
Prometheus è un sistema di monitoraggio open source basato su metriche. Raccoglie dati da servizi e host inviando richieste HTTP su endpoint di metriche. Quindi memorizza i risultati in un database di serie temporali e lo rende disponibile per analisi e avvisi.
Sommario:
Perché monitorare?
- Abilita gli avvisi quando le cose vanno male, preferibilmente prima che vadano male. In modo che qualcuno possa dargli un’occhiata.
- Fornisce approfondimenti per consentire l’analisi, il debug e la risoluzione del problema.
- Ti consente di vedere tendenze/cambiamenti nel tempo. Ad esempio, quante sessioni attive in un dato momento. Questo aiuta nelle decisioni di progettazione e nella pianificazione della capacità.
Il monitoraggio di solito si riferisce agli eventi. Un evento potrebbe includere la ricezione di una richiesta HTTP, l’invio di una risposta, la lettura dal disco, l’accesso di un utente. Il monitoraggio di un sistema può includere profilazione, registrazione, tracciamento, metriche, avvisi e visualizzazione.
Monitoraggio Blackbox vs. Whitebox
Il monitoraggio rientra in due categorie principali:
Monitoraggio della scatola nera
Nel monitoraggio di Blackbox, il monitoraggio è a livello di applicazione o host mentre vengono osservati dall’esterno. Questo può essere piuttosto limitante.
Monitoraggio della scatola bianca
Il monitoraggio di Whitebox significa monitorare l’interno di un servizio. Espone i dati sullo stato e le prestazioni dei componenti interni.
I quattro segnali d’oro
Secondo Googlese puoi misurare solo quattro parametri del tuo sistema rivolto all’utente, concentrati sui seguenti quattro, chiamati i quattro segnali d’oro:
#1. Latenza
Il tempo necessario per servire una richiesta, riuscita o fallita. È importante tenere traccia non solo delle richieste andate a buon fine, ma anche di quelle fallite.
#2. Traffico
Una misura di quanta domanda viene immessa sul tuo sistema. Per un servizio Web, si tratta in genere di richieste HTTP al secondo.
#3. Errori
La percentuale di richieste non riuscite.
#4. Saturazione
Quanto è completo il tuo servizio. L’aumento della latenza è spesso un importante indicatore di saturazione. Molti sistemi degradano le prestazioni molto prima di raggiungere il 100% di utilizzo.
Tipi di metriche Prometheus
Le metriche di Prometheus sono di quattro tipi principali:
#1. Contatore
Il valore di un contatore aumenterà sempre. Non può mai diminuire, ma può essere azzerato. Quindi, se uno scrape fallisce, significa solo un datapoint mancato. L’aumento cumulativo sarebbe disponibile alla prossima lettura. Esempi:
- Numero totale di richieste HTTP ricevute
- Il numero di eccezioni.
#2. Misura
Un misuratore è un’istantanea in un dato momento. Può sia aumentare che diminuire. Se il recupero dei dati fallisce, perdi un campione; il recupero successivo potrebbe mostrare un valore diverso: esempi di spazio su disco, utilizzo della memoria.
#3. Istogramma
Un istogramma campiona le osservazioni e le conta in bucket configurabili. Sono usati per cose come la durata della richiesta o le dimensioni della risposta. Ad esempio, puoi misurare la durata della richiesta per una specifica richiesta HTTP. L’istogramma avrà una serie di intervalli, ad esempio 1 ms, 10 ms e 25 ms. Anziché archiviare ogni durata per ogni richiesta, Prometheus memorizzerà la frequenza delle richieste che rientrano in un particolare bucket.
#4. Riepilogo
Simile alle osservazioni dei campioni di istogrammi, in genere richiedono durate o dimensioni di risposta. Fornirà un conteggio totale delle osservazioni e una somma di tutti i valori osservati, consentendo di calcolare la media dei valori osservati. Ad esempio, in un minuto hai avuto tre richieste che hanno richiesto 2,3,4 secondi. La somma sarebbe 9 e il conteggio sarebbe 3. La latenza sarebbe 3 secondi.
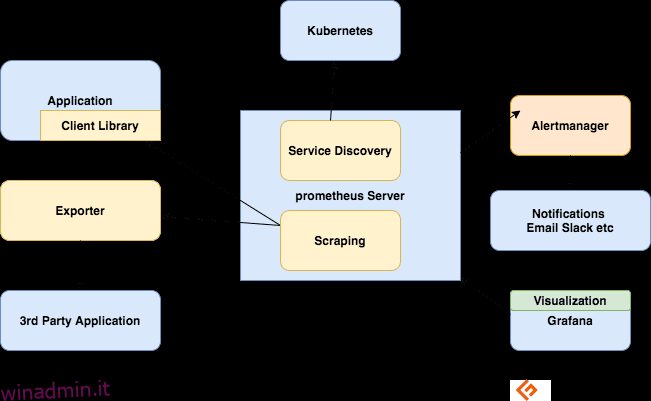
Componenti dell’ecosistema Prometeo
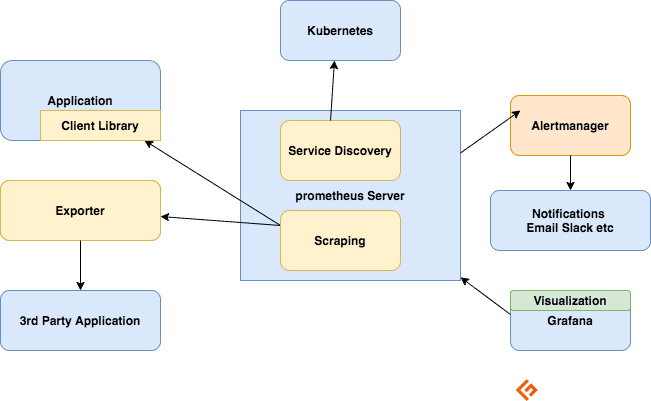
Il server Prometeo
Raccoglie le metriche, le archivia e le rende disponibili per l’interrogazione, invia avvisi in base alle metriche raccolte.
Raschiare
Prometeo è un sistema basato su pull. Per recuperare le metriche, Prometheus invia una richiesta HTTP chiamata scrape. Invia scraping alle destinazioni in base alla sua configurazione.
Ogni destinazione (definita staticamente o rilevata dinamicamente) viene raschiata a intervalli regolari (intervallo di raschiatura). Ogni scrape legge l’endpoint HTTP /metrics per ottenere lo stato corrente delle metriche del client e rende persistenti i valori nel database delle serie temporali Prometheus.
Esistono più database di serie temporali per il monitoraggio delle soluzioni che potresti voler esplorare.
Librerie clienti
Per monitorare un servizio, devi aggiungere la strumentazione al tuo codice. Sono disponibili librerie client per tutti i linguaggi e runtime più diffusi. Utilizzando queste librerie, una volta aggiunte alcune righe di codice, il tuo codice può iniziare a emettere metriche. Questo si chiama strumentazione diretta. Queste librerie consentono di definire metriche interne e di esporle anche tramite un endpoint HTTP. Quando Prometheus esegue lo scraping dell’endpoint HTTP delle metriche, la libreria client invia le metriche al server.
Le librerie client ufficiali sono offerte da Prometheus per Go, Java, Python e Ruby. Prometeo ha un ecosistema aperto. Sono inoltre disponibili librerie client create dalla comunità per C, PHP, Node.js, C#/.NET e molti altri.
Esportatori
Molte applicazioni espongono le metriche in formato non Prometheus. Per queste e per le applicazioni che non possiedi o per le quali non hai accesso al codice, non puoi aggiungere direttamente la strumentazione. Ad esempio, server MySQL, Kafka, JMX, HAProxy e NGINX. In questi scenari, fai uso di esportatori.
Un esportatore è uno strumento che distribuisci insieme all’applicazione da cui desideri le metriche. Un esportatore funge da proxy tra l’applicazione e Prometheus. Riceverà le richieste dal server Prometheus, raccoglierà i dati dai log di accesso, dai log degli errori dell’applicazione, li trasformerà nel formato corretto e infine tornerà al server Prometheus.
Alcuni degli esportatori popolari sono:
- finestre – per le metriche del server Windows
- Nodo – per le metriche del server Linux
- Scatola nera – per le metriche delle prestazioni del DNS e del sito web
- JMX – per le metriche delle applicazioni basate su Java
Una volta che le applicazioni sono state strumentate, o gli esportatori sono a posto, devi dire a Prometheus dove si trovano. Questo può essere fatto usando la configurazione statica. Nel caso di ambienti dinamici, questo non può essere fatto; pertanto viene utilizzato il rilevamento del servizio.
Allerta
Alerting with Prometheus si compone di due parti:
Le regole di avviso inviano avvisi all’Alertmanager.
Alertmanager gestisce quindi tali avvisi. Invia notifiche utilizzando molte integrazioni predefinite come e-mail, Slack, Hipchat e PagerDuty. L’Alertmanager può anche eseguire il silenziamento o l’aggregazione per ridurre il numero di notifiche.
Ecco la guida per monitorare il server Linux utilizzando Prometheus e Dashboard.
Visualizzazione con dashboard
Prometheus ha una serie di API che utilizzano le quali le query PromQL possono produrre dati grezzi per le visualizzazioni.
Sebbene Prometheus includa un browser di espressioni che può essere utilizzato per query ad hoc, lo strumento migliore disponibile è Grafana. Grafana si integra completamente con Prometheus e può produrre un’ampia varietà di cruscotti.
Sarà necessario configurare Prometheus come origine dati per Grafana.
Puoi aggiungere dashboard tramite:
- Importazione di dashboard creati dalla community
- Costruisci il tuo
- Utilizzando una dashboard predefinita.
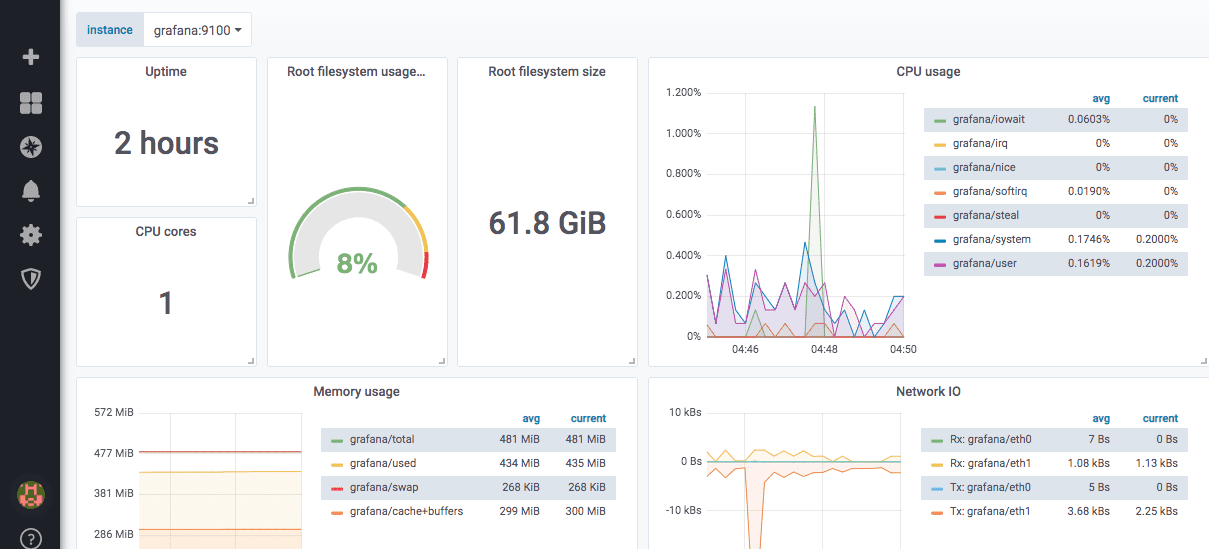
Ecco come appare una dashboard dell’esportatore di nodi predefiniti:
Grafana ha un modulo worldPing che ti consente di monitorare le metriche delle prestazioni del sito e del DNS in tutto il mondo.
Riepilogo
Prometeo ha pochissimi requisiti. Può essere abbastanza semplice da eseguire in quanto è un singolo binario con un file di configurazione. Può gestire migliaia di obiettivi e ingerire milioni di campioni al secondo. Prometheus è progettato per tenere traccia del sistema generale, della salute e del comportamento del sistema.
Grafana è il miglior strumento disponibile per la visualizzazione delle metriche e si integra perfettamente con Prometeo.