

Anni fa, quando i server Unix on-premise con file system di grandi dimensioni erano una cosa, le aziende stavano creando regole e strategie di gestione delle cartelle estese per amministrare i diritti di accesso a cartelle diverse per persone diverse.
Di solito, la piattaforma di un’organizzazione serve diversi gruppi di utenti con interessi completamente distinti, restrizioni sul livello di riservatezza o definizioni dei contenuti. Nel caso di organizzazioni globali, ciò potrebbe anche significare separare i contenuti in base alla posizione, quindi sostanzialmente, tra gli utenti appartenenti a paesi diversi.
Ulteriori esempi tipici potrebbero includere:
- separazione dei dati tra ambienti di sviluppo, test e produzione
- contenuti di vendita non accessibili a un vasto pubblico
- contenuti legislativi specifici per paese che non possono essere visualizzati o accessibili da un’altra regione
- contenuti relativi al progetto in cui i “dati sulla leadership” devono essere forniti solo a un gruppo limitato di persone, ecc.
Esiste un elenco potenzialmente infinito di tali esempi. Il punto è che c’è sempre una sorta di necessità di orchestrare i diritti di accesso a file e dati tra tutti gli utenti a cui la piattaforma fornisce l’accesso.
Nel caso di soluzioni on-premise, si trattava di un’attività di routine. L’amministratore del file system ha appena impostato alcune regole, utilizzato uno strumento di scelta, quindi le persone sono state mappate in gruppi di utenti e i gruppi di utenti sono stati mappati in un elenco di cartelle o punti di montaggio a cui potranno accedere. Lungo il percorso, il livello di accesso è stato definito come sola lettura o accesso in lettura e scrittura.
Ora esaminando le piattaforme cloud AWS, è ovvio aspettarsi che le persone abbiano requisiti simili per le restrizioni di accesso ai contenuti. La soluzione a questo problema deve essere, però, ora, diversa. I file non resistono più sui server Unix ma nel cloud (e potenzialmente accessibili non solo all’intera organizzazione ma anche al mondo intero), e il contenuto non viene archiviato in cartelle ma in bucket S3.

Di seguito è descritta un’alternativa per affrontare questo problema. Si basa sull’esperienza del mondo reale che ho avuto mentre stavo progettando tali soluzioni per un progetto concreto.
Sommario:
Approccio semplice ma ampiamente manuale
Un modo per risolvere questo problema senza alcuna automazione è relativamente diretto e semplice:
- Crea un nuovo bucket per ogni gruppo distinto di persone.
- Assegna i diritti di accesso al bucket in modo che solo questo gruppo specifico possa accedere al bucket S3.
Questo è certamente possibile se il requisito è quello di andare con una risoluzione molto semplice e veloce. Ci sono, tuttavia, alcuni limiti di cui essere consapevoli.
Per impostazione predefinita, è possibile creare solo fino a 100 bucket S3 in un account AWS. Questo limite può essere esteso a 1000 inviando un aumento del limite del servizio al ticket AWS. Se questi limiti non sono qualcosa di cui il tuo particolare caso di implementazione sarebbe preoccupato, puoi consentire a ciascuno dei tuoi utenti di dominio distinti di operare su un bucket S3 separato e chiamarlo un giorno.
I problemi potrebbero sorgere se ci sono alcuni gruppi di persone con responsabilità interfunzionali o semplicemente alcune persone che hanno bisogno di accedere al contenuto di più domini contemporaneamente. Per esempio:
- Analisti di dati che valutano il contenuto dei dati per diverse aree, regioni, ecc.
- Il team di test ha condiviso servizi al servizio di diversi team di sviluppo.
- Segnalazione degli utenti che richiedono di creare un’analisi del dashboard in diversi paesi all’interno della stessa regione.
Come puoi immaginare, questo elenco può crescere di nuovo quanto puoi immaginare e le esigenze delle organizzazioni possono generare tutti i tipi di casi d’uso.
Più complesso diventa questo elenco, più complessa sarà l’orchestrazione dei diritti di accesso necessaria per concedere a tutti quei diversi gruppi diversi diritti di accesso a diversi bucket S3 nell’organizzazione. Saranno necessari strumenti aggiuntivi e forse anche una risorsa dedicata (amministratore) dovrà mantenere gli elenchi dei diritti di accesso e aggiornarli ogni volta che viene richiesta una modifica (cosa che avverrà molto spesso, soprattutto se l’organizzazione è grande).
Allora, come ottenere la stessa cosa in modo più organizzato e automatizzato?
Se l’approccio bucket per dominio non funziona, qualsiasi altra soluzione finirà con bucket condivisi per più gruppi di utenti. In tali casi, è necessario costruire l’intera logica di assegnazione dei diritti di accesso in alcune aree facilmente modificabili o aggiornabili dinamicamente.
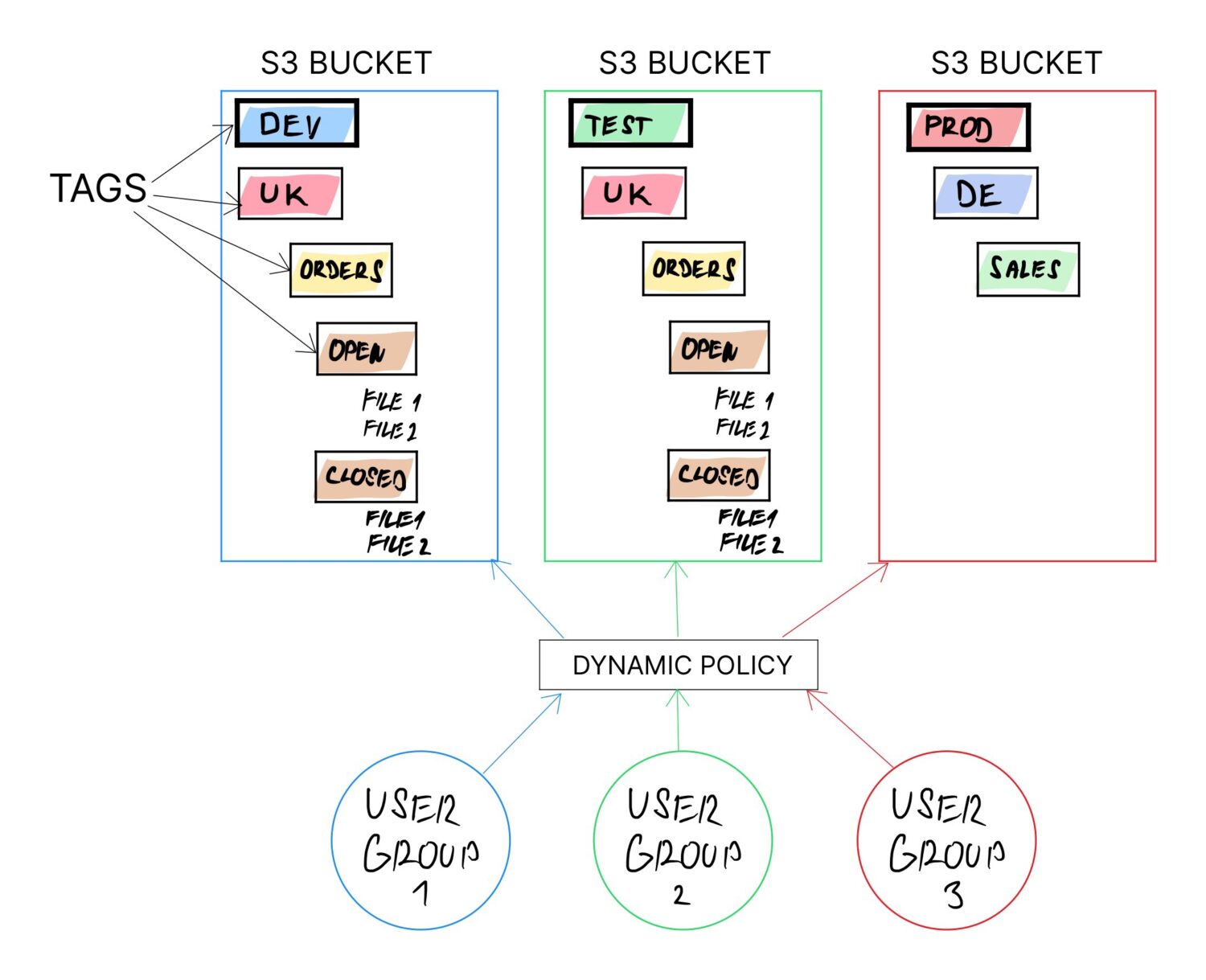
Uno dei modi per ottenere ciò è utilizzare i tag sui bucket S3. Si consiglia di utilizzare i tag in ogni caso (se non altro per consentire una più semplice categorizzazione della fatturazione). Tuttavia, il tag può essere modificato in qualsiasi momento in futuro per qualsiasi bucket.
Se l’intera logica è costruita sulla base dei tag del bucket e il resto dipende dalla configurazione dai valori del tag, la proprietà dinamica è assicurata in quanto è possibile ridefinire lo scopo del bucket semplicemente aggiornando i valori del tag.
Che tipo di tag usare per farlo funzionare?
Questo dipende dal tuo caso d’uso concreto. Per esempio:
- Può essere necessario separare i bucket per tipo di ambiente. Quindi, in tal caso, uno dei nomi dei tag deve essere qualcosa come “ENV” e con i possibili valori “DEV”, “TEST”, “PROD”, ecc.
- Forse vuoi separare la squadra in base al paese. In tal caso, un altro tag sarà “COUNTRY” e valorizzerà il nome di un paese.
- Oppure potresti voler separare gli utenti in base al dipartimento funzionale a cui appartengono, come analisti aziendali, utenti di data warehouse, data scientist, ecc. Quindi crei un tag con il nome “USER_TYPE” e il rispettivo valore.
- Un’altra opzione potrebbe essere quella di voler definire in modo esplicito una struttura di cartelle fissa per gruppi di utenti specifici che devono utilizzare (per non creare il proprio disordine di cartelle e perdersi lì nel tempo). Puoi farlo di nuovo con i tag, dove puoi specificare diverse directory di lavoro come: “data/import”, “data/processed”, “data/error”, ecc.
Idealmente, si desidera definire i tag in modo che possano essere combinati logicamente e farli formare un’intera struttura di cartelle nel bucket.
Ad esempio, puoi combinare i seguenti tag dagli esempi precedenti per costruire una struttura di cartelle dedicata per diversi tipi di utenti di vari paesi con cartelle di importazione predefinite che dovrebbero utilizzare:
- /
/ / /
Semplicemente modificando il valore
Ciò consentirà l’utilizzo dello stesso bucket per molti utenti diversi. I bucket non supportano esplicitamente le cartelle, ma supportano le “etichette”. Queste etichette alla fine funzionano come sottocartelle perché gli utenti devono passare attraverso una serie di etichette per raggiungere i propri dati (proprio come farebbero con le sottocartelle).
Dopo aver definito i tag in una forma utilizzabile, il passaggio successivo consiste nel creare policy di bucket S3 che utilizzino i tag.
Se le politiche utilizzano i nomi dei tag, stai creando qualcosa chiamato “politiche dinamiche”. Ciò significa sostanzialmente che la tua politica si comporterà in modo diverso per i bucket con valori di tag diversi a cui fa riferimento la politica in forma o segnaposto.
Questo passaggio comporta ovviamente una codifica personalizzata delle policy dinamiche, ma puoi semplificare questo passaggio utilizzando lo strumento dell’editor di policy di Amazon AWS, che ti guiderà attraverso il processo.
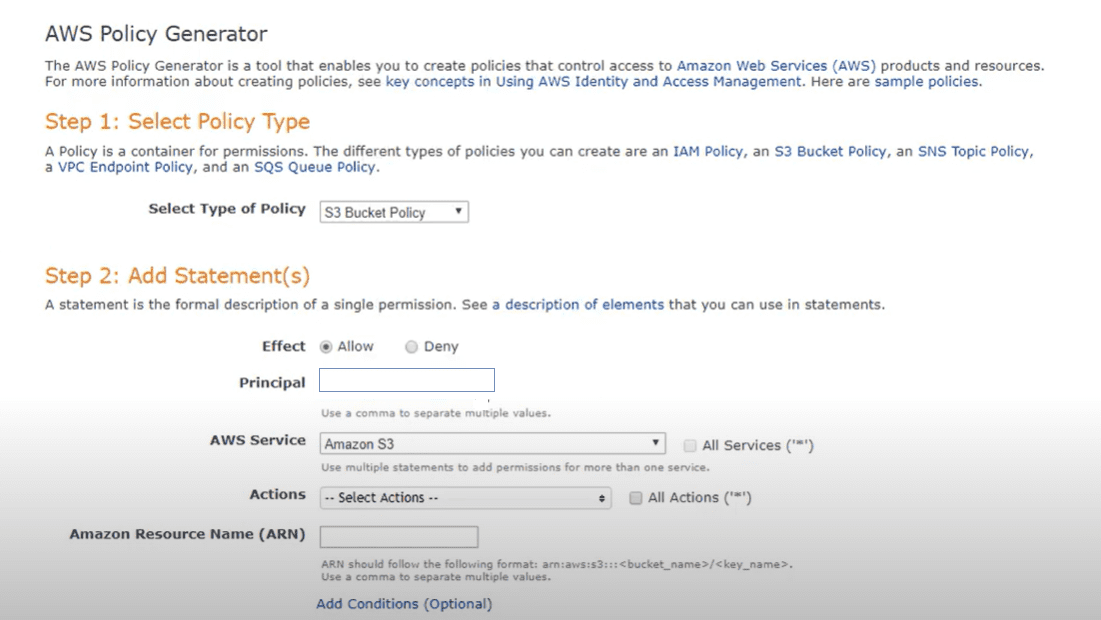
Nella policy stessa, dovrai codificare i diritti di accesso concreti che verranno applicati al bucket e il livello di accesso di tali diritti (lettura, scrittura). La logica leggerà i tag sui bucket e costruirà la struttura delle cartelle sul bucket (creando etichette basate sui tag). Sulla base dei valori concreti dei tag verranno create le sottocartelle e lungo la linea verranno assegnati i diritti di accesso richiesti.
La cosa bella di una policy così dinamica è che puoi creare solo una policy dinamica e quindi assegnare la stessa policy dinamica a molti bucket. Questa policy si comporterà in modo diverso per i bucket con valori di tag diversi, ma sarà sempre conforme alle tue aspettative per un bucket con tali valori di tag.
È un modo davvero efficace per gestire le assegnazioni dei diritti di accesso in modo organizzato e centralizzato per un numero elevato di bucket, in cui è previsto che ogni bucket segua alcune strutture modello concordate in anticipo e che verranno utilizzate dagli utenti all’interno l’intera organizzazione.
Automatizza l’onboarding di nuove entità
Dopo aver definito le policy dinamiche e averle assegnate ai bucket esistenti, gli utenti possono iniziare a utilizzare gli stessi bucket senza il rischio che utenti di gruppi diversi non accedano ai contenuti (archiviati nello stesso bucket) situati in una struttura di cartelle in cui non hanno accesso.
Inoltre, per alcuni gruppi di utenti con un accesso più ampio, sarà facile raggiungere i dati perché saranno tutti archiviati nello stesso bucket.
Il passaggio finale consiste nel semplificare il più possibile l’onboarding di nuovi utenti, nuovi bucket e persino nuovi tag. Ciò ha portato a un’altra codifica personalizzata, che, tuttavia, non deve essere eccessivamente complessa, assumendo che il tuo processo di onboarding abbia alcune regole molto chiare che possono essere incapsulate con una logica di algoritmo semplice e diretta (almeno puoi dimostrare in questo modo che il tuo processo ha una certa logica e non è fatto in modo eccessivamente caotico).
Questo può essere semplice come creare uno script eseguibile dal comando AWS CLI con i parametri necessari per eseguire correttamente l’onboarding di una nuova entità nella piattaforma. Può anche essere una serie di script CLI, eseguibili in un ordine specifico, come, ad esempio:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - eccetera.
Hai capito il punto. 😃
Un consiglio da professionista 👨💻
C’è un suggerimento professionale, se lo desideri, che può essere facilmente applicato in aggiunta a quanto sopra.
Le policy dinamiche possono essere sfruttate non solo per assegnare i diritti di accesso per le posizioni delle cartelle, ma anche per assegnare automaticamente i diritti di servizio per i bucket e i gruppi di utenti!
Tutto ciò che sarebbe necessario è estendere l’elenco dei tag sui bucket e quindi aggiungere i diritti di accesso ai criteri dinamici per utilizzare servizi specifici per gruppi concreti di utenti.
Ad esempio, potrebbe esserci un gruppo di utenti che necessita anche dell’accesso allo specifico server del cluster di database. Ciò può essere indubbiamente ottenuto da policy dinamiche che sfruttano le attività del bucket, tanto più se gli accessi ai servizi sono guidati da un approccio basato sui ruoli. Basta aggiungere al codice della politica dinamica una parte che elaborerà i tag relativi alla specifica del cluster di database e assegnerà direttamente i privilegi di accesso alla politica a quel particolare cluster di database e gruppo di utenti.
In questo modo, l’onboarding di un nuovo gruppo di utenti sarà eseguibile solo da questa singola policy dinamica. Inoltre, poiché è dinamico, la stessa policy può essere riutilizzata per l’onboarding di molti gruppi di utenti diversi (che dovrebbero seguire lo stesso modello ma non necessariamente gli stessi servizi).
Puoi anche dare un’occhiata a questi comandi AWS S3 per gestire bucket e dati.