
Costruire un sistema software automatizzato significava configurare più server con configurazione della CPU dedicata, memoria, storage e altre risorse per molti anni. Successivamente, è stato formato un team di amministratori per gestire questi sistemi. Quindi il team di sviluppo ha rilevato l’infrastruttura e ha iniziato a creare processi che collegano i server.
Questo processo può essere complicato perché coinvolge molti gruppi diversi che lavorano insieme per un obiettivo comune. Questi conflitti di interesse possono quindi essere un problema.
Può anche essere piuttosto costoso. Ciò richiede che tu abbia amministratori sul tuo libro paga. I server, che funzionano continuamente, consumano risorse nonostante non vengano utilizzati.
Per mantenere le migliori prestazioni nel tempo, è necessaria una soluzione di scalabilità automatica che ridimensioni automaticamente le risorse del server.
La piattaforma cloud ha un vantaggio: consente di creare un’architettura end-to-end senza la necessità di configurare un cluster di server. Dal punto di vista dell’amministrazione, non c’è nulla da mantenere.
Questa è un’opzione conveniente per le startup e le fasi di prodotto minimo vitale (MVP) dei progetti. È un buon punto di partenza se è difficile prevedere i futuri carichi di produzione e l’attività degli utenti. È qui che può essere difficile determinare la configurazione dei server del cluster.
L’automazione dei processi attraverso servizi cloud serverless è ciò che distingue l’architettura serverless. Collega i servizi e produce risultati simili ai server cluster tradizionali.
Questo è un esempio di creazione di un’architettura di questo tipo utilizzando solo servizi AWS nativi.
Sommario:
Prelievo del flusso serverless dei servizi
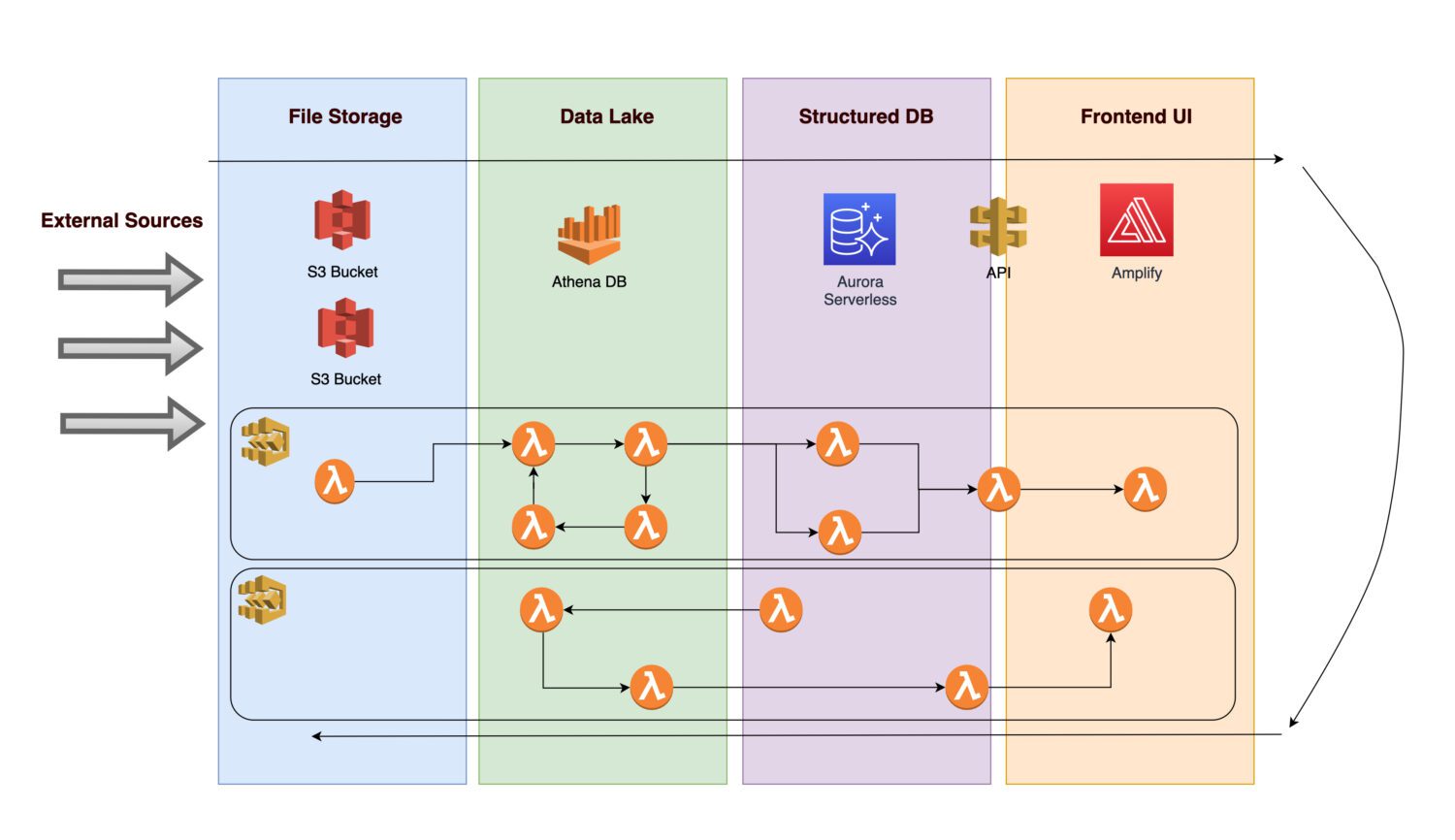
Immagina di voler creare una piattaforma per raccogliere vari dati e immagini (o foto) di alcune infrastrutture di beni concreti (questo può essere qualsiasi bene di produzione o di utilità).
- Per rendere possibile l’analisi futura, è necessario che i dati in entrata vengano prima acquisiti.
- Dopo aver applicato le regole aziendali, una procedura di back-end salva gli output calcolati come informazioni normalizzate in un database relazionale.
- Un front-end dell’applicazione che visualizza dati puliti normalizzati consente agli utenti di visualizzare i risultati.
Esaminiamo quali componenti potrebbe includere l’architettura.
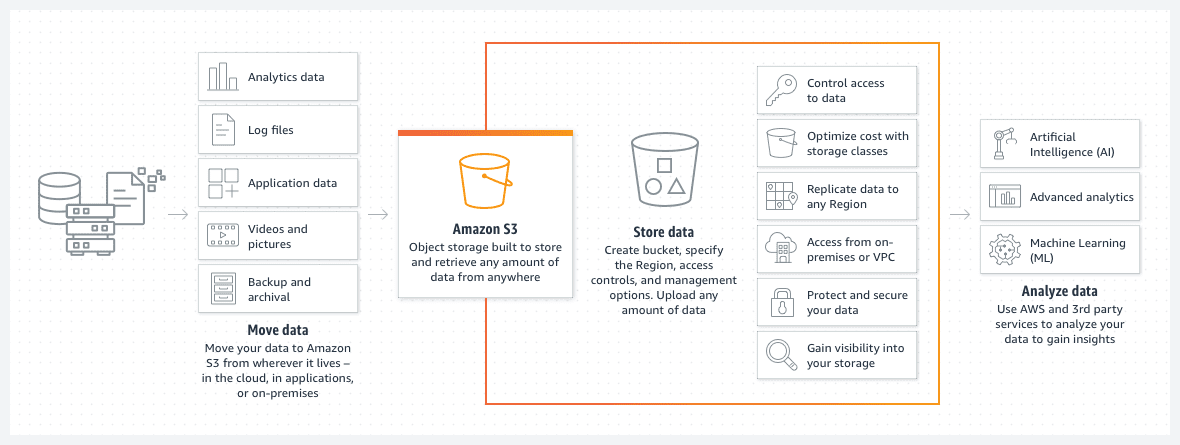
Bucket AWS S3
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
I bucket Amazon S3 sono un ottimo modo per archiviare file o immagini nel cloud AWS. Il prezzo dello storage sul bucket S3 è notevolmente basso. Inoltre, l’introduzione di una politica del ciclo di vita del bucket S3 abbassa ulteriormente questo prezzo.
Tale policy sposterà automaticamente i file più vecchi in diverse classi di bucket S3, come un archivio o un accesso deep archive. Le classi differiscono quindi anche per la velocità del tempo di accesso, ma per i vecchi dati questo sarà un problema minore. Serve principalmente per accedere ai dati archiviati in caso di un evento urgente piuttosto che per esigenze operative standard.
- Puoi organizzare i tuoi dati in sottocartelle.
- È necessario impostare le restrizioni di autorizzazioni appropriate.
- Aggiungi tag ai bucket per renderli facili da identificare e per un possibile utilizzo all’interno delle policy dinamiche dei bucket S3.
- Il bucket è serverless per progettazione. È semplicemente uno spazio di archiviazione per i tuoi dati.
Un bucket S3 è serverless per progettazione. È semplicemente uno spazio di archiviazione per i tuoi dati.
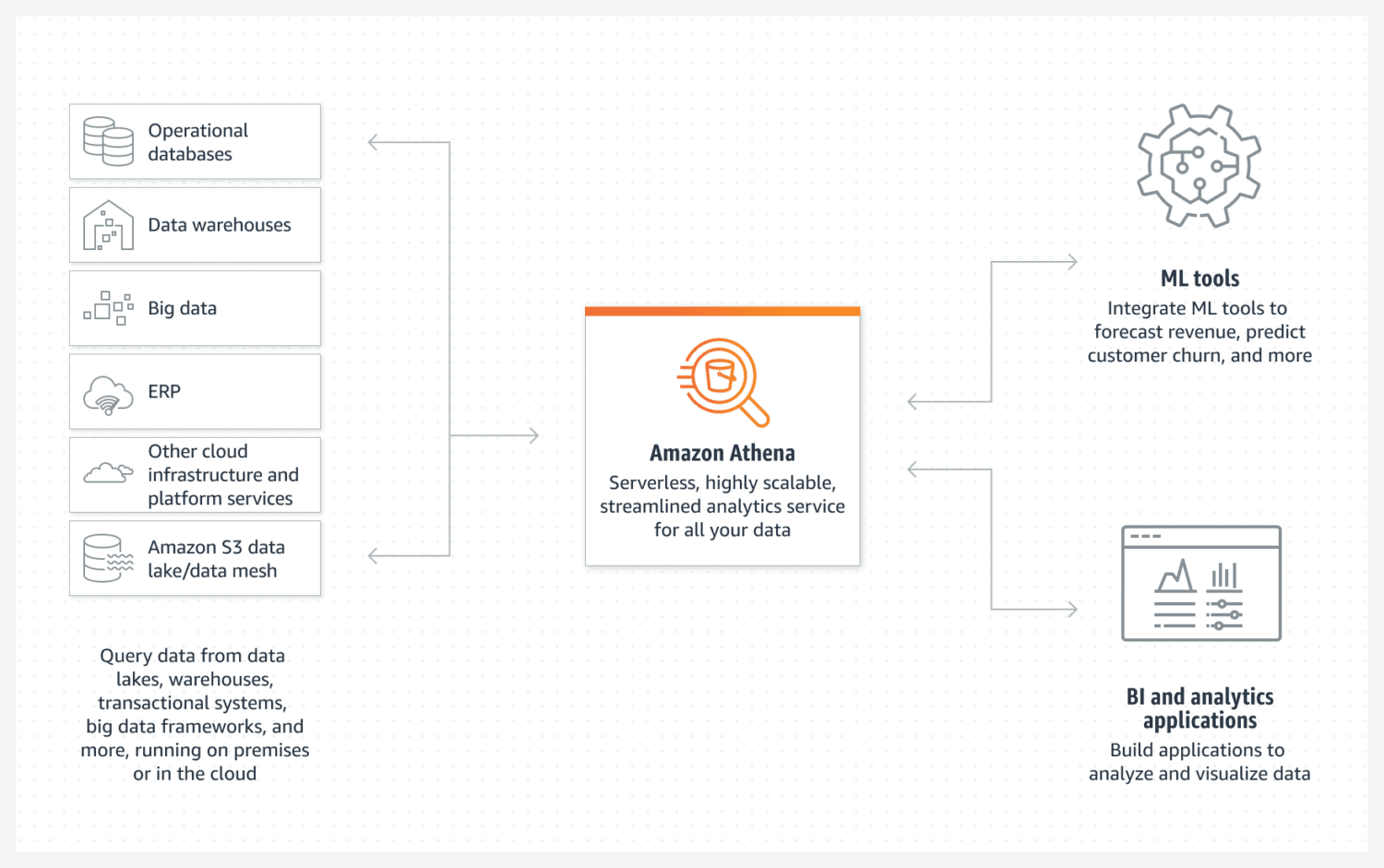
Database AWS Athena
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Athena semplifica la creazione di un data lake di base AWS. È un database senza server che utilizza un bucket S3 per archiviare i propri dati. L’organizzazione dei dati è gestita da formati di file strutturati come parquet o file con valori separati da virgola (CSV). Il bucket S3 contiene i file e Athena vi fa riferimento ogni volta che i processi selezionano i dati dal database.
Basta essere consapevoli del fatto che Athena non supporta varie funzionalità altrimenti considerate standard, ad esempio le istruzioni di aggiornamento. Questo è il motivo per cui devi considerare Athena come un’opzione molto semplice.
Tuttavia, supporta l’indicizzazione e il partizionamento. Può anche scalare orizzontalmente molto facilmente, poiché è complesso quanto l’aggiunta di nuovi bucket all’infrastruttura. Per la creazione di data lake semplici ma funzionali, questo può ancora essere sufficiente nella maggior parte dei casi.
Per ottenere buone prestazioni, è essenziale selezionare la migliore progettazione dei dati con particolare attenzione all’utilizzo futuro. È essenziale essere molto chiari sul modo in cui si desidera selezionare i dati. Ricreare le tabelle in un secondo momento una volta che sono già esistenti e piene di molti dati è difficile.
Athena DB è un’ottima scelta e si adatta bene al tuo obiettivo se stai cercando di creare un pool di dati semplice e immutabile che sia facile da scalare orizzontalmente nel tempo.
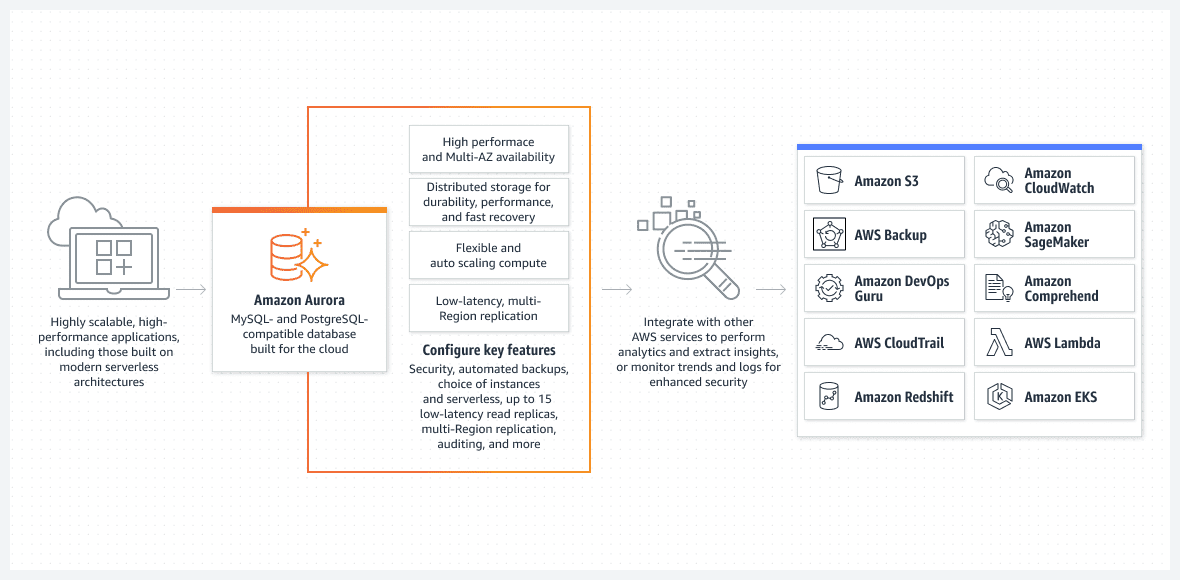
Database AWS Aurora
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Athena DB eccelle nell’archiviazione di dati non curati. Dopotutto, è così che vuoi archiviare i tuoi contenuti originali per massimizzarne il riutilizzo futuro. Tuttavia, è lento fornire risultati selezionati a un’app front-end.
Una delle migliori opzioni, principalmente dal punto di vista della configurazione facile da eseguire, è il database Aurora in esecuzione in modalità serverless.
Aurora è tutt’altro che un database di base. È una delle soluzioni di database relazionali native più avanzate in AWS. È anche una soluzione di database relazionale nativa altamente complessa che migliora a ogni rilascio.
Aurora è unico perché può essere eseguito in modalità serverless, distinguendosi dagli altri servizi relazionali. Ecco come funziona la modalità:
- Per configurare il cluster Aurora, utilizza la console AWS. Sarà necessario specificare i livelli di CPU e RAM standard nonché l’intervallo massimo della funzionalità di ridimensionamento automatico. Ciò influirà sulle prestazioni che il cluster Aurora può aggiungere o rimuovere dinamicamente. In base all’utilizzo corrente del database, AWS decide di aumentare o diminuire le dimensioni.
- Il cluster Aurora non si avvierà a meno che l’utente o il processo non avvii una richiesta reale. Ad esempio, quando inizia l’elaborazione batch pianificata. O se l’applicazione esegue una chiamata API back-end per recuperare i dati da un database. Il database si aprirà automaticamente e rimarrà attivo per un tempo prestabilito dopo il completamento dei processi di richiesta.
- Il cluster Aurora si spegnerà automaticamente se non c’è più lavoro nel database.
Per sottolinearlo ancora una volta, Aurora DB serverless viene eseguito solo quando deve svolgere un lavoro reale. Il cluster avviato automaticamente verrà nuovamente arrestato se non sta elaborando alcun lavoro. Il lavoro effettivo è ciò per cui paghi e non il tuo tempo libero.
Il serverless Aurora è completamente gestito da AWS e non richiede un amministratore.
Amplifica AWS
Amplify offre una piattaforma serverless per la rapida implementazione di applicazioni front-end realizzate con librerie JavaScript e React. Non è necessario configurare i server del cluster. Utilizza la console AWS per distribuire direttamente il codice o utilizza una pipeline DevOps automatizzata.
Puoi chiamare le API di back-end per raggiungere i dati archiviati nei database. Queste chiamate consentono di accedere ai dati effettivi nell’applicazione front-end. L’ottimizzazione principale delle prestazioni sul back-end dovrebbe essere eseguita dal team. Puoi ridurre ulteriormente la possibilità di una risposta lenta nell’interfaccia utente se progetti istruzioni select efficaci direttamente all’interno delle chiamate API.
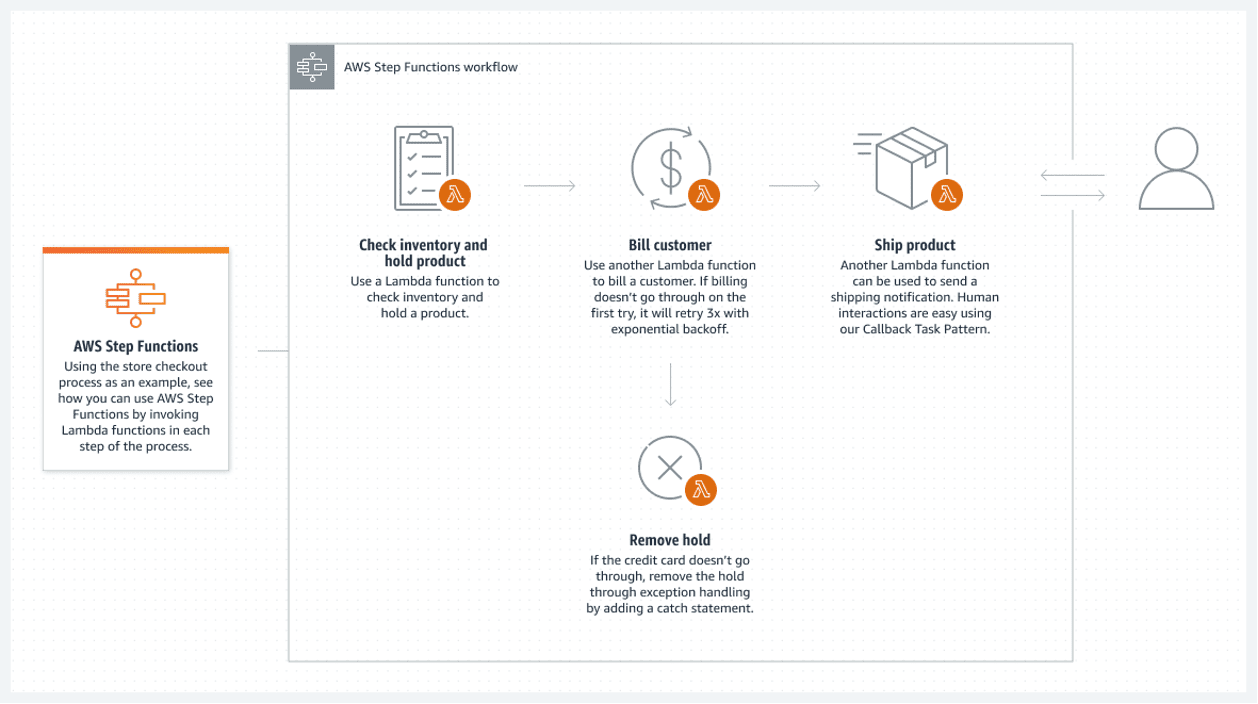
Funzioni AWS Step
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Anche se tutti i principali componenti di un sistema sono serverless, ciò non garantisce un’architettura completamente serverless. Questo è possibile solo se tutti i processi batch tra i componenti sono senza server.
Le funzioni AWS Step forniscono la migliore soluzione sul cloud AWS. Un elenco connesso di funzioni AWS Lambda costituisce la funzione step. Queste funzioni creano un diagramma di flusso con stati iniziali e finali chiari. Una funzione lambda, solitamente scritta in linguaggio Python o Node JS, è un bit di codice eseguibile che elabora tutto ciò che è necessario.
Di seguito è riportato un esempio di come eseguire una funzione step:
Questo flusso serverless ha un grosso svantaggio: ogni funzione lambda può essere eseguita solo per 15 minuti al massimo. Pertanto, suddividere il flusso in funzioni lambda più piccole può renderlo meno problematico.
È possibile chiamare più funzioni lambda contemporaneamente in un passaggio, il che significa sostanzialmente parallelizzare un passaggio con più lambda eseguiti contemporaneamente. Attendi solo il completamento di tutta l’elaborazione lambda parallela prima di continuare. Quindi, procedere alla successiva elaborazione lambda.
Parole finali
L’architettura serverless offre un’opportunità unica per creare una piattaforma cloud che copra l’intero panorama del sistema. Questa piattaforma è scalabile orizzontalmente e ha bassi costi operativi.
È la soluzione perfetta per progetti con limiti di budget. È un’eccellente opzione di esplorazione, in genere quando nessuno conosce la realtà del carico di produzione. Ciò è particolarmente importante dopo aver eseguito correttamente l’onboarding di tutti gli utenti. È possibile per i team di progetto avere comunque una visione d’insieme di come funziona il sistema. Puoi avere tutti questi vantaggi senza dover scendere a compromessi.
Questa copertura non sarà adeguata per tutti i casi, in particolare quelli che comportano un elevato utilizzo della CPU. Tuttavia, il cloud AWS è in continua evoluzione in termini di casi d’uso serverless. Di solito è una buona idea condurre ricerche approfondite prima di decidere sull’opzione serverless per il tuo prossimo progetto cloud AWS.
Successivamente, controlla i migliori database serverless per le applicazioni moderne.