Il comando patch di Linux consente di trasferire le modifiche da un set di file a un altro set di file in modo rapido e sicuro. Impara come usare le patch in modo semplice.
Sommario:
I comandi patch e diff
Immagina di avere un file di testo sul tuo computer. Ricevi una versione modificata di quel file di testo da qualcun altro. Come si trasferiscono rapidamente tutte le modifiche dal file modificato al file originale? È qui che entrano in gioco patch e diff. patch e diff si trovano in Linux e in altri sistemi operativi Unix-Like, come macOS.
Il comando diff esamina due diverse versioni di un file ed elenca le differenze tra loro. Le differenze possono essere memorizzate in un file chiamato file patch.
Il comando patch può leggere un file patch e utilizzare il contenuto come un insieme di istruzioni. Seguendo queste istruzioni, le modifiche nel file modificato sono replicato nell’originale file.
Ora immagina che il processo avvenga in un’intera directory di file di testo. Tutto in una volta. Questo è il potere della patch.
A volte non vengono inviati i file modificati. Tutto ciò che viene inviato è il file di patch. Perché inviare dozzine di file quando puoi inviare un file o pubblicare un file per un facile download?
Cosa fai con il file di patch per correggere effettivamente i tuoi file? Oltre ad essere quasi uno scioglilingua, questa è anche una bella domanda. Ti guideremo attraverso questo articolo.
Il comando patch viene spesso utilizzato da persone che lavorano con file di codice sorgente software, ma funziona ugualmente bene con qualsiasi set di file di testo indipendentemente dal loro scopo, codice sorgente o meno.
Il nostro scenario di esempio
In questo scenario, ci troviamo in una directory chiamata lavoro che contiene altre due directory. Uno si chiama lavoro e l’altro si chiama ultimo. La directory di lavoro contiene una serie di file di codice sorgente. L’ultima directory contiene la versione più recente di quei file di codice sorgente, alcuni dei quali sono stati modificati.
Per sicurezza, la directory di lavoro è una copia della versione corrente dei file di testo. Non è l’unica copia di loro.
Trovare le differenze tra due versioni di un file
Il comando diff trova le differenze tra due file. La sua azione predefinita è elencare le righe modificate nella finestra del terminale.
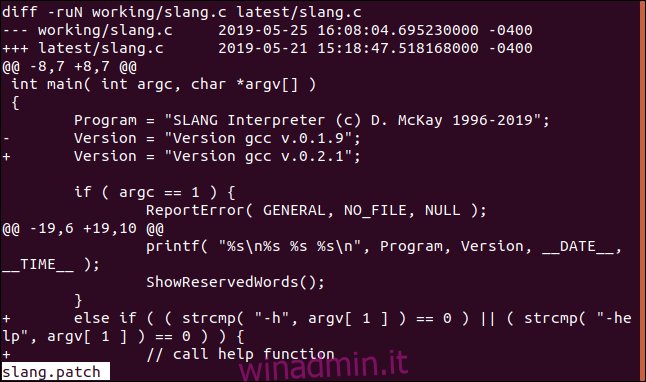
Un file si chiama slang.c. Confronteremo la versione nella directory di lavoro con quella nella directory più recente.
L’opzione -u (unificata) dice a diff di elencare anche alcune delle righe di testo non modificate prima e dopo ciascuna delle sezioni modificate. Queste righe sono chiamate righe di contesto. Aiutano il comando patch a individuare con precisione dove è necessario apportare una modifica nel file originale.
Forniamo i nomi dei file in modo che diff sappia quali file confrontare. Il file originale viene elencato per primo, quindi il file modificato. Questo è il comando che emettiamo per diff:
diff -u working/slang.c latest/slang.c

diff produce un elenco di output che mostra le differenze tra i file. Se i file fossero identici, non ci sarebbe alcun output elencato. La visualizzazione di questo tipo di output da diff conferma che ci sono differenze tra le due versioni di file e che il file originale necessita di patch.
Creazione di un file di patch
Per catturare queste differenze in un file di patch, utilizzare il seguente comando. È lo stesso comando di cui sopra, con l’output di diff reindirizzato in un file chiamato slang.patch.
diff -u working/slang.c latest/slang.c > slang.patch

Per fare in modo che patch agisca sul file patch e modifichi il file working / slang.c, utilizzare il seguente comando. L’opzione -u (unificata) consente a patch di sapere che il file di patch contiene righe di contesto unificate. In altre parole, abbiamo usato l’opzione -u con diff, quindi usiamo l’opzione -u con patch.
patch -u working.slang.c -i slang.patch
Se tutto va bene, c’è un’unica riga di output che ti dice che la patch sta correggendo il file.
Fare un backup del file originale
Possiamo indicare a patch di creare una copia di backup dei file con patch prima che vengano modificati utilizzando l’opzione -b (backup). L’opzione -i (input) dice a patch il nome del file di patch da usare:
patch -u -b working.slang.c -i slang.patch

Il file è patchato come prima, senza differenze visibili nell’output. Tuttavia, se guardi nella cartella di lavoro, vedrai che il file chiamato slang.c.orig è stato creato. La data e l’ora dei file mostrano che slang.c.orig è il file originale e slang.c è un nuovo file creato da patch.

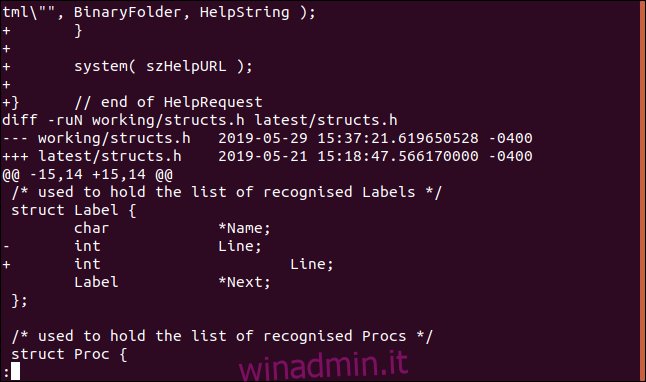
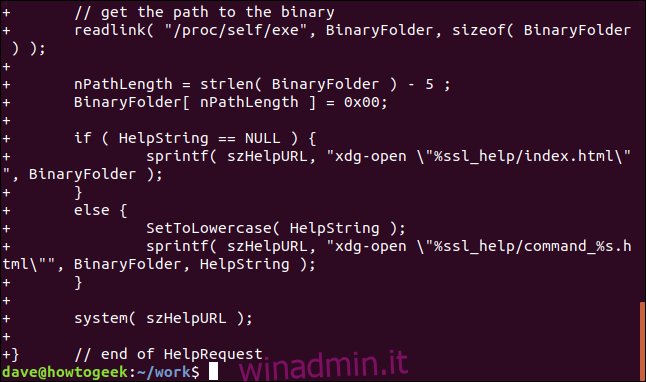
Utilizzo di diff con directory
Possiamo usare diff per creare un file patch che contiene tutte le differenze tra i file in due directory. Possiamo quindi utilizzare quel file patch con patch per applicare quelle differenze ai file nella cartella di lavoro con un singolo comando.
Le opzioni che useremo con diff sono l’opzione -u (contesto unificato) che abbiamo usato in precedenza, l’opzione -r (ricorsiva) per far cercare a diff in qualsiasi sottodirectory e l’opzione -N (nuovo file).
L’opzione -N dice a diff come gestire i file nell’ultima directory che non si trovano nella directory di lavoro. Forza diff a inserire le istruzioni nel file patch in modo che patch crei file presenti nell’ultima directory ma mancanti dalla directory di lavoro.
Puoi raggruppare le opzioni insieme in modo che utilizzino un solo trattino (-).
Nota che stiamo fornendo solo i nomi delle directory, non stiamo dicendo a diff di guardare file specifici:
diff -ruN working/ latest/ > slang.patch