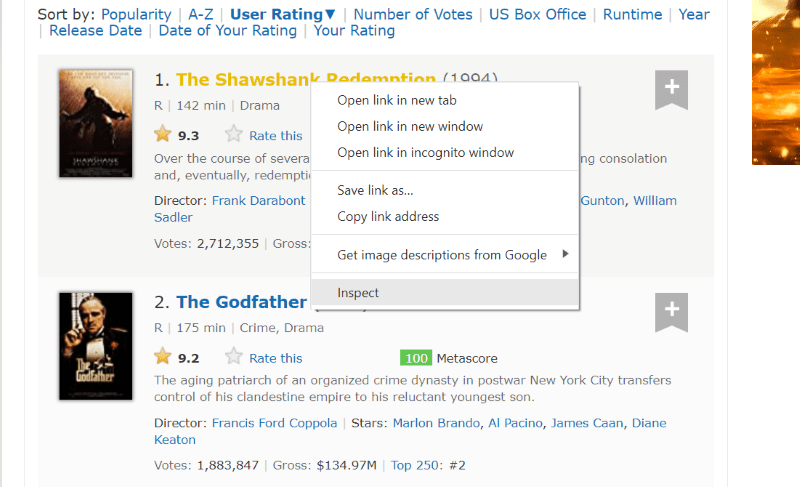
La classe “lister-list” contiene tutti i dati relativi ai film più votati come suddivisioni in tag div successivi.
Nello script HTML di ogni scheda film, sotto la classe “lister-item mode-advanced”, abbiamo un tag “h3” che memorizza il nome del film, la classifica e l’anno di uscita, come evidenziato nell’immagine sottostante.
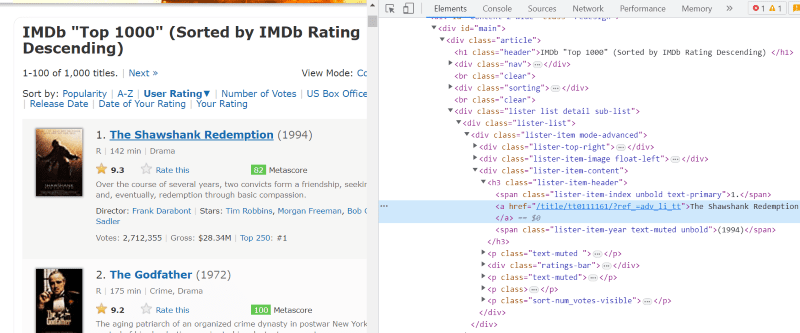
Nota: il metodo “trova” in beautiful Soup cerca il primo tag che corrisponde al nome di input assegnatogli. A differenza di “find”, il metodo “find_all” cerca tutti i tag che corrispondono all’input specificato.
Passaggio 4: è possibile utilizzare i metodi “find” e “find_all” per salvare lo script HTML del nome, della classifica e dell’anno di ogni film in una variabile di elenco.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Passaggio 5: scorri l’elenco dei film memorizzati nella variabile: “top_movies” ed estrai il nome, la classifica e l’anno di ciascun film in formato testo dal suo script HTML utilizzando il codice seguente.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
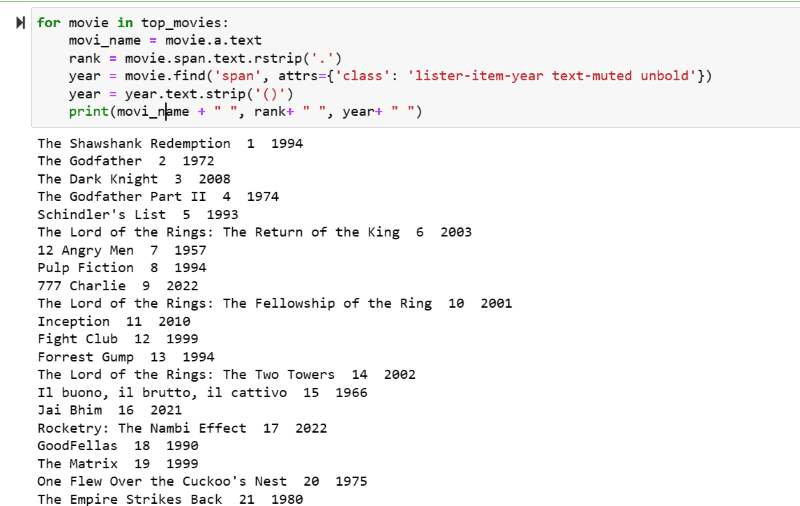
Nello screenshot di output, puoi vedere l’elenco dei film con il loro nome, grado e anno di uscita.
Puoi spostare facilmente i dati stampati in un foglio Excel con del codice Python e utilizzarli per la tua analisi.
Parole finali
Questo post ti guida nell’installazione della bellissima Soup per il web scraping. Inoltre, gli esempi di scraping che ho mostrato dovrebbero aiutarti a iniziare con Beautiful Soup.
Dato che sei interessato a come installare Beautiful Soup per il web scraping, ti consiglio vivamente di dare un’occhiata a questa guida comprensibile per saperne di più sul web scraping usando Python.