
Apache Cassandra è un database distribuito NoSQL open source.
Sommario:
Cos’è Apache Cassandra?
Prima di essere reso open source, Apache Cassandra è stato progettato inizialmente su Facebook (ora Meta) per combinare le funzionalità di DynamoDB di Amazon e Bigtable di Google.
È ampiamente utilizzato da aziende come Netflix, Uber e Facebook per la sua elevata disponibilità e scalabilità.
Questo articolo esaminerà come è strutturato Apache Cassandra, come funziona e le diverse funzionalità e vantaggi dell’utilizzo come parte del tuo stack tecnologico.
Cos’è NoSQL?
Apache Cassandra rientra nel gruppo di database noti come database NoSQL. A differenza dei database relazionali o SQL, i database NoSQL non utilizzano SQL o le relazioni come fanno i database SQL.
Ciò crea vantaggi in termini di facilità d’uso e flessibilità, sacrificando al tempo stesso la possibilità di eseguire query più avanzate. Tuttavia, sia i database NoSQL che SQL hanno i loro posti in cui ognuno brilla.
Come funziona Apache Cassandra?
Cassandras viene eseguito utilizzando Cassandra Query Language (CQL), che è sintatticamente molto simile a Structured Query Language (SQL) utilizzato dai database relazionali.
Tuttavia, non supporta alcune funzionalità, come i join, presenti nella maggior parte dei database relazionali. Questo perché Cassandra è un database basato su query. Ciò significa che il database è progettato in base alle query che verranno effettuate.
Le tabelle vengono quindi create per fornire dati sufficienti per ogni query senza dover unire più tabelle. Questo lo rende veloce. Può essere installato su tutti i principali sistemi operativi.
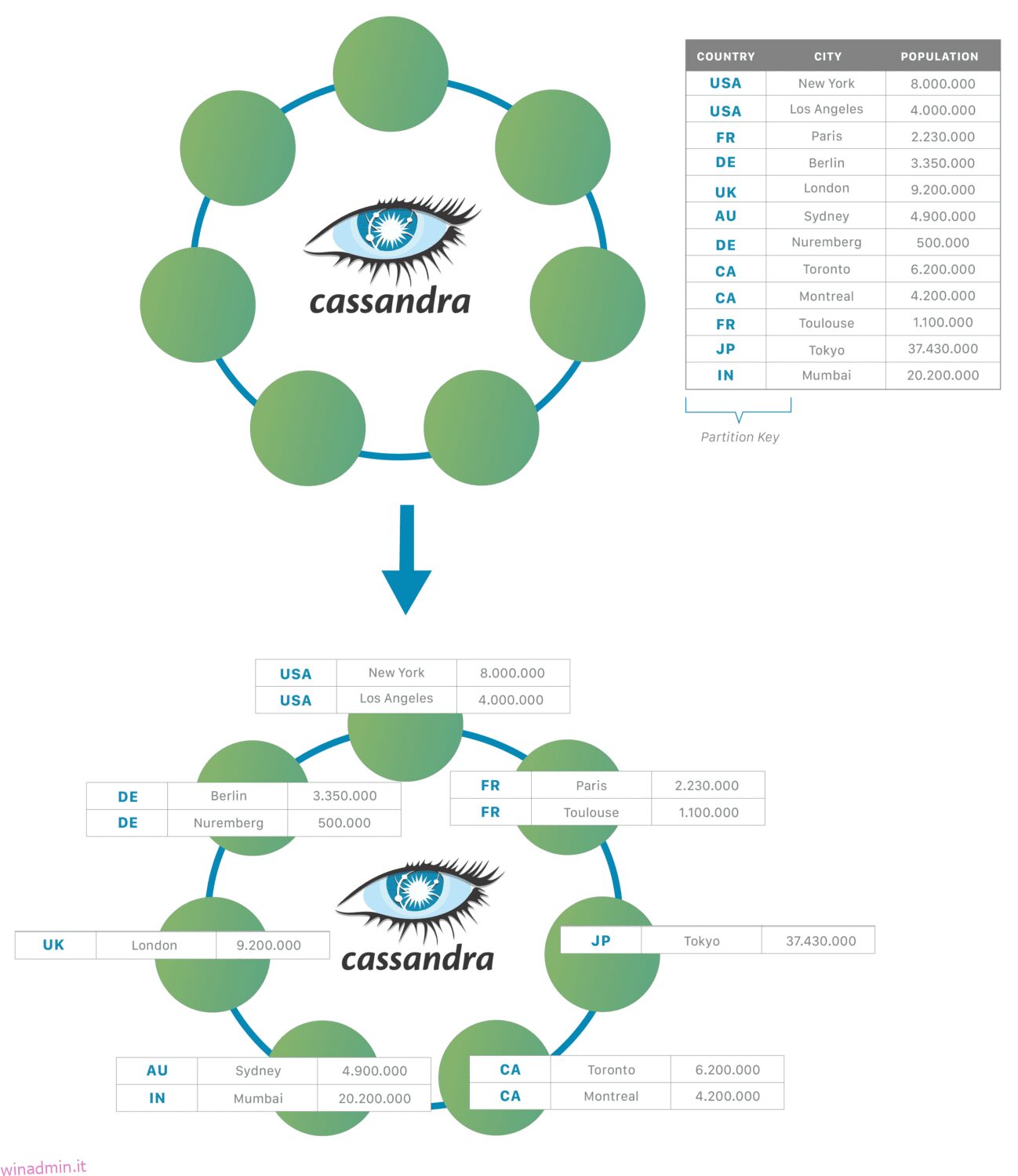
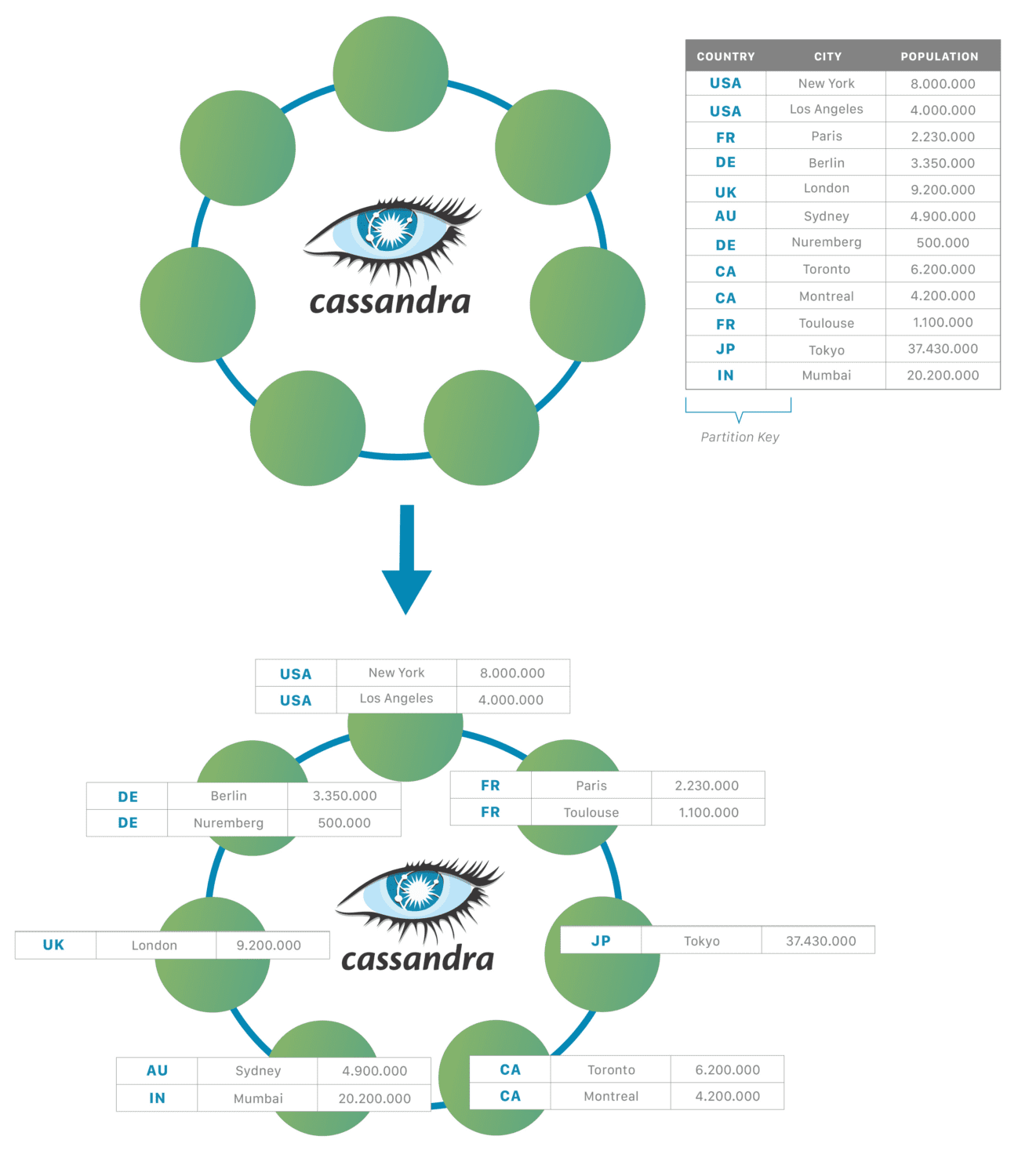
Architettura di Cassandra
Al livello più elementare, Cassandra è composta da nodi. I dati vengono archiviati nei nodi e tutti i record con la stessa chiave vengono archiviati nello stesso nodo. Questo rende l’esecuzione delle query più veloce rispetto ai database SQL, dove più tabelle possono essere in esecuzione su più macchine.
 Fonte: cassandra.apache.org
Fonte: cassandra.apache.org
I dati vengono replicati tra i nodi per l’alta disponibilità da un fattore di replica specificato dal creatore del database. Un gruppo di nodi che memorizzano tutti i dati in un database è chiamato data center.
Un gruppo di data center forma un cluster. Avere più data center significa che i dati sono sempre disponibili anche quando un data center va inaspettatamente offline.
Caratteristiche di Apache Cassandra
Tra i fattori più importanti e differenzianti di Apache Cassandra e altre opzioni sul mercato ci sono:
#1. Open Source
Apache Cassandra è gratuito e open-source. Ciò significa che il codice sorgente è disponibile online, il che rende meno probabile che contenga bug e vulnerabilità che non sono già stati scoperti e corretti.
Questo è importante perché i dati degli utenti e dell’azienda sono risorse importanti che devono essere salvaguardate.
#2. Utilizza l’architettura a colonne larghe
A differenza della maggior parte dei database che archiviano i dati in file a seconda della tabella in cui si trovano i dati, Apache Cassandra archivia per colonna.
Questo rende la ricerca di un valore in una colonna più veloce perché non deve cercare l’intera riga. Di conseguenza, le ricerche di dati di Cassandra sono veloci quanto l’utilizzo di indici in altri database.
#3. Distribuito
Apache Cassandra è distribuito, il che significa che non funziona su una singola macchina. Ciò aiuta a garantire un’elevata disponibilità dei dati perché viene replicata su diversi nodi e data center. Rende inoltre più rapido l’accesso ai dati quando i data center sono geograficamente più vicini all’utente.
#4. Progettazione Query-First
Nella progettazione di database tradizionali, le tabelle sono modellate attorno alle entità. Attraverso la normalizzazione, le relazioni tra queste entità vengono quindi stabilite e create nei database.
Spesso durante le query, le relazioni si estendono su più tabelle. Quando queste tabelle sono memorizzate su macchine diverse, l’accesso ai dati può essere lento.
Tuttavia, con Cassandra, crei tabelle in base alle query che intendi eseguire. Tutti i dati necessari per soddisfare tale query vengono quindi archiviati in una tabella.
Vantaggi di Apache Cassandra
- È gratuito: il sistema di gestione del database stesso è gratuito e può essere scaricato dal sito Web ufficiale di Apache Cassandra. Tuttavia, l’infrastruttura del server su cui viene eseguito il database non lo è.
- Altamente disponibile: Apache Cassandra è progettato pensando alla resilienza. È progettato con una ridondanza sufficiente per rimanere funzionante quando parti del database vanno offline.
- È scalabile: è possibile aggiungere ulteriori nodi al database e la capacità di archiviazione può essere espansa con tempi di inattività minimi o nulli. Questo è l’ideale per la creazione di applicazioni ad alto volume.
- È più veloce: grazie all’architettura a colonne larghe e al design basato sulle query, Apache Cassandra può eseguire più velocemente rispetto ad altri sistemi di gestione dei database.
Ora esploreremo alcune delle migliori risorse di apprendimento per comprendere Apache Cassandra.
Risorse di apprendimento
#1. Apache Cassandra: tutto quello che c’è da sapere
Questo corso Udemy su Apache Cassandra ti accompagnerà da lezioni per principianti a pro, coprendo argomenti dalla panoramica teorica di Cassandra al Cassandra Query Language.
L’unico requisito per questo corso è che tu abbia familiarità con i database in generale e con i sistemi Linux.
#2. Diventa uno sviluppatore Cassandra certificato: esami pratici

Questo corso di certificazione comprende due esami che ti aiuteranno a prepararti e ad esercitarti per l’esame di certificazione per sviluppatori Apache Cassandra di Datastax Academy.
Ogni esame dura novanta minuti e copre argomenti di Architettura, Modellazione e Cassandra Query Langauge. Il pubblico ideale per questo corso sono gli sviluppatori che già conoscono Cassandra ma stanno cercando di ottenere certificazioni professionali.
#3. Elementi essenziali di Apache Cassandra
Questo libro per sviluppatori ti insegna come iniziare con Apache Cassandra. Insegna ai lettori come installare Cassandra e configurare un cluster di database. Successivamente, imparerai il Cassandra Query Language per interagire con il tuo database.
Imparerai anche gli strumenti che puoi utilizzare per monitorare il tuo cluster ed eseguire il debug delle query. È l’ideale per chi non ha mai lavorato con Cassandra prima e sta cercando di iniziare.
#4. Padroneggiare Apache Cassandra
Scritto per persone con una certa conoscenza di Cassandra, questo libro insegna ai lettori a scrivere programmi Cassandra più efficienti e configurare Cassandra per essere più performante.
Inoltre, insegna come integrare Apache Cassandra con Apache Spark per creare sistemi di analisi dei dati.
Parole finali
Apache Cassandra è una scelta potente per un database in sistemi distribuiti su larga scala. La sua affidabilità, scalabilità e velocità lo rendono un’opzione preferita tra i giganti della tecnologia.
L’apprendimento e la padronanza di questo database ti forniranno le competenze per creare sistemi software che servano in modo affidabile milioni di utenti.
Successivamente, puoi controllare gli strumenti di monitoraggio di Apache Cassandra per tenere d’occhio le prestazioni del database.