
La scienza dei dati è per chiunque ami svelare cose intricate e scoprire meraviglie nascoste in un apparente pasticcio.
È come cercare aghi nei pagliai; solo che i data scientist non hanno affatto bisogno di sporcarsi le mani. Utilizzando strumenti fantasiosi con grafici colorati e guardando pile di numeri, si tuffano nei pagliai di dati e trovano preziosi aghi sotto forma di intuizioni di alto valore aziendale.
Un tipico scienziato dei dati toolbox dovrebbe includere almeno un elemento di ciascuna di queste categorie: database relazionali, database NoSQL, framework di big data, strumenti di visualizzazione, strumenti di scraping, linguaggi di programmazione, IDE e strumenti di deep learning.
Sommario:
Banche dati relazionali
Un database relazionale è una raccolta di dati strutturata in tabelle con attributi. Le tabelle possono essere collegate tra loro, definendo relazioni e restrizioni e creando quello che viene chiamato un modello di dati. Per lavorare con i database relazionali, si usa comunemente un linguaggio chiamato SQL (Structured Query Language).
Le applicazioni che gestiscono la struttura ei dati nei database relazionali sono denominate RDBMS (Relational DataBase Management Systems). Esistono molte di queste applicazioni e le più rilevanti hanno recentemente iniziato a concentrarsi sul campo della scienza dei dati, aggiungendo funzionalità per lavorare con repository di big data e per applicare tecniche come l’analisi dei dati e l’apprendimento automatico.
server SQL
RDBMS di Microsoft, si è evoluto per oltre 20 anni espandendo costantemente le sue funzionalità aziendali. Dalla sua versione 2016, SQL Server offre un portafoglio di servizi che include il supporto per il codice R incorporato. SQL Server 2017 aumenta la scommessa rinominando i suoi R Services in Machine Language Services e aggiungendo il supporto per il linguaggio Python (ulteriori informazioni su questi due linguaggi di seguito).
Con queste importanti aggiunte, SQL Server si rivolge ai data scientist che potrebbero non avere esperienza con Transact SQL, il linguaggio di query nativo di Microsoft SQL Server.
SQL Server è ben lungi dall’essere un prodotto gratuito. Puoi acquistare le licenze per installarlo su un Server Windows (il prezzo varierà in base al numero di utenti concorrenti) o utilizzarlo come servizio a pagamento, tramite il cloud di Microsoft Azure. Imparare Microsoft SQL Server è facile.
MySQL
Dal lato del software open source, MySQL ha la corona di popolarità degli RDBMS. Sebbene Oracle attualmente lo possieda, è ancora gratuito e open source secondo i termini di una GNU General Public License. La maggior parte delle applicazioni basate sul Web utilizza MySQL come repository di dati sottostante, grazie alla sua conformità allo standard SQL.
Aiutano anche alla sua popolarità le sue facili procedure di installazione, la sua grande comunità di sviluppatori, tonnellate di documentazione completa e strumenti di terze parti, come phpMyAdmin, che semplificano le attività di gestione quotidiana. Sebbene MySQL non abbia funzioni native per eseguire l’analisi dei dati, la sua apertura ne consente l’integrazione con quasi tutti gli strumenti di visualizzazione, reporting e business intelligence che puoi scegliere.
PostgreSQL
Un’altra opzione RDBMS open source è PostgreSQL. Sebbene non sia così popolare come MySQL, PostgreSQL si distingue per la sua flessibilità ed estensibilità e il suo supporto per query complesse, quelle che vanno oltre le istruzioni di base come SELECT, WHERE e GROUP BY.
Queste caratteristiche gli stanno facendo guadagnare popolarità tra i data scientist. Un’altra caratteristica interessante è il supporto per multi-ambienti, che ne consente l’utilizzo in ambienti cloud e on-premise, o in un mix di entrambi, comunemente noti come ambienti cloud ibridi.
PostgreSQL è in grado di combinare l’elaborazione analitica online (OLAP) con l’elaborazione delle transazioni online (OLTP), lavorando in una modalità chiamata elaborazione ibrida transazionale/analitica (HTAP). È anche adatto per lavorare con i big data, grazie all’aggiunta di PostGIS per i dati geografici e JSON-B per i documenti. PostgreSQL supporta anche i dati non strutturati, che gli consentono di essere in entrambe le categorie: database SQL e NoSQL.
Database NoSQL
Conosciuti anche come database non relazionali, questo tipo di repository di dati fornisce un accesso più rapido alle strutture di dati non tabulari. Alcuni esempi di queste strutture sono grafici, documenti, colonne larghe, valori chiave, tra molti altri. Gli archivi dati NoSQL possono mettere da parte la coerenza dei dati a favore di altri vantaggi, come disponibilità, partizionamento e velocità di accesso.
Poiché non esiste SQL negli archivi dati NoSQL, l’unico modo per eseguire query su questo tipo di database è utilizzare linguaggi di basso livello e non esiste un linguaggio di questo tipo ampiamente accettato come SQL. Inoltre, non ci sono specifiche standard per NoSQL. Ecco perché, ironia della sorte, alcuni database NoSQL stanno iniziando ad aggiungere il supporto per gli script SQL.
MongoDB
MongoDB è un popolare sistema di database NoSQL, che archivia i dati sotto forma di documenti JSON. Il suo obiettivo è la scalabilità e la flessibilità di archiviare i dati in modo non strutturato. Ciò significa che non esiste un elenco di campi fissi da osservare in tutti gli elementi memorizzati. Inoltre, la struttura dei dati può essere modificata nel tempo, cosa che in un database relazionale implica un alto rischio di influire sulle applicazioni in esecuzione.

La tecnologia in MongoDB consente indicizzazione, query ad hoc e aggregazione che forniscono una solida base per l’analisi dei dati. La natura distribuita del database fornisce disponibilità elevata, scalabilità e distribuzione geografica senza la necessità di strumenti sofisticati.
Redis
Questo uno è un’altra opzione nel fronte open-source, NoSQL. È fondamentalmente un archivio di strutture dati che opera in memoria e, oltre a fornire servizi di database, funge anche da memoria cache e broker di messaggi.

Supporta una miriade di strutture di dati non convenzionali, inclusi hash, indici geospaziali, elenchi e set ordinati. È adatto per la scienza dei dati grazie alle sue elevate prestazioni in attività ad alta intensità di dati, come il calcolo di intersezioni di set, l’ordinamento di lunghi elenchi o la generazione di classifiche complesse. Il motivo delle eccezionali prestazioni di Redis è il suo funzionamento in memoria. Può essere configurato per mantenere i dati in modo selettivo.
Quadri di Big Data
Supponiamo di dover analizzare i dati generati dagli utenti di Facebook durante un mese. Stiamo parlando di foto, video, messaggi, tutto. Tenendo conto che ogni giorno vengono aggiunti più di 500 terabyte di dati dai suoi utenti al social network, è difficile misurare il volume rappresentato da un intero mese dei suoi dati.
Per manipolare questa enorme quantità di dati in modo efficace, è necessario un framework appropriato in grado di calcolare le statistiche su un’architettura distribuita. Ci sono due dei framework che guidano il mercato: Hadoop e Spark.
Hadoop
Come struttura di big data, Hadoop si occupa delle complessità associate al recupero, all’elaborazione e all’archiviazione di enormi pile di dati. Hadoop opera in un ambiente distribuito, composto da cluster di computer che elaborano semplici algoritmi. Esiste un algoritmo di orchestrazione, chiamato MapReduce, che divide le attività grandi in piccole parti e quindi le distribuisce tra i cluster disponibili.

Hadoop è consigliato per repository di dati di classe enterprise che richiedono un accesso rapido e un’elevata disponibilità, il tutto in uno schema a basso costo. Ma hai bisogno di un amministratore Linux con deep Conoscenza Hadoop per mantenere il framework attivo e funzionante.
Scintilla
Hadoop non è l’unico framework disponibile per la manipolazione dei big data. Un altro grande nome in questo settore è Scintilla. Il motore Spark è stato progettato per superare Hadoop in termini di velocità di analisi e facilità d’uso. Apparentemente, ha raggiunto questo obiettivo: alcuni confronti affermano che Spark funziona fino a 10 volte più velocemente di Hadoop quando lavora su un disco e 100 volte più veloce operando in memoria. Richiede anche un numero minore di macchine per elaborare la stessa quantità di dati.

Oltre alla velocità, un altro vantaggio di Spark è il supporto per l’elaborazione del flusso. Questo tipo di elaborazione dei dati, detta anche elaborazione in tempo reale, comporta un input e un output continui di dati.
Strumenti di visualizzazione
Una barzelletta comune tra i data scientist dice che, se torturi i dati abbastanza a lungo, confesserà ciò che devi sapere. In questo caso, “tortura” significa manipolare i dati trasformandoli e filtrandoli, in modo da visualizzarli al meglio. Ed è qui che entrano in scena gli strumenti di visualizzazione dei dati. Questi strumenti raccolgono dati preelaborati da più fonti e mostrano le verità rivelate in forme grafiche e comprensibili.
Ci sono centinaia di strumenti che rientrano in questa categoria. Piaccia o no, il più utilizzato è Microsoft Excel e i suoi strumenti grafici. I grafici di Excel sono accessibili a chiunque utilizzi Excel, ma hanno funzionalità limitate. Lo stesso vale per altre applicazioni per fogli di lavoro, come Fogli Google e Libre Office. Ma stiamo parlando di strumenti più specifici, appositamente studiati per la business intelligence (BI) e l’analisi dei dati.
Power BI
Non molto tempo fa, Microsoft ha rilasciato il suo Power BI applicazione di visualizzazione. Può prendere dati da diverse fonti, come file di testo, database, fogli di calcolo e molti servizi di dati online, inclusi Facebook e Twitter, e utilizzarli per generare dashboard pieni di grafici, tabelle, mappe e molti altri oggetti di visualizzazione. Gli oggetti dashboard sono interattivi, il che significa che puoi fare clic su una serie di dati in un grafico per selezionarla e utilizzarla come filtro per gli altri oggetti sulla lavagna.
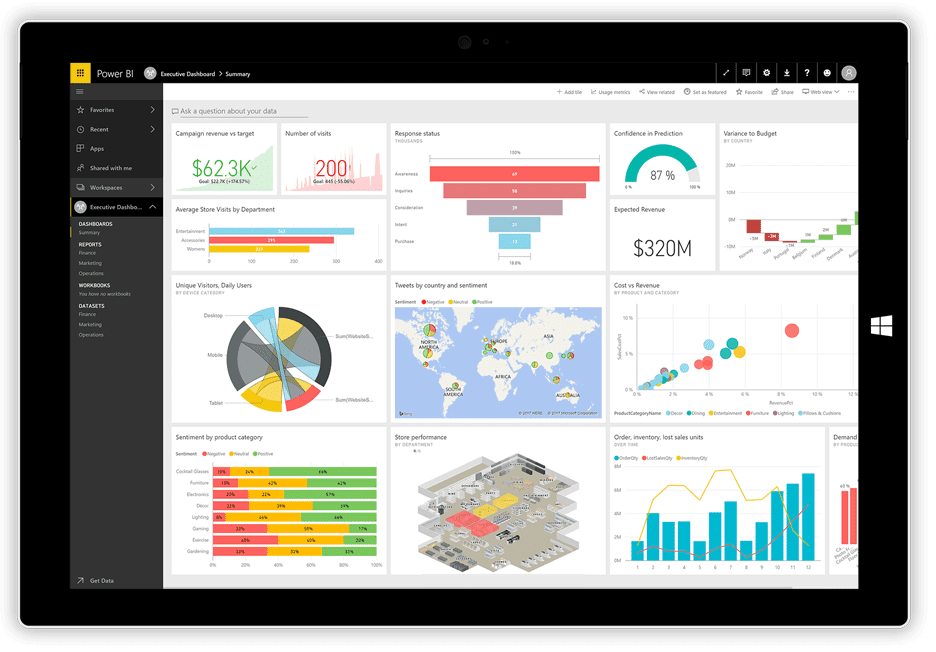
Power BI è una combinazione di un’applicazione desktop Windows (parte della suite Office 365), un’applicazione Web e un servizio online per pubblicare i dashboard sul Web e condividerli con gli utenti. Il servizio consente di creare e gestire i permessi per concedere l’accesso alle bacheche solo a determinate persone.
Tavolo
Tavolo è un’altra opzione per creare dashboard interattivi da una combinazione di più origini dati. Offre anche una versione desktop, una versione web e un servizio online per condividere i dashboard che crei. Funziona naturalmente “con il tuo modo di pensare” (come afferma) ed è facile da usare per le persone non tecniche, che viene migliorato attraverso molti tutorial e video online.
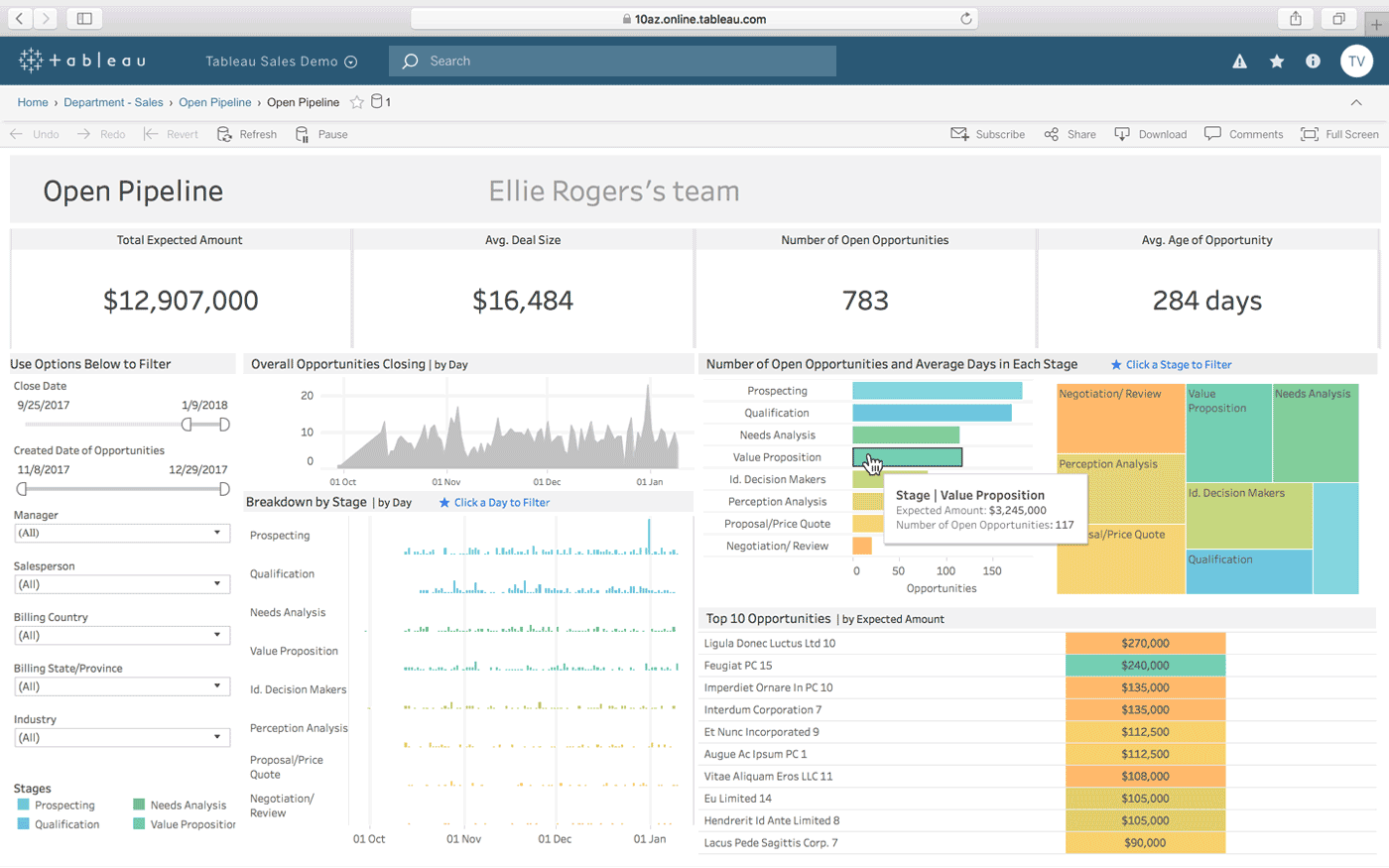
Alcune delle caratteristiche più straordinarie di Tableau sono i connettori dati illimitati, i dati in tempo reale e in memoria e il design ottimizzato per dispositivi mobili.
QlikView
QlikView offre un’interfaccia utente semplice e pulita per aiutare gli analisti a scoprire nuove informazioni dai dati esistenti attraverso elementi visivi facilmente comprensibili per tutti.
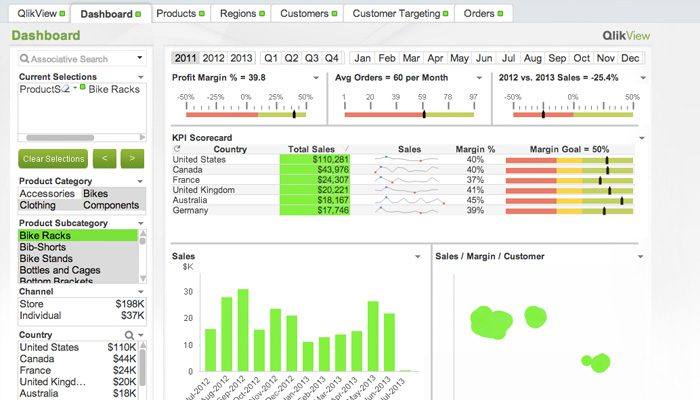
Questo strumento è noto per essere una delle piattaforme di business intelligence più flessibili. Fornisce una funzione chiamata Ricerca associativa, che ti aiuta a concentrarti sui dati più importanti, risparmiandoti il tempo necessario per trovarli da solo.
Con QlikView puoi collaborare con i partner in tempo reale, effettuando analisi comparative. Tutti i dati pertinenti possono essere combinati in un’unica app, con funzionalità di sicurezza che limitano l’accesso ai dati.
Strumenti per raschiare
Nei tempi in cui Internet stava appena emergendo, i web crawler hanno iniziato a viaggiare insieme alle reti raccogliendo informazioni sulla loro strada. Con l’evoluzione della tecnologia, il termine web crawling è cambiato in web scraping, ma ha sempre lo stesso significato: estrarre automaticamente informazioni dai siti web. Per fare il web scraping si utilizzano processi automatizzati, o bot, che saltano da una pagina web all’altra, estraendo dati da essa ed esportandoli in formati diversi o inserendoli nei database per ulteriori analisi.
Di seguito riassumiamo le caratteristiche di tre dei più popolari web scraper oggi disponibili.
Octoparse
Octoparse web scraper offre alcune caratteristiche interessanti, inclusi strumenti integrati per ottenere informazioni da siti Web che non facilitano lo svolgimento del loro lavoro da parte dei robot di scraping. È un’applicazione desktop che non richiede codifica, con un’interfaccia utente intuitiva che consente di visualizzare il processo di estrazione tramite un designer grafico del flusso di lavoro.
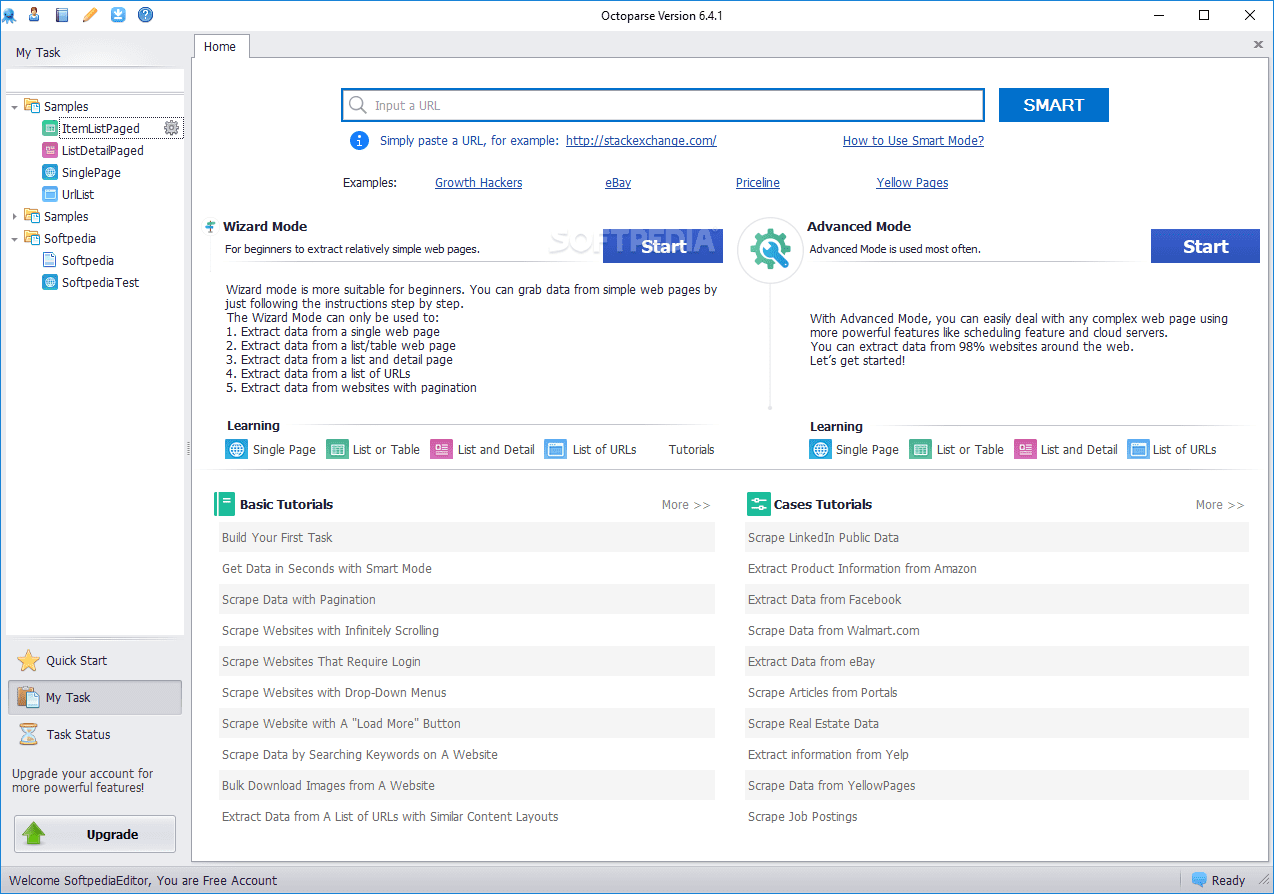
Insieme all’applicazione standalone, Octparse offre un servizio basato su cloud per accelerare il processo di estrazione dei dati. Gli utenti possono sperimentare un aumento di velocità da 4x a 10x quando utilizzano il servizio cloud anziché l’applicazione desktop. Se ti attieni alla versione desktop, puoi utilizzare Octparse gratuitamente. Ma se preferisci utilizzare il servizio cloud, dovrai scegliere uno dei suoi piani a pagamento.
Content Grabber
Se stai cercando uno strumento di scraping ricco di funzionalità, dovresti prestare attenzione Content Grabber. A differenza di Octparse, per utilizzare Content Grabber è necessario avere competenze di programmazione avanzate. In cambio, ottieni la modifica degli script, le interfacce di debug e altre funzionalità avanzate. Con Content Grabber, puoi usare i linguaggi .Net per scrivere espressioni regolari. In questo modo, non è necessario generare le espressioni utilizzando uno strumento integrato.
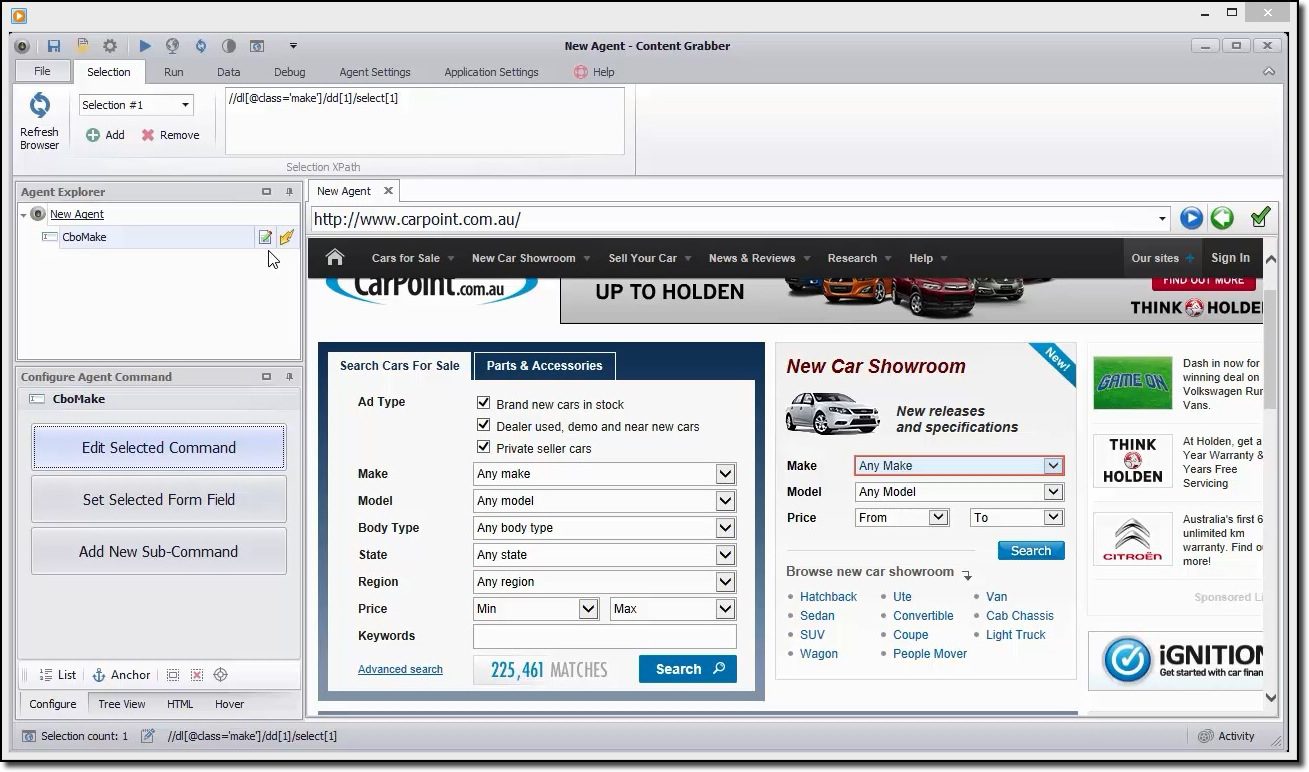
Lo strumento offre un’API (Application Programming Interface) che puoi utilizzare per aggiungere funzionalità di scraping alle tue applicazioni desktop e web. Per utilizzare questa API, gli sviluppatori devono ottenere l’accesso al servizio Windows Content Grabber.
ParseHub
Questo raschietto può gestire un elenco completo di diversi tipi di contenuto, inclusi forum, commenti nidificati, calendari e mappe. Può anche gestire pagine che contengono autenticazione, Javascript, Ajax e altro. ParseHub può essere utilizzato come un’app Web o un’applicazione desktop in grado di essere eseguita su Windows, macOS X e Linux.
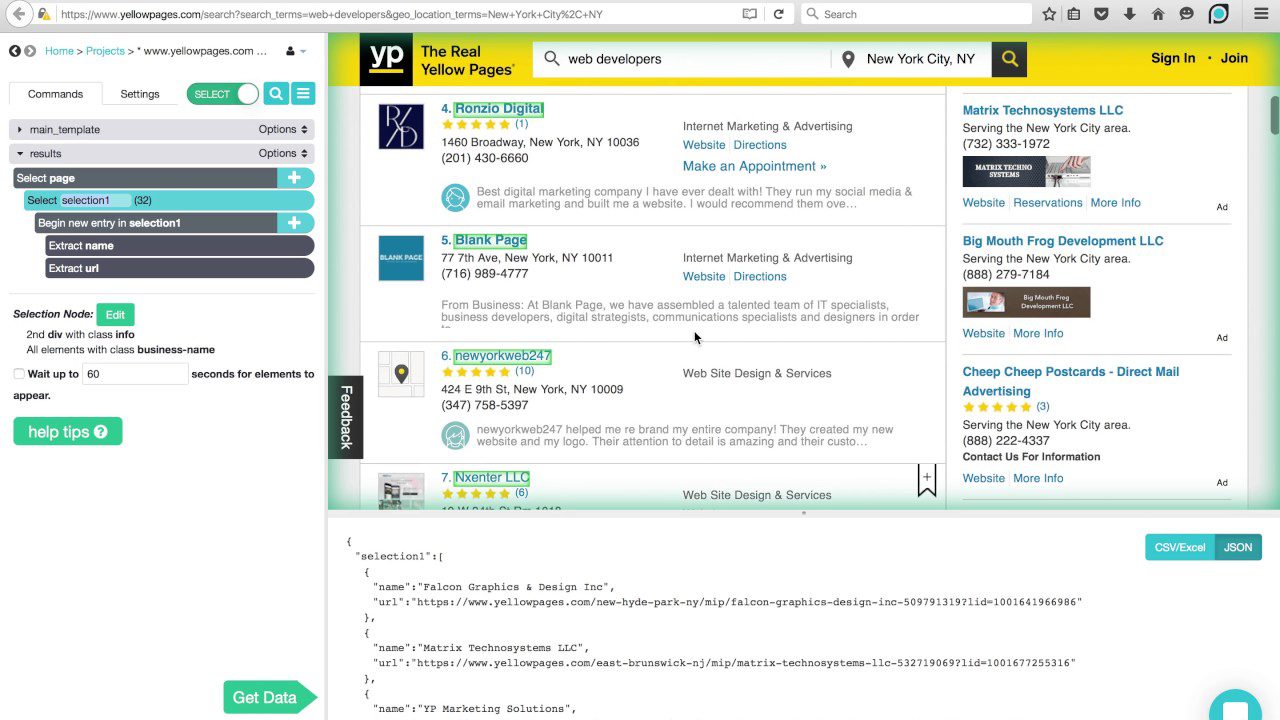
Come Content Grabber, si consiglia di avere alcune conoscenze di programmazione per ottenere il massimo da ParseHub. Ha una versione gratuita, limitata a 5 progetti e 200 pagine per esecuzione.
Linguaggi di programmazione
Proprio come il linguaggio SQL menzionato in precedenza è progettato specificamente per funzionare con i database relazionali, ci sono altri linguaggi creati con una chiara attenzione alla scienza dei dati. Questi linguaggi consentono agli sviluppatori di scrivere programmi che si occupano di analisi di dati di massa, come statistiche e apprendimento automatico.
SQL è anche considerata un’abilità importante che gli sviluppatori dovrebbero avere per fare scienza dei dati, ma questo perché la maggior parte delle organizzazioni ha ancora molti dati sui database relazionali. I “veri” linguaggi di scienza dei dati sono R e Python.
Pitone

Pitone è un linguaggio di programmazione di alto livello, interpretato e generico, adatto per lo sviluppo rapido di applicazioni. Ha una sintassi semplice e facile da imparare che consente una curva di apprendimento ripida e una riduzione dei costi di manutenzione del programma. Ci sono molte ragioni per cui è il linguaggio preferito per la scienza dei dati. Per citarne alcuni: potenziale di scripting, verbosità, portabilità e prestazioni.
Questo linguaggio è un buon punto di partenza per i data scientist che intendono sperimentare molto prima di lanciarsi nel duro lavoro di elaborazione dei dati e che desiderano sviluppare applicazioni complete.
R
Il Linguaggio R viene utilizzato principalmente per l’elaborazione di dati statistici e la rappresentazione grafica. Sebbene non sia pensato per sviluppare applicazioni a tutti gli effetti, come sarebbe il caso di Python, R è diventato molto popolare negli ultimi anni grazie al suo potenziale per il data mining e l’analisi dei dati.

Grazie a una libreria in continua crescita di pacchetti disponibili gratuitamente che ne estendono le funzionalità, R è in grado di eseguire tutti i tipi di lavoro di elaborazione dei dati, inclusi modellazione lineare/non lineare, classificazione, test statistici, ecc.
Non è una lingua facile da imparare, ma una volta che avrai familiarizzato con la sua filosofia, farai calcoli statistici come un professionista.
IDE
Se stai seriamente pensando di dedicarti alla scienza dei dati, dovrai scegliere con cura un ambiente di sviluppo integrato (IDE) adatto alle tue esigenze, perché tu e il tuo IDE trascorrerai molto tempo a lavorare insieme.
Un IDE ideale dovrebbe mettere insieme tutti gli strumenti di cui hai bisogno nel tuo lavoro quotidiano come programmatore: un editor di testo con evidenziazione della sintassi e completamento automatico, un potente debugger, un browser di oggetti e un facile accesso a strumenti esterni. Inoltre, deve essere compatibile con la lingua che preferisci, quindi è una buona idea scegliere il tuo IDE dopo aver saputo quale lingua utilizzerai.
Spyder
Questo L’IDE generico è destinato principalmente a scienziati e analisti che devono anche programmare. Per renderli comodi, non si limita alla funzionalità IDE, ma fornisce anche strumenti per l’esplorazione/visualizzazione dei dati e l’esecuzione interattiva, come si potrebbe trovare su un pacchetto scientifico. L’editor in Spyder supporta più lingue e aggiunge un browser di classe, divisione delle finestre, passaggio alla definizione, completamento automatico del codice e persino uno strumento di analisi del codice.
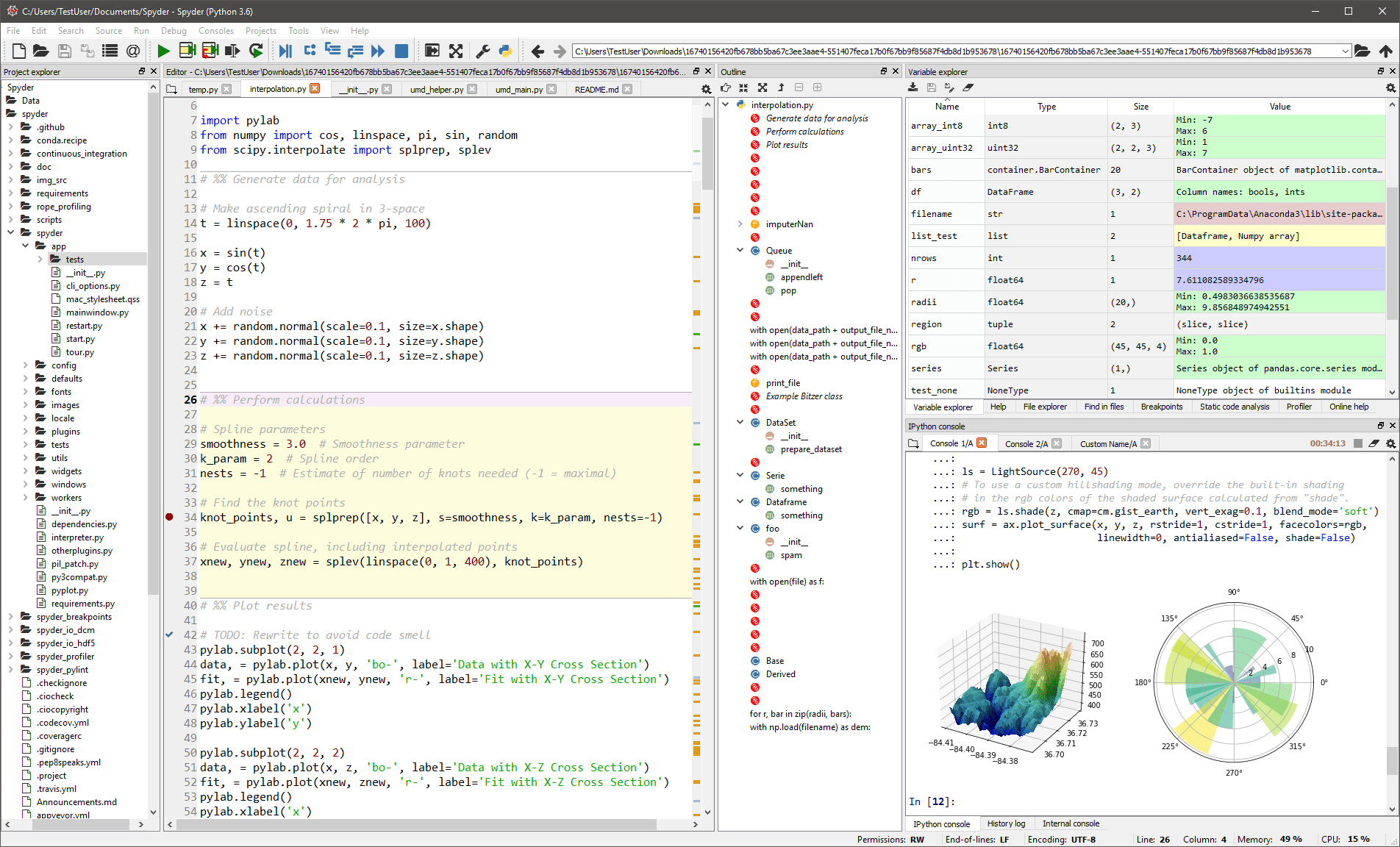
Il debugger ti aiuta a tracciare ogni riga di codice in modo interattivo e un profiler ti aiuta a trovare ed eliminare le inefficienze.
PyCharm
Se programmi in Python, è probabile che lo sia il tuo IDE preferito PyCharm. Ha un editor di codice intelligente con ricerca intelligente, completamento del codice e rilevamento e correzione degli errori. Con un solo clic, puoi passare dall’editor di codice a qualsiasi finestra relativa al contesto, inclusi test, super metodo, implementazione, dichiarazione e altro. PyCharm supporta Anaconda e molti pacchetti scientifici, come NumPy e Matplotlib, solo per citarne due.
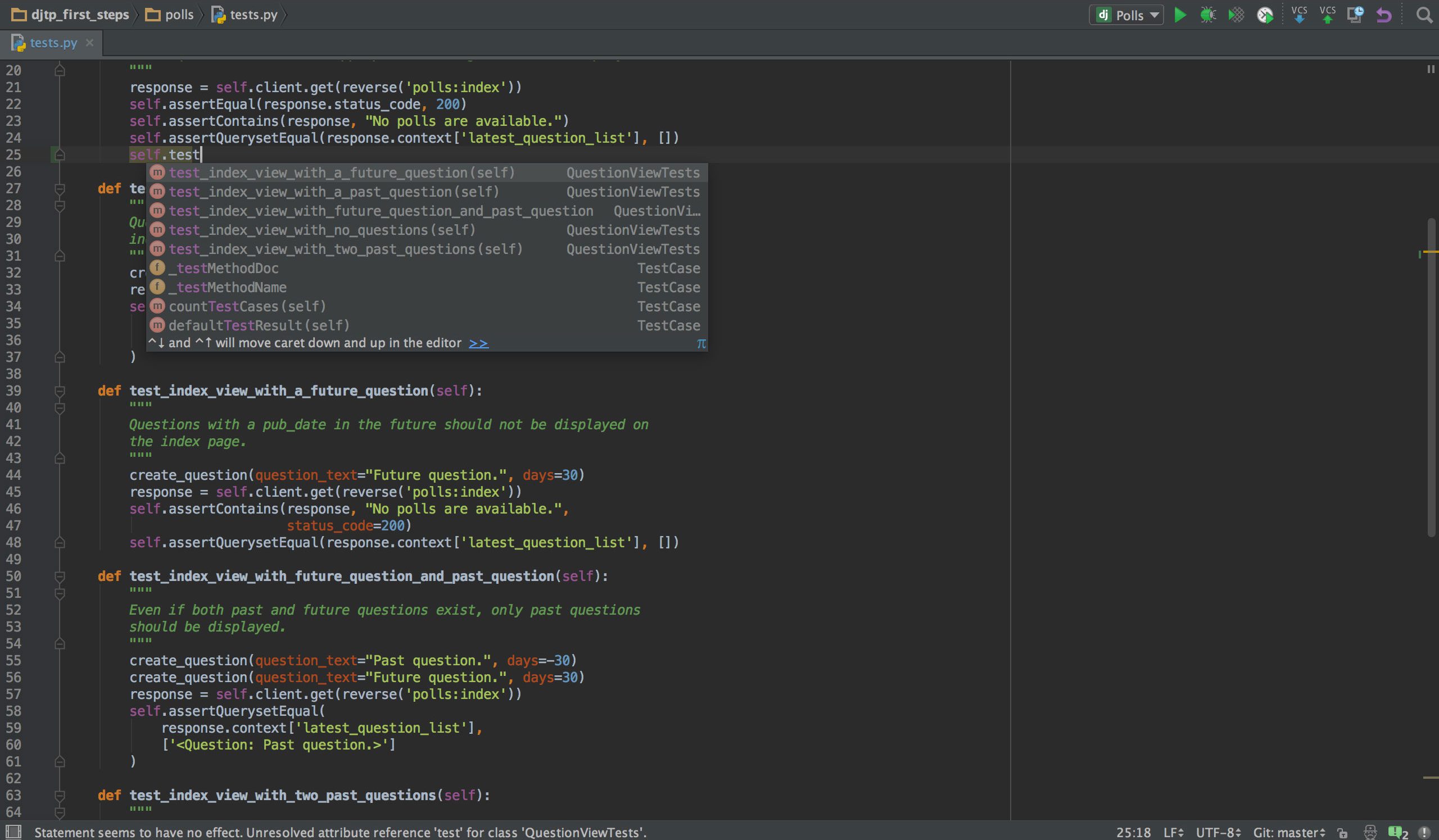
Offre integrazione con i più importanti sistemi di controllo delle versioni, e anche con un test runner, un profiler e un debugger. Per concludere l’accordo, si integra anche con Docker e Vagrant per fornire lo sviluppo e la containerizzazione multipiattaforma.
RStudio
Per quei data scientist che preferiscono il team R, l’IDE preferito dovrebbe essere RStudio, a causa delle sue numerose funzionalità. Puoi installarlo su un desktop con Windows, macOS o Linux oppure eseguirlo da un browser web se non vuoi installarlo localmente. Entrambe le versioni offrono chicche come l’evidenziazione della sintassi, l’indentazione intelligente e il completamento del codice. C’è un visualizzatore di dati integrato che è utile quando devi sfogliare i dati tabulari.
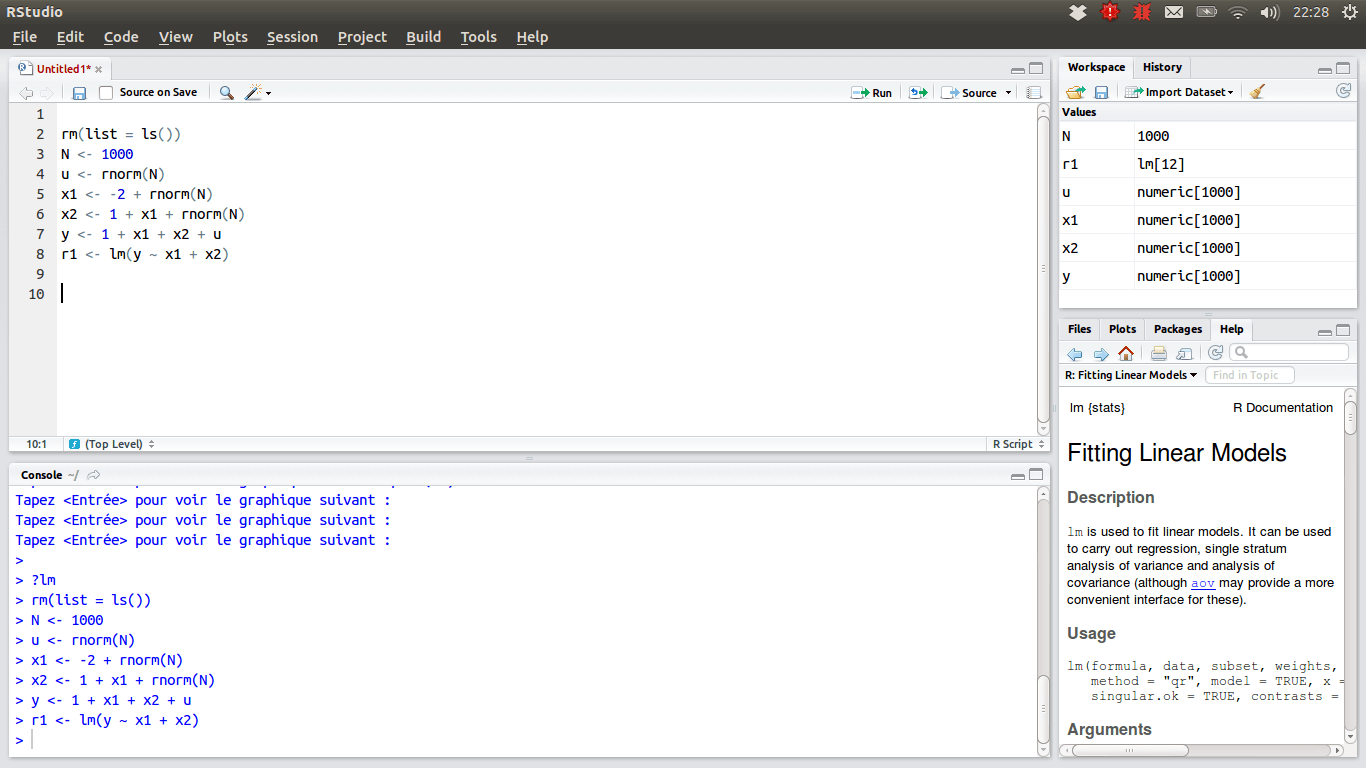
La modalità di debug consente di visualizzare passo passo come vengono aggiornati i dati durante l’esecuzione di un programma o di uno script. Per il controllo della versione, RStudio integra il supporto per SVN e Git. Un bel vantaggio è la possibilità di creare grafica interattiva, con Shiny e fornisce librerie.
La tua cassetta degli attrezzi personale
A questo punto, dovresti avere una visione completa degli strumenti che dovresti conoscere per eccellere nella scienza dei dati. Inoltre, speriamo di averti fornito informazioni sufficienti per decidere quale sia l’opzione più conveniente all’interno di ciascuna categoria di strumenti. Ora tocca a te. La scienza dei dati è un campo fiorente sviluppare una carriera. Ma se vuoi farlo, devi stare al passo con i cambiamenti delle tendenze e delle tecnologie, poiché si verificano quasi quotidianamente.