

Il trattamento dei big data è una delle procedure più complesse che le organizzazioni devono affrontare. Il processo diventa più complicato quando si dispone di un grande volume di dati in tempo reale.
In questo post scopriremo cos’è l’elaborazione dei big data, come viene eseguita ed esploreremo Apache Kafka e Spark, i due strumenti di elaborazione dati più famosi!
Sommario:
Che cos’è il trattamento dei dati? Com’è fatto?
Per trattamento dei dati si intende qualsiasi operazione o insieme di operazioni, anche se non eseguite mediante un processo automatizzato. Può essere pensato come la raccolta, l’ordinamento e l’organizzazione delle informazioni secondo una disposizione logica e appropriata per l’interpretazione.
Quando un utente accede a un database e ottiene risultati per la sua ricerca, è l’elaborazione dei dati che sta ottenendo i risultati di cui ha bisogno. Le informazioni estratte come risultato della ricerca sono il risultato dell’elaborazione dei dati. Ecco perché la tecnologia dell’informazione ha il fulcro della sua esistenza incentrata sull’elaborazione dei dati.
L’elaborazione tradizionale dei dati è stata effettuata utilizzando un semplice software. Tuttavia, con l’emergere dei Big Data, le cose sono cambiate. I Big Data si riferiscono a informazioni il cui volume può superare i cento terabyte e i petabyte.
Inoltre, queste informazioni vengono regolarmente aggiornate. Gli esempi includono dati provenienti da contact center, social media, dati di borsa, ecc. Tali dati sono talvolta chiamati anche flusso di dati, un flusso di dati costante e incontrollato. La sua caratteristica principale è che i dati non hanno limiti definiti, quindi è impossibile dire quando il flusso inizia o finisce.
I dati vengono elaborati non appena arrivano a destinazione. Alcuni autori lo chiamano elaborazione in tempo reale o online. Un approccio diverso è l’elaborazione a blocchi, batch o offline, in cui i blocchi di dati vengono elaborati in finestre temporali di ore o giorni. Spesso il batch è un processo che viene eseguito di notte, consolidando i dati di quel giorno. Ci sono casi di finestre temporali di una settimana o addirittura di un mese che generano rapporti obsoleti.
Dato che le migliori piattaforme di elaborazione dei Big Data via streaming sono open source come Kafka e Spark, queste piattaforme consentono l’utilizzo di altre diverse e complementari. Ciò significa che essendo open source, si evolvono più velocemente e utilizzano più strumenti. In questo modo, i flussi di dati vengono ricevuti da altri luoghi a velocità variabile e senza interruzioni.
Ora esamineremo due degli strumenti di elaborazione dati più conosciuti e li confronteremo:
Apache Kafka
Apache Kafka è un sistema di messaggistica che crea applicazioni di streaming con un flusso di dati continuo. Originariamente creato da LinkedIn, Kafka è basato su log; un registro è una forma di archiviazione di base perché ogni nuova informazione viene aggiunta alla fine del file.

Kafka è una delle migliori soluzioni per i big data perché la sua caratteristica principale è il suo elevato throughput. Con Apache Kafka è anche possibile trasformare l’elaborazione batch in tempo reale,
Apache Kafka è un sistema di messaggistica publish-subscribe in cui un’applicazione pubblica e un’applicazione che si iscrive riceve messaggi. Il tempo tra la pubblicazione e la ricezione del messaggio può essere di millisecondi, quindi una soluzione Kafka ha una bassa latenza.
Il lavoro di Kafka
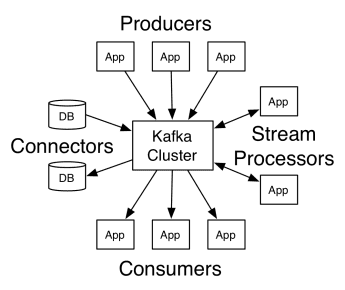
L’architettura di Apache Kafka comprende produttori, consumatori e il cluster stesso. Il produttore è qualsiasi applicazione che pubblica messaggi nel cluster. Il consumatore è qualsiasi applicazione che riceve messaggi da Kafka. Il cluster Kafka è un insieme di nodi che funzionano come una singola istanza del servizio di messaggistica.
 Il lavoro di Kafka
Il lavoro di Kafka
Un cluster Kafka è composto da diversi broker. Un broker è un server Kafka che riceve messaggi dai produttori e li scrive su disco. Ogni broker gestisce un elenco di argomenti e ogni argomento è suddiviso in più partizioni.
Dopo aver ricevuto i messaggi, il broker li invia ai consumatori registrati per ogni argomento.
Le impostazioni di Apache Kafka sono gestite da Apache Zookeeper, che memorizza i metadati del cluster come la posizione della partizione, l’elenco dei nomi, l’elenco degli argomenti e i nodi disponibili. Pertanto, Zookeeper mantiene la sincronizzazione tra i diversi elementi del cluster.
Zookeeper è importante perché Kafka è un sistema distribuito; cioè, la scrittura e la lettura vengono eseguite da più client contemporaneamente. In caso di guasto, Zookeeper elegge un sostituto e recupera l’operazione.
Casi d’uso
Kafka è diventato popolare, soprattutto per il suo utilizzo come strumento di messaggistica, ma la sua versatilità va oltre e può essere utilizzato in una varietà di scenari, come negli esempi seguenti.
Messaggistica
Forma di comunicazione asincrona che disaccoppia le parti che comunicano. In questo modello, una parte invia i dati come messaggio a Kafka, quindi un’altra applicazione li consuma in seguito.
Monitoraggio delle attività
Consente di memorizzare ed elaborare i dati di tracciamento dell’interazione di un utente con un sito Web, come visualizzazioni di pagina, clic, immissione di dati, ecc.; questo tipo di attività genera solitamente un grande volume di dati.
Metrica
Implica l’aggregazione di dati e statistiche da più origini per generare un report centralizzato.
Aggregazione log
Aggrega e archivia centralmente i file di registro provenienti da altri sistemi.
Elaborazione del flusso
L’elaborazione delle pipeline di dati consiste in più fasi, in cui i dati grezzi vengono consumati dagli argomenti e aggregati, arricchiti o trasformati in altri argomenti.
Per supportare queste funzionalità, la piattaforma fornisce essenzialmente tre API:
- Streams API: funge da stream processor che consuma i dati da un argomento, li trasforma e li scrive in un altro.
- Connectors API: consente di collegare argomenti a sistemi esistenti, come database relazionali.
- API di produttori e consumatori: consente alle applicazioni di pubblicare e utilizzare i dati Kafka.
Professionisti
Replicato, partizionato e ordinato
I messaggi in Kafka vengono replicati tra le partizioni nei nodi del cluster nell’ordine in cui arrivano per garantire sicurezza e velocità di consegna.
Trasformazione dei dati
Con Apache Kafka, è persino possibile trasformare l’elaborazione batch in tempo reale utilizzando l’API di flussi ETL batch.
Accesso sequenziale al disco
Apache Kafka mantiene il messaggio su disco e non in memoria, poiché dovrebbe essere più veloce. In effetti, l’accesso alla memoria è più rapido nella maggior parte delle situazioni, specialmente quando si considera l’accesso ai dati che si trovano in posizioni casuali della memoria. Tuttavia, Kafka esegue l’accesso sequenziale e, in questo caso, il disco è più efficiente.
Apache Scintilla
Apache Spark è un motore di elaborazione di big data e un set di librerie per l’elaborazione di dati paralleli tra cluster. Spark è un’evoluzione di Hadoop e del paradigma di programmazione Map-Reduce. Può essere 100 volte più veloce grazie al suo uso efficiente della memoria che non persiste i dati sui dischi durante l’elaborazione.
Spark è organizzato su tre livelli:
- API di basso livello: questo livello contiene le funzionalità di base per eseguire lavori e altre funzionalità richieste dagli altri componenti. Altre importanti funzioni di questo livello sono la gestione della sicurezza, della rete, della pianificazione e dell’accesso logico ai file system HDFS, GlusterFS, Amazon S3 e altri.
- API strutturate: il livello API strutturata si occupa della manipolazione dei dati tramite DataSet o DataFrame, che possono essere letti in formati come Hive, Parquet, JSON e altri. Utilizzando SparkSQL (API che ci consente di scrivere query in SQL), possiamo manipolare i dati nel modo desiderato.
- Alto livello: al livello più alto, abbiamo l’ecosistema Spark con varie librerie, tra cui Spark Streaming, Spark MLlib e Spark GraphX. Sono responsabili dell’acquisizione dello streaming e dei processi circostanti, come il ripristino da crash, la creazione e la convalida dei modelli di apprendimento automatico classici e la gestione di grafici e algoritmi.
Il funzionamento di Spark
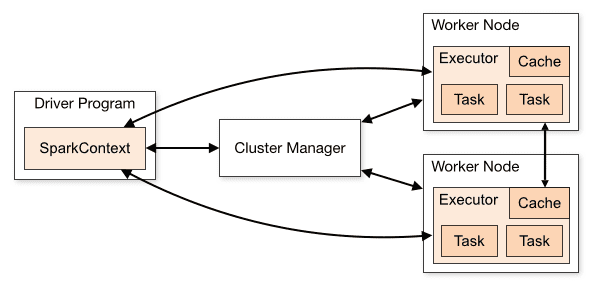
L’architettura di un’applicazione Spark è composta da tre parti principali:
Programma driver: è responsabile dell’orchestrazione dell’esecuzione dell’elaborazione dei dati.
Cluster Manager: è il componente responsabile della gestione delle diverse macchine in un cluster. Necessario solo se Spark è distribuito.
Nodi di lavoro: sono le macchine che eseguono le attività di un programma. Se Spark viene eseguito localmente sul tuo computer, svolgerà un programma driver e un ruolo Workes. Questo modo di eseguire Spark è chiamato Standalone.
 Panoramica del cluster
Panoramica del cluster
Il codice Spark può essere scritto in diverse lingue. La console Spark, denominata Spark Shell, è interattiva per l’apprendimento e l’esplorazione dei dati.
La cosiddetta applicazione Spark è costituita da uno o più Job, consentendo il supporto dell’elaborazione dati su larga scala.
Quando si parla di esecuzione, Spark ha due modalità:
- Client: il driver viene eseguito direttamente sul client, che non passa attraverso Resource Manager.
- Cluster: driver in esecuzione sull’Application Master tramite Resource Manager (in modalità Cluster, se il client si disconnette, l’applicazione continuerà a funzionare).
È necessario utilizzare Spark correttamente in modo che i servizi collegati, come il Resource Manager, possano identificare la necessità di ogni esecuzione, fornendo le migliori prestazioni. Quindi spetta allo sviluppatore conoscere il modo migliore per eseguire i propri lavori Spark, strutturando la chiamata effettuata, e per questo puoi strutturare e configurare gli esecutori Spark nel modo desiderato.
I processi Spark utilizzano principalmente la memoria, quindi è comune regolare i valori di configurazione Spark per gli esecutori del nodo di lavoro. A seconda del carico di lavoro di Spark, è possibile determinare che una determinata configurazione Spark non standard fornisce esecuzioni più ottimali. A tal fine possono essere eseguiti test di confronto tra le varie opzioni di configurazione disponibili e la stessa configurazione predefinita di Spark.
Usa casi
Apache Spark aiuta nell’elaborazione di enormi quantità di dati, in tempo reale o archiviati, strutturati o non strutturati. Di seguito sono riportati alcuni dei suoi casi d’uso popolari.
Arricchimento dei dati
Spesso le aziende utilizzano una combinazione di dati storici sui clienti con dati comportamentali in tempo reale. Spark può aiutare a creare una pipeline ETL continua per convertire i dati degli eventi non strutturati in dati strutturati.
Attiva il rilevamento di eventi
Spark Streaming consente un rilevamento e una risposta rapidi ad alcuni comportamenti rari o sospetti che potrebbero indicare un potenziale problema o frode.
Analisi dei dati di sessioni complesse
Utilizzando Spark Streaming, gli eventi relativi alla sessione dell’utente, come le sue attività dopo l’accesso all’applicazione, possono essere raggruppati e analizzati. Queste informazioni possono anche essere utilizzate continuamente per aggiornare i modelli di machine learning.
Professionisti
Elaborazione iterativa
Se l’attività consiste nell’elaborare i dati ripetutamente, i set di dati distribuiti (RDD) resilienti di Spark consentono più operazioni di mappatura in memoria senza dover scrivere i risultati provvisori sul disco.
Elaborazione grafica
Il modello computazionale di Spark con l’API GraphX è eccellente per i calcoli iterativi tipici dell’elaborazione grafica.
Apprendimento automatico
Spark ha MLlib, una libreria di machine learning integrata che dispone di algoritmi già pronti che vengono eseguiti anche in memoria.
Kafka contro Spark
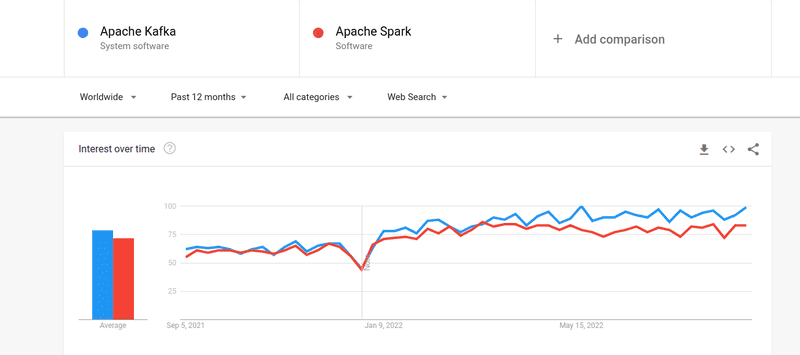
Anche se l’interesse delle persone sia per Kafka che per Spark è stato quasi simile, esistono alcune differenze sostanziali tra i due; diamo un’occhiata.
# 1. Elaborazione dati
Kafka è uno strumento di streaming e archiviazione di dati in tempo reale responsabile del trasferimento dei dati tra le applicazioni, ma non è sufficiente per creare una soluzione completa. Pertanto, sono necessari altri strumenti per attività che Kafka non fa, come Spark. Spark, d’altra parte, è una piattaforma di elaborazione dati batch-first che estrae dati da argomenti Kafka e li trasforma in schemi combinati.
#2. Gestione della memoria
Spark utilizza Robust Distributed Datasets (RDD) per la gestione della memoria. Invece di tentare di elaborare enormi set di dati, li distribuisce su più nodi in un cluster. Al contrario, Kafka utilizza l’accesso sequenziale simile a HDFS e archivia i dati in una memoria buffer.
#3. Trasformazione ETL
Sia Spark che Kafka supportano il processo di trasformazione ETL, che copia i record da un database all’altro, in genere da una base transazionale (OLTP) a una base analitica (OLAP). Tuttavia, a differenza di Spark, che viene fornito con un’abilità integrata per il processo ETL, Kafka si affida all’API Streams per supportarlo.
#4. Persistenza dei dati

L’uso di RRD da parte di Spark consente di archiviare i dati in più posizioni per un uso successivo, mentre in Kafka è necessario definire gli oggetti del set di dati nella configurazione per rendere persistenti i dati.
#5. Difficoltà
Spark è una soluzione completa e più facile da imparare grazie al supporto per vari linguaggi di programmazione di alto livello. Kafka dipende da una serie di diverse API e moduli di terze parti, che possono rendere difficile l’utilizzo.
#6. Recupero
Sia Spark che Kafka forniscono opzioni di ripristino. Spark usa RRD, che gli consente di salvare i dati continuamente e, in caso di errore del cluster, è possibile ripristinarli.

Kafka replica continuamente i dati all’interno del cluster e la replica tra broker, il che consente di passare ai diversi broker in caso di errore.
Somiglianze tra Spark e Kafka
Apache SparkApache KafkaOpenSourceOpenSourceCrea applicazione di streaming di datiCrea applicazione di streaming di datiSupporta l’elaborazione con statoSupporta l’elaborazione con statoSupporta SQLSupporta SQLSomiglianze tra Spark e Kafka
Parole finali
Kafka e Spark sono entrambi strumenti open source scritti in Scala e Java, che consentono di creare applicazioni di streaming di dati in tempo reale. Hanno diverse cose in comune, tra cui elaborazione con stato, supporto per SQL ed ETL. Kafka e Spark possono anche essere utilizzati come strumenti complementari per aiutare a risolvere il problema della complessità del trasferimento dei dati tra le applicazioni.