

Immagina di avere una grande infrastruttura di vari tipi di dispositivi che devi mantenere regolarmente o assicurarti che non siano pericolosi per l’ambiente circostante.
Un modo per raggiungere questo obiettivo è inviare regolarmente persone in ogni punto per verificare se tutto va bene. Questo è in qualche modo fattibile ma anche piuttosto costoso in termini di tempo e risorse. E se l’infrastruttura è abbastanza grande, potresti non essere in grado di coprirla interamente entro un anno.
Un altro modo è automatizzare quel processo e lasciare che i lavori nel cloud verifichino per te. Perché ciò accada, dovrai fare quanto segue:
👉 Un rapido processo su come ottenere le immagini dei dispositivi. Questo può ancora essere fatto dalle persone in quanto è ancora molto più veloce fare solo un’immagine come fare tutti i processi di verifica del dispositivo. Può anche essere fatto da foto scattate da auto o persino da droni, nel qual caso diventa un processo di raccolta di immagini molto più veloce e automatizzato.
👉 Quindi devi inviare tutte le immagini ottenute a un posto dedicato nel cloud.
👉 Nel cloud, è necessario un lavoro automatizzato per raccogliere le immagini ed elaborarle attraverso modelli di apprendimento automatico addestrati a riconoscere danni o anomalie del dispositivo.
👉 Infine, i risultati devono essere visibili agli utenti richiesti in modo da poter programmare la riparazione per i dispositivi con problemi.
Diamo un’occhiata a come possiamo ottenere il rilevamento delle anomalie dalle immagini nel cloud AWS. Amazon ha alcuni modelli di apprendimento automatico predefiniti che possiamo utilizzare a tale scopo.
Sommario:
Come creare un modello per il rilevamento di anomalie visive
Per creare un modello per il rilevamento di anomalie visive, dovrai seguire diversi passaggi:
Step 1: Definisci chiaramente il problema che vuoi risolvere e i tipi di anomalie che vuoi rilevare. Questo ti aiuterà a determinare il set di dati di test appropriato di cui avrai bisogno per addestrare il modello.
Passaggio 2: raccogliere un ampio set di dati di immagini che rappresentano condizioni normali e anomale. Etichetta le immagini per indicare quali sono normali e quali contengono anomalie.
Passaggio 3: scegliere un’architettura del modello adatta all’attività. Ciò può comportare la selezione di un modello pre-addestrato e la sua messa a punto per il tuo caso d’uso specifico o la creazione di un modello personalizzato da zero.
Passaggio 4: addestrare il modello utilizzando il set di dati preparato e l’algoritmo selezionato. Ciò significa utilizzare il transfer learning per sfruttare modelli pre-addestrati o addestrare il modello da zero utilizzando tecniche come le reti neurali convoluzionali (CNN).
Come addestrare un modello di Machine Learning
Fonte: aws.amazon.com
Il processo di addestramento dei modelli di machine learning AWS per il rilevamento di anomalie visive comporta in genere diversi passaggi importanti.
#1. Raccogli i dati
All’inizio è necessario raccogliere ed etichettare un ampio set di dati di immagini che rappresentano condizioni normali e anomale. Più grande è il set di dati, migliore e più preciso può essere addestrato il modello. Ma richiede anche molto più tempo dedicato all’addestramento del modello.
Di solito, vuoi avere circa 1000 immagini in un set di test per iniziare bene.
#2. Prepara i dati
I dati dell’immagine devono essere prima pre-elaborati affinché i modelli di apprendimento automatico siano in grado di raccoglierli. La pre-elaborazione può significare varie cose, come:
- Pulizia delle immagini di input in sottocartelle separate, correzione dei metadati, ecc.
- Ridimensionamento delle immagini per soddisfare i requisiti di risoluzione del modello.
- Distribuirli in blocchi più piccoli di immagini per un’elaborazione più efficace e parallela.
#3. Seleziona il Modello
Ora scegli il modello giusto per fare il lavoro giusto. Scegli un modello pre-addestrato oppure puoi creare un modello personalizzato adatto al rilevamento visivo delle anomalie sul modello.
#4. Valuta i risultati
Una volta che il modello elabora il tuo set di dati, devi convalidarne le prestazioni. Inoltre, vuoi verificare se i risultati sono soddisfacenti per le esigenze. Ciò può significare, ad esempio, che i risultati sono corretti su oltre il 99% dei dati di input.
#5. Distribuisci il modello
Se sei soddisfatto dei risultati e delle prestazioni, distribuisci il modello con una versione specifica nell’ambiente dell’account AWS in modo che i processi e i servizi possano iniziare a usarlo.
#6. Monitorare e migliorare
Lascia che esegua vari lavori di test e set di dati delle immagini e valuti costantemente se i parametri richiesti per la correttezza del rilevamento sono ancora presenti.
In caso contrario, ripetere il training del modello includendo i nuovi set di dati in cui il modello ha fornito i risultati errati.
Modelli di machine learning AWS
Ora, guarda alcuni modelli concreti che puoi sfruttare nel cloud di Amazon.
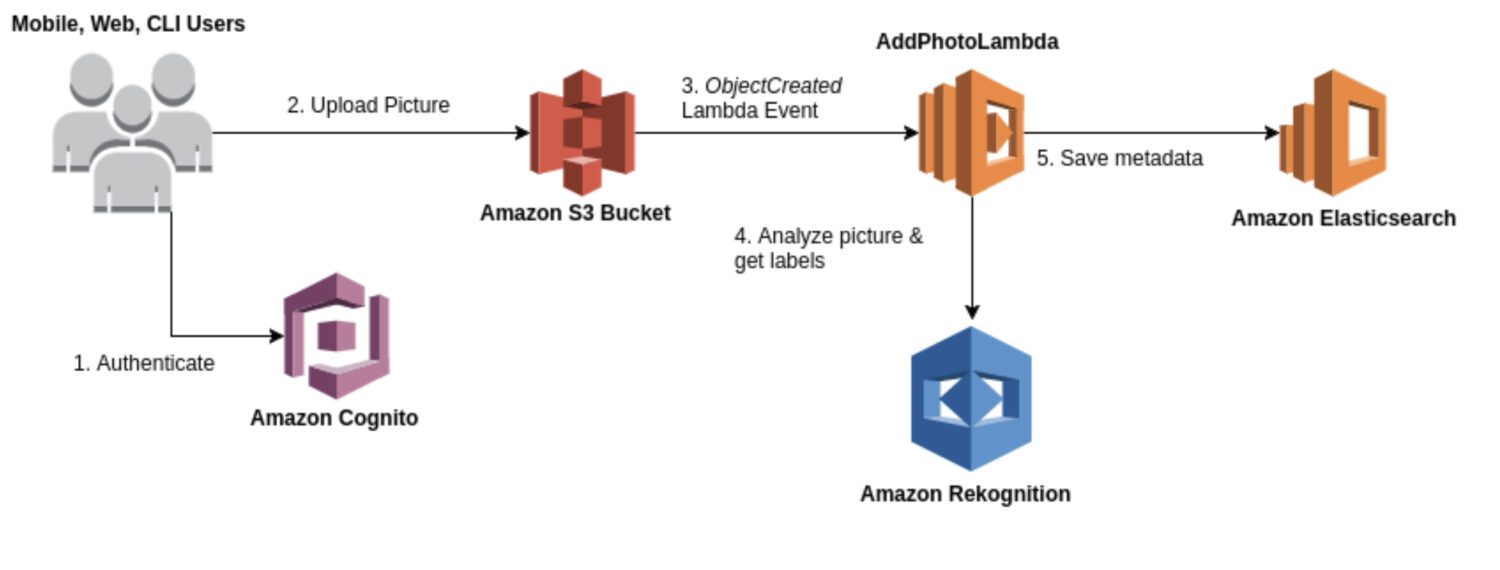
Riconoscimento AWS
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Rekognition è un servizio generico di analisi di immagini e video utilizzabile per vari casi d’uso, come il riconoscimento facciale, il rilevamento di oggetti e il riconoscimento del testo. Nella maggior parte dei casi, utilizzerai il modello Rekognition per una generazione grezza iniziale di risultati di rilevamento per formare un data lake di anomalie identificate.
Fornisce una gamma di modelli predefiniti che è possibile utilizzare senza formazione. Rekognition fornisce anche analisi in tempo reale di immagini e video con elevata precisione e bassa latenza.
Ecco alcuni casi d’uso tipici in cui Rekognition è una buona scelta per il rilevamento delle anomalie:
- Avere un caso d’uso generico per il rilevamento delle anomalie, ad esempio il rilevamento di anomalie nelle immagini o nei video.
- Eseguire il rilevamento delle anomalie in tempo reale.
- Integra il tuo modello di rilevamento delle anomalie con i servizi AWS come Amazon S3, Amazon Kinesis o AWS Lambda.
Ed ecco alcuni esempi concreti di anomalie che puoi rilevare utilizzando Rekognition:
- Anomalie nei volti, come il rilevamento di espressioni facciali o emozioni al di fuori del range normale.
- Oggetti mancanti o fuori posto in una scena.
- Parole con errori di ortografia o schemi di testo insoliti.
- Condizioni di illuminazione insolite o oggetti inaspettati in una scena.
- Contenuti inappropriati o offensivi in immagini o video.
- Cambiamenti improvvisi nel movimento o schemi di movimento imprevisti.
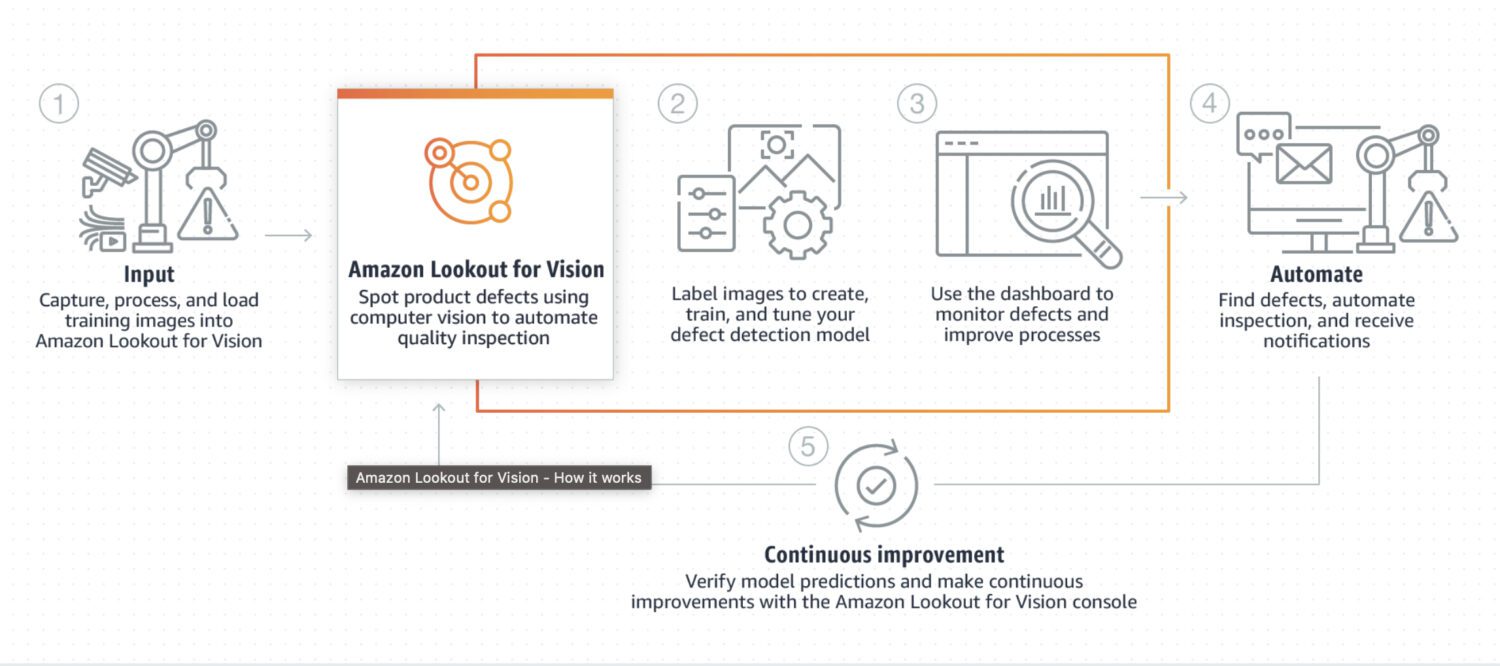
AWS Lookout per la visione
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Lookout for Vision è un modello specificamente progettato per il rilevamento di anomalie nei processi industriali, come la produzione e le linee di produzione. In genere richiede una pre-elaborazione e post-elaborazione di un codice personalizzato di un’immagine o un ritaglio concreto dell’immagine, solitamente eseguito utilizzando un linguaggio di programmazione Python. Il più delle volte, è specializzato in alcuni problemi molto speciali nell’immagine.
Richiede un training personalizzato su un set di dati di immagini normali e anomale per creare un modello personalizzato per il rilevamento delle anomalie. Non è così focalizzato in tempo reale; piuttosto, è progettato per l’elaborazione in batch di immagini, concentrandosi su accuratezza e precisione.
Ecco alcuni casi d’uso tipici in cui Lookout for Vision è una buona scelta se devi rilevare:
- Difetti nei prodotti fabbricati o identificazione di guasti alle apparecchiature in una linea di produzione.
- Un grande set di dati di immagini o altri dati.
- Anomalia in tempo reale in un processo industriale.
- Anomalia integrata con altri servizi AWS, come Amazon S3 o AWS IoT.
Ed ecco alcuni esempi concreti di anomalie che puoi rilevare utilizzando Lookout for Vision:
- Difetti nei prodotti fabbricati, come graffi, ammaccature o altre imperfezioni, possono influire sulla qualità del prodotto.
- Guasti alle apparecchiature in una linea di produzione, come il rilevamento di macchinari rotti o malfunzionanti che possono causare ritardi o rischi per la sicurezza.
- I problemi di controllo della qualità in una linea di produzione includono il rilevamento di prodotti che non soddisfano le specifiche o le tolleranze richieste.
- I rischi per la sicurezza in una linea di produzione includono il rilevamento di oggetti o materiali che possono rappresentare un rischio per i lavoratori o le attrezzature.
- Anomalie in un processo di produzione, come il rilevamento di cambiamenti imprevisti nel flusso di materiali o prodotti attraverso la linea di produzione.
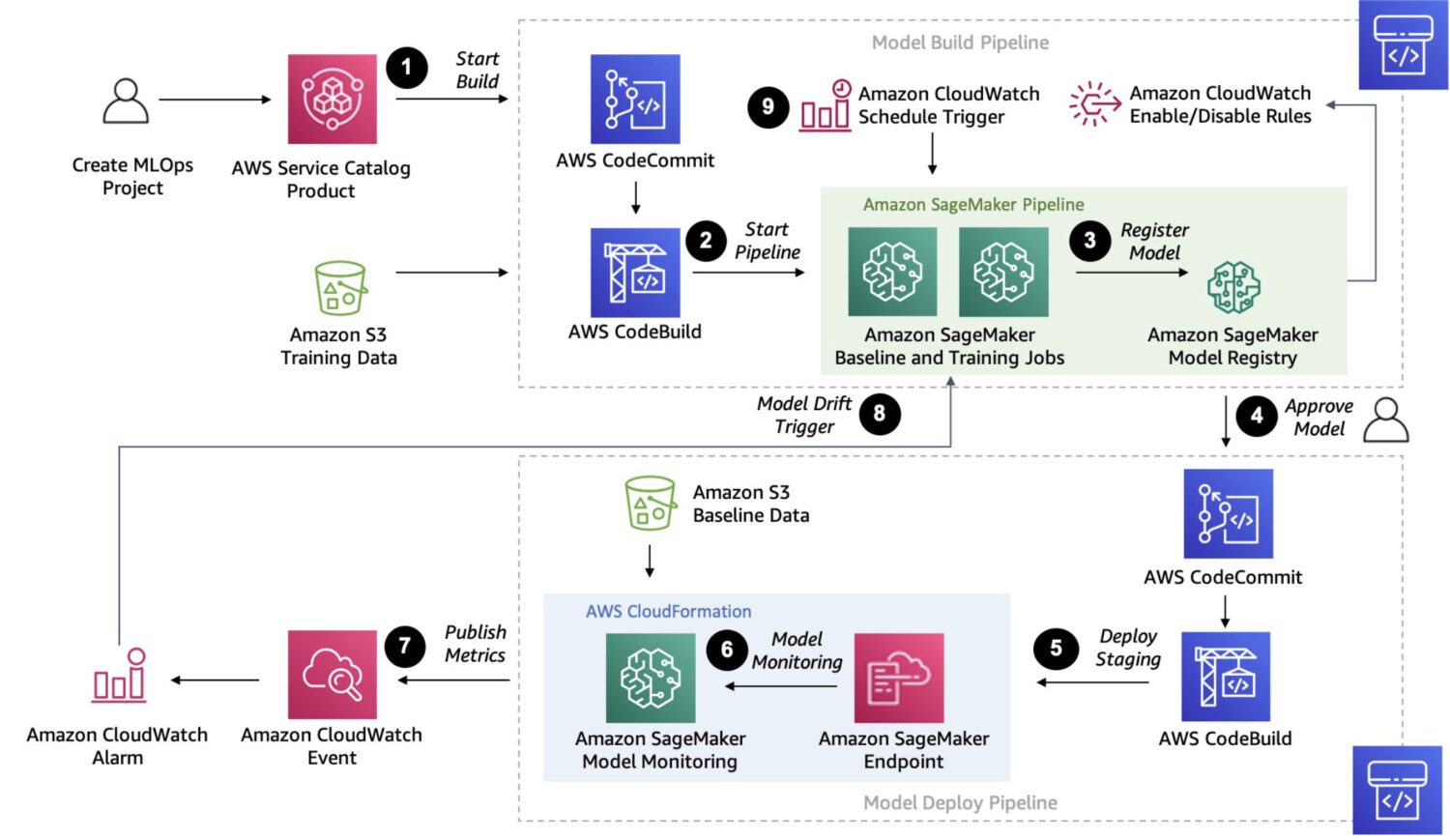
AWS Sagemaker
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Sagemaker è una piattaforma completamente gestita per la creazione, l’addestramento e l’implementazione di modelli di machine learning personalizzati.
È una soluzione molto più robusta. In effetti, fornisce un modo per connettere ed eseguire diversi processi multifase in una catena di lavori che si susseguono uno dopo l’altro, proprio come possono fare le AWS Step Functions.
Tuttavia, poiché Sagemaker utilizza istanze EC2 ad hoc per la sua elaborazione, non esiste un limite di 15 minuti per l’elaborazione di un singolo lavoro, come nel caso delle funzioni AWS lambda nelle AWS Step Functions.
Puoi anche eseguire la messa a punto automatica del modello con Sagemaker, che è sicuramente una caratteristica che lo rende un’opzione di spicco. Infine, Sagemaker può distribuire facilmente il modello in un ambiente di produzione.
Ecco alcuni casi d’uso tipici in cui SageMaker è una buona scelta per il rilevamento delle anomalie:
- Un caso d’uso specifico non coperto da modelli o API predefiniti e se hai bisogno di creare un modello personalizzato su misura per le tue esigenze specifiche.
- Se disponi di un ampio set di dati di immagini o altri dati. I modelli predefiniti richiedono una pre-elaborazione in questi casi, ma Sagemaker può farne a meno.
- Se è necessario eseguire il rilevamento delle anomalie in tempo reale.
- Se devi integrare il tuo modello con altri servizi AWS, come Amazon S3, Amazon Kinesis o AWS Lambda.
Ed ecco alcuni tipici rilevamenti di anomalie che Sagemaker è in grado di eseguire:
- Rilevamento di frodi nelle transazioni finanziarie, ad esempio, modelli di spesa insoliti o transazioni al di fuori dell’intervallo normale.
- Sicurezza informatica nel traffico di rete, come modelli insoliti di trasferimento dati o connessioni impreviste a server esterni.
- Diagnosi medica in immagini mediche, come il rilevamento di tumori.
- Anomalie nelle prestazioni delle apparecchiature, come il rilevamento di cambiamenti nelle vibrazioni o nella temperatura.
- Controllo di qualità nei processi di produzione, come il rilevamento di difetti nei prodotti o l’identificazione di deviazioni dagli standard di qualità previsti.
- Modelli insoliti di consumo di energia.
Come incorporare i modelli nell’architettura serverless
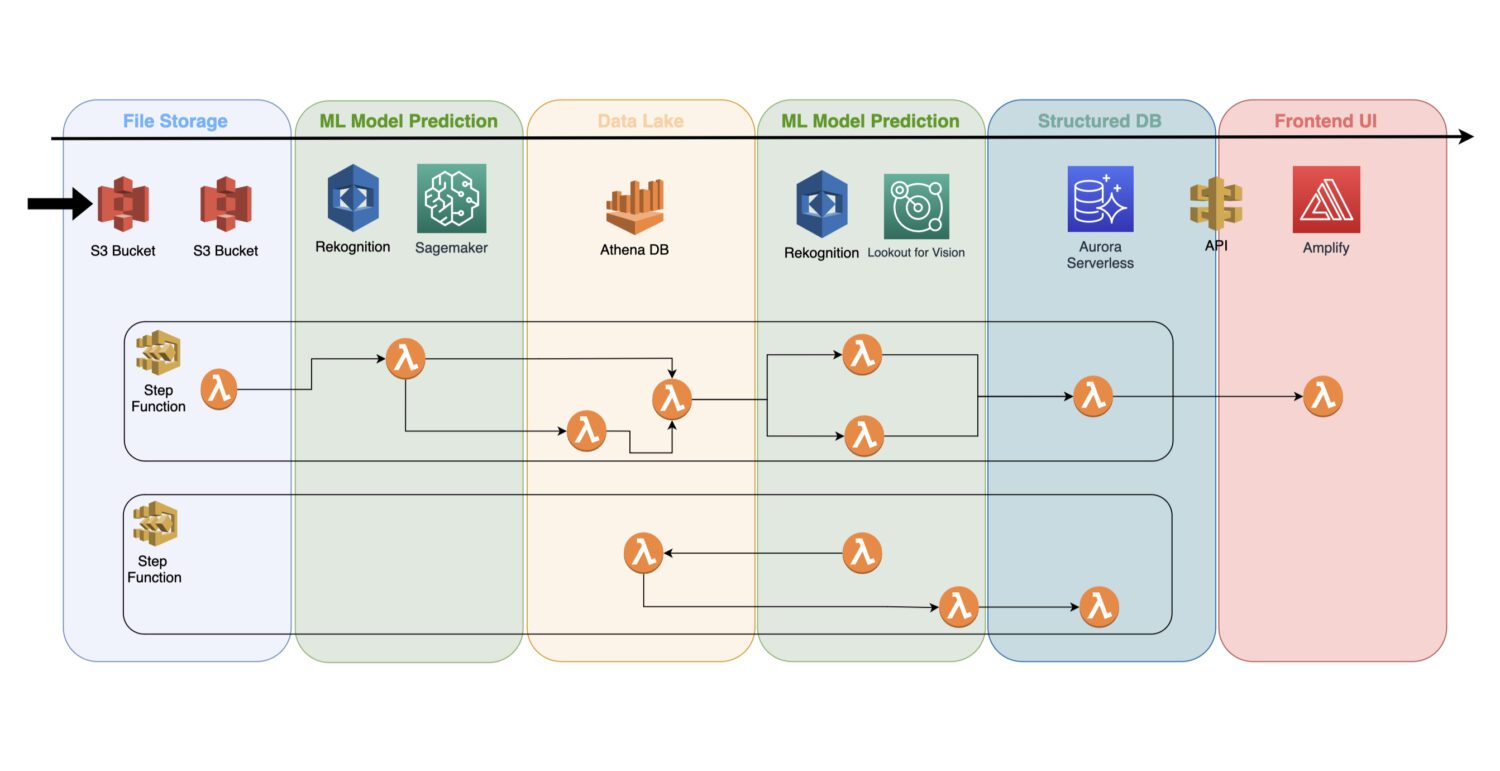
Un modello di apprendimento automatico addestrato è un servizio cloud che non utilizza alcun server cluster in background; pertanto, può essere facilmente incluso in un’architettura serverless esistente.
L’automazione viene eseguita tramite le funzioni lambda AWS, collegate in un lavoro di più passaggi all’interno di un servizio AWS Step Functions.
In genere, è necessario il rilevamento iniziale subito dopo aver raccolto le immagini e la loro pre-elaborazione nel bucket S3. È qui che genererai il rilevamento di anomalie atomiche sulle immagini di input e salverai i risultati in un data lake, ad esempio, rappresentato dal database Athena.
In alcuni casi, questo rilevamento iniziale non è sufficiente per il tuo caso d’uso concreto. Potrebbe essere necessario un altro rilevamento più dettagliato. Ad esempio, il modello iniziale (ad es. Riconoscimento) può rilevare qualche problema sul dispositivo, ma non è possibile identificare in modo affidabile quale tipo di problema sia.
Per questo, potresti aver bisogno di un altro modello con capacità diverse. In tal caso, è possibile eseguire l’altro modello (ad esempio Lookout for Vision) sul sottoinsieme di immagini in cui il modello iniziale ha identificato il problema.
Questo è anche un buon modo per risparmiare sui costi, poiché non è necessario eseguire il secondo modello su un intero set di immagini. Invece, lo esegui solo sul sottoinsieme significativo.
Le funzioni AWS Lambda copriranno tutte queste elaborazioni utilizzando il codice Python o Javascript all’interno. Dipende solo dalla natura dei processi e da quante funzioni AWS lambda dovrai includere all’interno di un flusso. Il limite di 15 minuti per la durata massima di una chiamata lambda AWS determinerà quanti passaggi deve contenere tale processo.
Parole finali
Lavorare con i modelli di machine learning nel cloud è un lavoro molto interessante. Se lo guardi dal punto di vista delle competenze e delle tecnologie, scoprirai che devi avere un team con una grande varietà di competenze.
Il team deve capire come addestrare un modello, sia esso pre-costruito o creato da zero. Ciò significa che molta matematica o algebra è coinvolta nel bilanciare l’affidabilità e le prestazioni dei risultati.
Sono inoltre necessarie alcune competenze avanzate di codifica in Python o Javascript, database e competenze SQL. E dopo che tutto il lavoro sui contenuti è stato completato, sono necessarie competenze DevOps per collegarlo a una pipeline che lo renderà un lavoro automatizzato pronto per la distribuzione e l’esecuzione.
Definire l’anomalia e addestrare il modello è una cosa. Ma è una sfida integrare tutto in un unico team funzionale in grado di elaborare i risultati dei modelli e salvare i dati in modo efficace e automatizzato per servirli agli utenti finali.
Quindi, controlla tutto sul riconoscimento facciale per le aziende.