
Se sei nuovo nell’analisi dei big data, l’host di strumenti Apache potrebbe essere sul tuo radar; tuttavia, l’insieme dei diversi strumenti potrebbe creare confusione e, a volte, opprimere.
Questo post risolverà questa confusione e spiegherà cosa sono Apache Hive e Impala e cosa li rende diversi l’uno dall’altro!
Sommario:
Alveare di Apache
Apache Hive è un’interfaccia di accesso ai dati SQL per la piattaforma Apache Hadoop. Hive consente di interrogare, aggregare e analizzare i dati utilizzando la sintassi SQL.
Uno schema di accesso in lettura viene utilizzato per i dati nel file system HDFS, consentendo di trattare i dati come con una normale tabella o DBMS relazionale. Le query HiveQL vengono tradotte in codice Java per i lavori MapReduce.
Le query Hive sono scritte nel linguaggio di query HiveQL, che si basa sul linguaggio SQL ma non ha il supporto completo per lo standard SQL-92.
Tuttavia, questo linguaggio consente ai programmatori di utilizzare le proprie query quando è scomodo o inefficiente utilizzare le funzionalità di HiveQL. HiveQL può essere esteso con funzioni scalari definite dall’utente (UDF), aggregazioni (codici UDAF) e funzioni di tabella (UDTF).
Come funziona Apache Hive
Apache Hive traduce i programmi scritti in linguaggio HiveQL (vicino a SQL) in una o più attività MapReduce, Apache Tez o Apache Spark. Questi sono tre motori di esecuzione che possono essere lanciati su Hadoop. Quindi, Apache Hive organizza i dati in un array per il file HDFS (Hadoop Distributed File System) per eseguire i processi su un cluster per produrre una risposta.
Le tabelle Apache Hive sono simili ai database relazionali e le unità di dati sono organizzate dall’unità più significativa a quella più granulare. I database sono array composti da partizioni, che possono essere nuovamente suddivise in “secchi”.
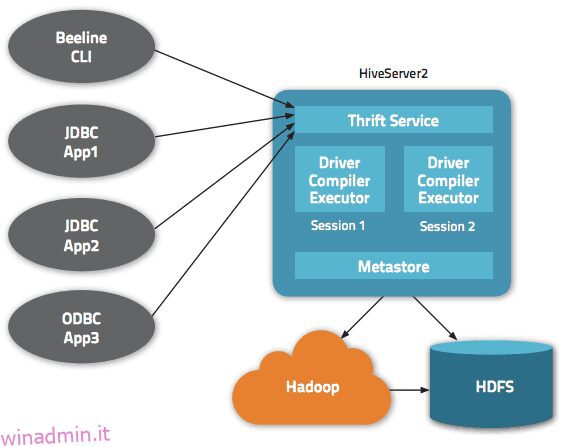
I dati sono accessibili tramite HiveQL. All’interno di ogni database, i dati sono numerati e ogni tabella corrisponde a una directory HDFS.
Sono disponibili più interfacce all’interno dell’architettura Apache Hive, ad esempio interfaccia Web, CLI o client esterni.
Infatti, il server “Apache Hive Thrift” consente ai client remoti di inviare comandi e richieste ad Apache Hive utilizzando vari linguaggi di programmazione. La directory centrale di Apache Hive è un “metastore” che contiene tutte le informazioni.
Il motore che fa funzionare Hive è chiamato “il driver”. Raggruppa un compilatore e un ottimizzatore per determinare il piano di esecuzione ottimale.
Infine, la sicurezza è fornita da Hadoop. Pertanto, si affida a Kerberos per l’autenticazione reciproca tra client e server. L’autorizzazione per i file appena creati in Apache Hive è dettata da HDFS, consentendo l’autorizzazione dell’utente, del gruppo o di altro tipo.
Caratteristiche dell’alveare
- Supporta il motore di elaborazione di Hadoop e Spark
- Utilizza HDFS e funziona come data warehouse.
- Utilizza MapReduce e supporta ETL
- Grazie a HDFS, ha una tolleranza ai guasti simile a Hadoop
Apache Hive: vantaggi
Apache Hive è una soluzione ideale per query e analisi dei dati. Permette di ottenere insight qualitativi, fornendo un vantaggio competitivo e facilitando la reattività alla domanda del mercato.
Tra i principali vantaggi di Apache Hive possiamo citare la facilità d’uso legata al suo linguaggio “SQL-friendly”. Inoltre, velocizza l’inserimento iniziale dei dati poiché i dati non devono essere letti o numerati da un disco nel formato del database interno.
Sapendo che i dati sono archiviati in HDFS, è possibile archiviare set di dati di grandi dimensioni fino a centinaia di petabyte di dati su Apache Hive. Questa soluzione è molto più scalabile di un database tradizionale. Sapendo che si tratta di un servizio cloud, Apache Hive consente agli utenti di avviare rapidamente server virtuali in base alle fluttuazioni dei carichi di lavoro (ovvero attività).
La sicurezza è anche un aspetto in cui Hive offre prestazioni migliori, con la sua capacità di replicare i carichi di lavoro critici per il ripristino in caso di problemi. Infine, la capacità di lavoro è impareggiabile poiché può eseguire fino a 100.000 richieste all’ora.
Apache Impala
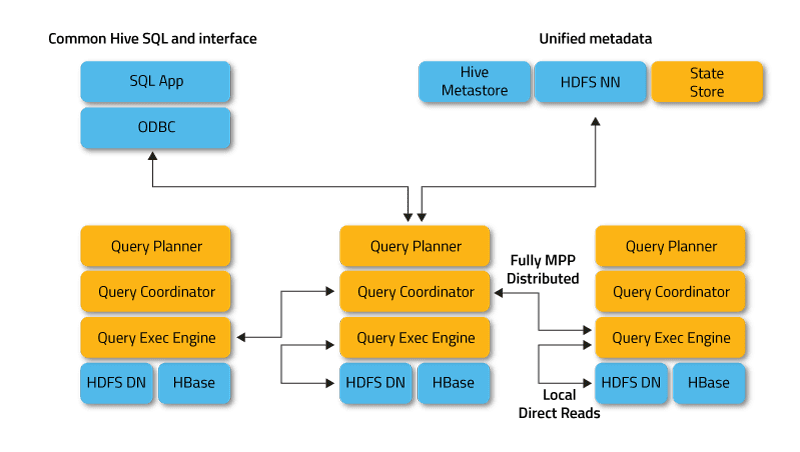
Apache Impala è un motore di query SQL massivamente parallelo per l’esecuzione interattiva di query SQL su dati archiviati in Apache Hadoop, scritto in C++ e distribuito con licenza Apache 2.0.
Impala è anche chiamato un motore MPP (Massively Parallel Processing), un DBMS distribuito e persino un database stack SQL-on-Hadoop.

Impala opera in modalità distribuita, in cui le istanze di processo vengono eseguite su diversi nodi del cluster, ricevendo, programmando e coordinando le richieste dei client. In questo caso è possibile l’esecuzione parallela di frammenti della query SQL.
I client sono utenti e applicazioni che inviano query SQL sui dati archiviati in Apache Hadoop (HBase e HDFS) o Amazon S3. L’interazione con Impala avviene tramite l’interfaccia Web HUE (Hadoop User Experience), ODBC, JDBC e la shell della riga di comando di Impala Shell.
Impala dipende infrastrutturalmente da un altro popolare strumento SQL-on-Hadoop, Apache Hive, utilizzando il suo archivio di metadati. In particolare, Hive Metastore informa Impala sulla disponibilità e sulla struttura dei database.
Durante la creazione, la modifica e l’eliminazione di oggetti dello schema o il caricamento di dati in tabelle tramite istruzioni SQL, le modifiche ai metadati corrispondenti vengono automaticamente propagate a tutti i nodi Impala utilizzando un servizio di directory specializzato.
I componenti chiave di Impala sono i seguenti eseguibili:
- Impalad o Impala daemon è un servizio di sistema che pianifica ed esegue query su dati HDFS, HBase e Amazon S3. Un processo impalad viene eseguito su ciascun nodo del cluster.
- Statestore è un servizio di denominazione che tiene traccia della posizione e dello stato di tutte le istanze impalad nel cluster. Un’istanza di questo servizio di sistema viene eseguita su ciascun nodo e sul server principale (Name Node).
- Catalog è un servizio di coordinamento dei metadati che propaga le modifiche dalle istruzioni Impala DDL e DML a tutti i nodi Impala interessati in modo che le nuove tabelle o i dati appena caricati siano immediatamente visibili a qualsiasi nodo del cluster. Si consiglia di eseguire un’istanza di Catalog sullo stesso host cluster del daemon Statestored.
Come funziona Apache Impala
Impala, come Apache Hive, usa un linguaggio di query dichiarativo simile, Hive Query Language (HiveQL), che è un sottoinsieme di SQL92, invece di SQL.
L’effettiva esecuzione della richiesta in Impala è la seguente:
L’applicazione client invia una query SQL connettendosi a qualsiasi impalad tramite interfacce driver ODBC o JDBC standardizzate. L’impalad connesso diventa il coordinatore della richiesta corrente.
La query SQL viene analizzata per determinare le attività per le istanze impalad nel cluster; quindi, viene creato il piano di esecuzione della query ottimale.
Impalad accede direttamente a HDFS e HBase utilizzando le istanze locali dei servizi di sistema per fornire i dati. A differenza di Apache Hive, tale interazione diretta consente di risparmiare in modo significativo il tempo di esecuzione della query, poiché i risultati intermedi non vengono salvati.
In risposta, ogni demone restituisce i dati all’impalad coordinatore, inviando i risultati al client.
Caratteristiche di Impala
- Supporto per l’elaborazione in memoria in tempo reale
- Compatibile con SQL
- Supporta sistemi di archiviazione come HDFS, Apache HBase e Amazon S3
- Supporta l’integrazione con strumenti BI come Pentaho e Tableau
- Utilizza la sintassi HiveQL
Apache Impala: Vantaggi
Impala evita il possibile sovraccarico di avvio perché tutti i processi del demone di sistema vengono avviati direttamente all’avvio. Risparmia in modo significativo il tempo di esecuzione delle query. Un ulteriore aumento della velocità di Impala è dovuto al fatto che questo strumento SQL per Hadoop, a differenza di Hive, non memorizza i risultati intermedi e accede direttamente a HDFS o HBase.
Inoltre, Impala genera il codice del programma in fase di esecuzione e non durante la compilazione, come fa Hive. Tuttavia, un effetto collaterale delle prestazioni ad alta velocità di Impala è la ridotta affidabilità.
In particolare, se il nodo dati si interrompe durante l’esecuzione di una query SQL, l’istanza Impala verrà riavviata e Hive continuerà a mantenere una connessione all’origine dati, fornendo tolleranza agli errori.
Altri vantaggi di Impala includono il supporto integrato per un protocollo di autenticazione di rete sicuro Kerberos, la definizione delle priorità e la capacità di gestire la coda delle richieste e il supporto per i formati Big Data più diffusi come LZO, Avro, RCFile, Parquet e Sequence.
Hive Vs Impala: somiglianze
Hive e Impala sono distribuiti gratuitamente con la licenza Apache Software Foundation e fanno riferimento a strumenti SQL per lavorare con i dati archiviati in un cluster Hadoop. Inoltre, utilizzano anche il file system distribuito HDFS.
Impala e Hive implementano diverse attività con un focus comune sull’elaborazione SQL dei big data archiviati in un cluster Apache Hadoop. Impala fornisce un’interfaccia simile a SQL, che consente di leggere e scrivere tabelle Hive, consentendo così un facile scambio di dati.
Allo stesso tempo, Impala rende le operazioni SQL su Hadoop abbastanza veloci ed efficienti, consentendo l’utilizzo di questo DBMS nei progetti di ricerca di analisi dei Big Data. Quando possibile, Impala funziona con un’infrastruttura Apache Hive esistente già utilizzata per eseguire query batch SQL di lunga durata.
Inoltre, Impala archivia le definizioni delle tabelle in un metastore, un tradizionale database MySQL o PostgreSQL, ovvero nello stesso luogo in cui Hive archivia dati simili. Consente a Impala di accedere alle tabelle Hive purché tutte le colonne utilizzino i tipi di dati, i formati di file e i codec di compressione supportati da Impala.
Hive Vs Impala: Differenze

Linguaggio di programmazione
Hive è scritto in Java, mentre Impala è scritto in C++. Tuttavia, Impala utilizza anche alcune UDF Hive basate su Java.
Casi d’uso
I data engineer utilizzano Hive nei processi ETL (Extract, Transform, Load), ad esempio, per processi batch a esecuzione prolungata su set di dati di grandi dimensioni, ad esempio negli aggregatori di viaggi e nei sistemi informativi aeroportuali. A sua volta, Impala è destinato principalmente ad analisti e data scientist ed è utilizzato principalmente in attività come la business intelligence.
Prestazione
Impala esegue query SQL in tempo reale, mentre Hive è caratterizzato da una bassa velocità di elaborazione dei dati. Con semplici query SQL, Impala può essere eseguito da 6 a 69 volte più velocemente di Hive. Tuttavia, Hive gestisce meglio le query complesse.
Latenza/velocità effettiva
Il throughput di Hive è significativamente superiore a quello di Impala. La funzione LLAP (Live Long and Process), che abilita il caching delle query in memoria, offre a Hive buone prestazioni di basso livello.
LLAP include servizi di sistema a lungo termine (demoni), che consentono di interagire direttamente con i nodi di dati HDFS e sostituire la struttura di query DAG strettamente integrata (grafico aciclico diretto), un modello di grafo utilizzato attivamente nel calcolo dei Big Data.
Tolleranza ai guasti
Hive è un sistema a tolleranza d’errore che conserva tutti i risultati intermedi. Inoltre influisce positivamente sulla scalabilità, ma porta a una diminuzione della velocità di elaborazione dei dati. A sua volta, Impala non può essere definita una piattaforma tollerante ai guasti perché è più legata alla memoria.
Conversione del codice
Hive genera espressioni di query in fase di compilazione, mentre Impala le genera in fase di esecuzione. Hive è caratterizzato da un problema di “avvio a freddo” al primo avvio dell’applicazione; le query vengono convertite lentamente a causa della necessità di stabilire una connessione all’origine dati.
Impala non ha questo tipo di sovraccarico di avvio. I servizi di sistema necessari (demoni) per l’elaborazione delle query SQL vengono avviati al momento dell’avvio, il che velocizza il lavoro.
Supporto per l’archiviazione
Impala supporta i formati LZO, Avro e Parquet, mentre Hive funziona con Plain Text e ORC. Tuttavia, entrambi supportano i formati RCFIle e Sequence.
Apache HiveApache ImpalaCasi d’uso del linguaggio JavaC++Ingegneria dei datiAnalisi e analisiPrestazioniElevata per query semplici Latenza relativamente bassaPiù latenza grazie alla memorizzazione nella cacheTolleranza ai guasti latente inferiorePiù tollerante grazie a MapReduceMeno tollerante grazie a MPPConversioneLenta a causa dell’avvio a freddoConversione più rapidaSupporto per l’archiviazioneTesto normale e ORCLZO, Avro, Parquet
Parole finali
Hive e Impala non competono, ma si completano efficacemente a vicenda. Anche se ci sono differenze significative tra i due, c’è anche molto in comune e la scelta dell’uno rispetto all’altro dipende dai dati e dai requisiti particolari del progetto.
Puoi anche esplorare i confronti diretti tra Hadoop e Spark.
.